A hypervisor or virtual machine monitor (VMM) is computer software, firmware or hardware that creates and runs virtual machines. A computer on which a hypervisor runs one or more virtual machines is called a host machine, and each virtual machine is called a guest machine. The hypervisor presents the guest operating systems with a virtual operating platform and manages the execution of the guest operating systems. Multiple instances of a variety of operating systems may share the virtualized hardware resources: for example, Linux, Windows, and macOS instances can all run on a single physical x86 machine. This contrasts with operating-system-level virtualization, where all instances (usually called containers) must share a single kernel, though the guest operating systems can differ in user space, such as different Linux distributions with the same kernel.
The term hypervisor is a variant of supervisor, a traditional term for the kernel of an operating system: the hypervisor is the supervisor of the supervisor,[1] with hyper- used as a stronger variant of super-.[a] The term dates to circa 1970;[2] in the earlier CP/CMS (1967) system the term Control Program was used instead.

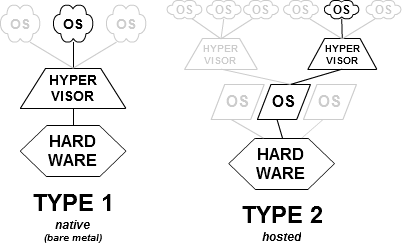
Type-1 and type-2 hypervisors
In their 1974 article, Formal Requirements for Virtualizable Third Generation Architectures, Gerald J. Popek and Robert P. Goldberg classified two types of hypervisor:[3]
- Type-1, native or bare-metal hypervisors
- These hypervisors run directly on the host's hardware to control the hardware and to manage guest operating systems. For this reason, they are sometimes called bare metal hypervisors. The first hypervisors, which IBM developed in the 1960s, were native hypervisors.[4] These included the test software SIMMON and the CP/CMS operating system (the predecessor of IBM's z/VM). Modern equivalents include Xen, Oracle VM Server for SPARC, Oracle VM Server for x86, Microsoft Hyper-V and VMware ESX/ESXi.
- Type-2 or hosted hypervisors
- These hypervisors run on a conventional operating system (OS) just as other computer programs do. A guest operating system runs as a process on the host. Type-2 hypervisors abstract guest operating systems from the host operating system. VMware Workstation, VMware Player, VirtualBox, Parallels Desktop for Mac and QEMU are examples of type-2 hypervisors.
The distinction between these two types is not necessarily clear. Linux's Kernel-based Virtual Machine (KVM) and FreeBSD's bhyve are kernel modules[5] that effectively convert the host operating system to a type-1 hypervisor.[6] At the same time, since Linux distributions and FreeBSD are still general-purpose operating systems, with other applications competing for VM resources, KVM and bhyve can also be categorized as type-2 hypervisors.[7]
The first hypervisors providing full virtualization were the test tool SIMMON and IBM's one-off research CP-40 system, which began production use in January 1967, and became the first version of IBM's CP/CMS operating system. CP-40 ran on a S/360-40 that was modified at the IBM Cambridge Scientific Center to support Dynamic Address Translation, a key feature that allowed virtualization. Prior to this time, computer hardware had only been virtualized enough to allow multiple user applications to run concurrently (see CTSS and IBM M44/44X). With CP-40, the hardware's supervisor state was virtualized as well, allowing multiple operating systems to run concurrently in separate virtual machine contexts.
Programmers soon re-implemented CP-40 (as CP-67) for the IBM System/360-67, the first production computer-system capable of full virtualization. IBM first shipped this machine in 1966; it included page-translation-table hardware for virtual memory, and other techniques that allowed a full virtualization of all kernel tasks, including I/O and interrupt handling. (Note that its "official" operating system, the ill-fated TSS/360, did not employ full virtualization.) Both CP-40 and CP-67 began production use in 1967. CP/CMS was available to IBM customers from 1968 to early 1970s, in source code form without support.
CP/CMS formed part of IBM's attempt to build robust time-sharing systems for its mainframe computers. By running multiple operating systems concurrently, the hypervisor increased system robustness and stability: Even if one operating system crashed, the others would continue working without interruption. Indeed, this even allowed beta or experimental versions of operating systems—or even of new hardware[8]—to be deployed and debugged, without jeopardizing the stable main production system, and without requiring costly additional development systems.
IBM announced its System/370 series in 1970 without any virtualization features, but added virtual memory[clarification needed] support in the August 1972 Advanced Function announcement. Virtualization has been featured in all successor systems (all modern-day IBM mainframes, such as the zSeries line, retain backward compatibility with the 1960s-era IBM S/360 line). The 1972 announcement also included VM/370, a reimplementation of CP/CMS for the S/370. Unlike CP/CMS, IBM provided support for this version (though it was still distributed in source code form for several releases). VM stands for Virtual Machine, emphasizing that all, and not just some, of the hardware interfaces are virtualized. Both VM and CP/CMS enjoyed early acceptance and rapid development by universities, corporate users, and time-sharing vendors, as well as within IBM. Users played an active role in ongoing development, anticipating trends seen in modern open sourceprojects. However, in a series of disputed and bitter battles, time-sharing lost out to batch processing through IBM political infighting, and VM remained IBM's "other" mainframe operating system for decades, losing to MVS. It enjoyed a resurgence of popularity and support from 2000 as the z/VM product, for example as the platform for Linux for zSeries.
As mentioned above, the VM control program includes a hypervisor-call handler that intercepts DIAG ("Diagnose") instructions used within a virtual machine. This provides fast-path non-virtualized execution of file-system access and other operations (DIAG is a model-dependent privileged instruction, not used in normal programming, and thus is not virtualized. It is therefore available for use as a signal to the "host" operating system). When first implemented in CP/CMS release 3.1, this use of DIAG provided an operating system interface that was analogous to the System/360 Supervisor Call instruction (SVC), but that did not require altering or extending the system's virtualization of SVC.
In 1985 IBM introduced the PR/SM hypervisor to manage logical partitions (LPAR).
Operating system support[edit source]
Several factors led to a resurgence around 2005 in the use of virtualization technology among Unix, Linux, and other Unix-like operating systems:[9]
- Expanding hardware capabilities, allowing each single machine to do more simultaneous work
- Efforts to control costs and to simplify management through consolidation of servers
- The need to control large multiprocessor and cluster installations, for example in server farms and render farms
- The improved security, reliability, and device independence possible from hypervisor architectures
- The ability to run complex, OS-dependent applications in different hardware or OS environments
Major Unix vendors, including Sun Microsystems, HP, IBM, and SGI, have been selling virtualized hardware since before 2000. These have generally been large, expensive systems (in the multimillion-dollar range at the high end), although virtualization has also been available on some low- and mid-range systems, such as IBM's pSeries servers, Sun/Oracle's T-series CoolThreads servers and HP Superdome series machines.
Although Solaris has always been the only guest domain OS officially supported by Sun/Oracle on their Logical Domains hypervisor, as of late 2006, Linux (Ubuntu and Gentoo), and FreeBSD have been ported to run on top of the hypervisor (and can all run simultaneously on the same processor, as fully virtualized independent guest OSes). Wind River "Carrier Grade Linux" also runs on Sun's Hypervisor.[10] Full virtualization on SPARC processors proved straightforward: since its inception in the mid-1980s Sun deliberately kept the SPARC architecture clean of artifacts that would have impeded virtualization. (Compare with virtualization on x86 processors below.)[11]
HP calls its technology to host multiple OS technology on its Itanium powered systems "Integrity Virtual Machines" (Integrity VM). Itanium can run HP-UX, Linux, Windows and OpenVMS. Except for OpenVMS, to be supported in a later release, these environments are also supported as virtual servers on HP's Integrity VM platform. The HP-UX operating system hosts the Integrity VM hypervisor layer that allows for many important features of HP-UX to be taken advantage of and provides major differentiation between this platform and other commodity platforms - such as processor hotswap, memory hotswap, and dynamic kernel updates without system reboot. While it heavily leverages HP-UX, the Integrity VM hypervisor is really a hybrid that runs on bare-metal while guests are executing. Running normal HP-UX applications on an Integrity VM host is heavily discouraged,[by whom?] because Integrity VM implements its own memory management, scheduling and I/O policies that are tuned for virtual machines and are not as effective for normal applications. HP also provides more rigid partitioning of their Integrity and HP9000 systems by way of VPAR and nPar technology, the former offering shared resource partitioning and the latter offering complete I/O and processing isolation. The flexibility of virtual server environment (VSE) has given way to its use more frequently in newer deployments.[citation needed]
IBM provides virtualization partition technology known as logical partitioning (LPAR) on System/390, zSeries, pSeries and iSeries systems. For IBM's Power Systems, the POWER Hypervisor (PHYP) is a native (bare-metal) hypervisor in firmware and provides isolation between LPARs. Processor capacity is provided to LPARs in either a dedicated fashion or on an entitlement basis where unused capacity is harvested and can be re-allocated to busy workloads. Groups of LPARs can have their processor capacity managed as if they were in a "pool" - IBM refers to this capability as Multiple Shared-Processor Pools (MSPPs) and implements it in servers with the POWER6 processor. LPAR and MSPP capacity allocations can be dynamically changed. Memory is allocated to each LPAR (at LPAR initiation or dynamically) and is address-controlled by the POWER Hypervisor. For real-mode addressing by operating systems (AIX, Linux, IBM i), the POWER processors (POWER4 onwards) have designed virtualization capabilities where a hardware address-offset is evaluated with the OS address-offset to arrive at the physical memory address. Input/Output (I/O) adapters can be exclusively "owned" by LPARs or shared by LPARs through an appliance partition known as the Virtual I/O Server (VIOS). The Power Hypervisor provides for high levels of reliability, availability and serviceability (RAS) by facilitating hot add/replace of many parts (model dependent: processors, memory, I/O adapters, blowers, power units, disks, system controllers, etc.)
Similar trends have occurred with x86/x86-64 server platforms, where open-source projects such as Xen have led virtualization efforts. These include hypervisors built on Linux and Solaris kernels as well as custom kernels. Since these technologies span from large systems down to desktops, they are described in the next section.
Starting in 2005, CPU vendors have added hardware virtualization assistance to their products, for example: Intel VT-x (codenamed Vanderpool) and AMD-V(codenamed Pacifica).
An alternative approach requires modifying the guest operating-system to make system calls to the hypervisor, rather than executing machine I/O instructions that the hypervisor simulates. This is called paravirtualization in Xen, a "hypercall" in Parallels Workstation, and a "DIAGNOSE code" in IBM's VM. All are really the same thing, a system call to the hypervisor below. Some microkernels such as Mach and L4 are flexible enough such that "paravirtualization" of guest operating systems is possible.
Embedded hypervisors, targeting embedded systems and certain real-time operating system (RTOS) environments, are designed with different requirements when compared to desktop and enterprise systems, including robustness, security and real-time capabilities. The resource-constrained nature of many embedded systems, especially battery-powered mobile systems, imposes a further requirement for small memory-size and low overhead. Finally, in contrast to the ubiquity of the x86 architecture in the PC world, the embedded world uses a wider variety of architectures and less standardized environments. Support for virtualization requires memory protection (in the form of a memory management unit or at least a memory protection unit) and a distinction between user mode and privileged mode, which rules out most microcontrollers. This still leaves x86, MIPS, ARM and PowerPC as widely deployed architectures on medium- to high-end embedded systems.[12]
As manufacturers of embedded systems usually have the source code to their operating systems, they have less need for full virtualization in this space. Instead, the performance advantages of paravirtualization make this usually the virtualization technology of choice. Nevertheless, ARM and MIPS have recently added full virtualization support as an IP option and has included it in their latest high-end processors and architecture versions, such as ARM Cortex-A15 MPCore and ARMv8 EL2.
Other differences between virtualization in server/desktop and embedded environments include requirements for efficient sharing of resources across virtual machines, high-bandwidth, low-latency inter-VM communication, a global view of scheduling and power management, and fine-grained control of information flows.[13]
Security implications[edit source]
The use of hypervisor technology by malware and rootkits installing themselves as a hypervisor below the operating system, known as hyperjacking, can make them more difficult to detect because the malware could intercept any operations of the operating system (such as someone entering a password) without the anti-malware software necessarily detecting it (since the malware runs below the entire operating system). Implementation of the concept has allegedly occurred in the SubVirt laboratory rootkit (developed jointly by Microsoft and University of Michigan researchers[14]) as well as in the Blue Pill malware package. However, such assertions have been disputed by others who claim that it would be possible to detect the presence of a hypervisor-based rootkit.[15]
In 2009, researchers from Microsoft and North Carolina State University demonstrated a hypervisor-layer anti-rootkit called Hooksafe that can provide generic protection against kernel-mode rootkits.[16]
source - https://en.wikipedia.org/wiki/Hypervisor
Kernel-based Virtual Machine (KVM) is a virtualization infrastructure for the Linux kernel that turns it into a hypervisor. It was merged into the Linux kernel mainline in kernel version 2.6.20, which was released on February 5, 2007.[1] KVM requires a processor with hardware virtualization extensions.[2]KVM has also been ported to FreeBSD[3] and illumos[4] in the form of loadable kernel modules.
KVM originally supported x86 processors and has been ported to S/390,[5] PowerPC,[6] and IA-64. An ARM port was merged during the 3.9 kernel merge window.[7]
A wide variety of guest operating systems work with KVM, including many flavours and versions of Linux, BSD, Solaris, Windows, Haiku, ReactOS, Plan 9, AROS Research Operating System[8] and OS X.[9] In addition, Android 2.2, GNU/Hurd[10] (Debian K16), Minix 3.1.2a, Solaris 10 U3 and Darwin 8.0.1, together with other operating systems and some newer versions of these listed, are known to work with certain limitations.[11]
Paravirtualization support for certain devices is available for Linux, OpenBSD,[12] FreeBSD,[13]NetBSD,[14] Plan 9[15] and Windows guests using the VirtIO[16] API. This supports a paravirtual Ethernet card, a paravirtual disk I/O controller,[17] a balloon device for adjusting guest memory usage, and a VGA graphics interface using SPICE or VMware drivers.

A high-level overview of the KVM/QEMU virtualization environment
[18]:3By itself, KVM does not perform any emulation. Instead, it exposes the /dev/kvm interface, which a userspace host can then use to:
- Set up the guest VM's address space. The host must also supply a firmware image (usually a custom BIOS when emulating PCs) that the guest can use to bootstrap into its main OS.
- Feed the guest simulated I/O.
- Map the guest's video display back onto the system host.
On Linux, QEMU versions 0.10.1 and later is one such userspace host. QEMU uses KVM when available to virtualize guests at near-native speeds, but otherwise falls back to software-only emulation.
Internally, KVM uses SeaBIOS as an open source implementation of a 16-bit x86 BIOS.[19]
KVM's parts are licensed under various GNU licenses:[20]
- KVM kernel module: GPL v2
- KVM user module: LGPL v2
- QEMU virtual CPU core library (libqemu.a) and QEMU PC system emulator: LGPL
- Linux user mode QEMU emulator: GPL
- BIOS files (bios.bin, vgabios.bin and vgabios-cirrus.bin): LGPL v2 or later
Avi Kivity began the development of KVM at Qumranet, a technology startup company[21] that was acquired by Red Hat in 2008.[22]
KVM was merged into the Linux kernel mainline in kernel version 2.6.20, which was released on 5 February 2007.[1]
KVM is maintained by Paolo Bonzini.[23]
Graphical management tools[edit source]
- Kimchi – web-based virtualization management tool for KVM
- Virtual Machine Manager – supports creating, editing, starting, and stopping KVM-based virtual machines, as well as live or cold drag-and-drop migration of VMs between hosts.
- Proxmox Virtual Environment – an open-source virtualization management package including KVM and LXC. It has a bare-metal installer, a web-based remote management GUI, a HA cluster stack, unified storage, flexible network, and optional commercial support.
- OpenQRM – management platform for managing heterogeneous data center infrastructures.
- GNOME Boxes – Gnome interface for managing libvirt guests on Linux.
- oVirt – open-source virtualization management tool for KVM built on top of libvirt
| Class | Device |
|---|
| Video card | Cirrus CLGD 5446 PCI VGA card, dummy VGA card with Bochs VESA extensions,[24] or Virgil as a virtual 3D GPU[25] |
| PCI | i440FX host PCI bridge and PIIX3 PCI to ISA bridge[24] |
| Input device | PS/2 Mouse and Keyboard[24] |
| Sound card | Sound Blaster 16, ENSONIQ AudioPCI ES1370, Gravis Ultrasound GF1, CS4231A compatible[24] |
| Ethernet Network card | AMD Am79C970A (Am7990), E1000 (Intel 82540EM, 82573L, 82544GC), NE2000, and Realtek RTL8139 |
| Watchdog timer | Intel 6300ESB or IB700 |
| RAM | between 50 MB and 32 TB |
| CPU | 1 – 160 CPUs |
source - https://en.wikipedia.org/wiki/Kernel-based_Virtual_Machine
libvirt is an open-source API, daemon and management tool for managing platform virtualization.[3] It can be used to manage KVM, Xen, VMware ESX, QEMU and other virtualization technologies. These APIs are widely used in the orchestration layer of hypervisors in the development of a cloud-based solution.

libvirt supports several
Hypervisors and is supported by several management solutions
libvirt is a C library with bindings in other languages, notably in Python,[4] Perl,[5] OCaml,[6] Ruby,[7] Java,[8] JavaScript (via Node.js)[9] and PHP.[10] libvirt for these programming languages is composed of wrappers around another class/package called libvirtmod. libvirtmod's implementation is closely associated with its counterpart in C/C++ in syntax and functionality.
Supported Hypervisors[edit source]
Various virtualization programs and platforms use libvirt. Virtual Machine Manager and others provide graphical interfaces. The most popular command line interface is virsh, and higher level tools such as oVirt.[13]
GNOME Boxes uses libvirt.
Development of libvirt is backed by Red Hat,[14] with significant contributions by other organisations and individuals. Libvirt is available on most Linux distributions; remote servers are also accessible from Apple Mac OS X and Microsoft Windows clients.[15]
source - https://en.wikipedia.org/wiki/Libvirt
QEMU (short for Quick Emulator[citation needed]) is a free and open-source hosted hypervisor that performs hardware virtualization (not to be confused with hardware-assisted virtualization).
QEMU is a hosted virtual machine monitor: it emulates CPUs through dynamic binary translation and provides a set of device models, enabling it to run a variety of unmodified guest operating systems. It also can be used with KVM to run virtual machines at near-native speed (requiring hardware virtualization extensions on x86 machines). QEMU can also do CPU emulation for user-level processes, allowing applications compiled for one architecture to run on another.
QEMU was written by Fabrice Bellard and is free software and is mainly licensed under GNU General Public License (GPL). Various parts are released under BSD license, GNU Lesser General Public License (LGPL) or other GPL-compatible licenses.[2] There is an option to use the proprietary FMOD library when running on Microsoft Windows, which, if used, disqualifies the use of a single open source software license. However, the default is to use DirectSound.
QEMU has multiple operating modes:[3]
- User-mode emulation
- In this mode QEMU runs single Linux or Darwin/macOS programs that were compiled for a different instruction set. System calls are thunked for endianness and for 32/64 bit mismatches. Fast cross-compilation and cross-debugging are the main targets for user-mode emulation.
- System emulation
- In this mode QEMU emulates a full computer system, including peripherals. It can be used to provide virtual hosting of several virtual computers on a single computer. QEMU can boot many guest operating systems, including Linux, Solaris, Microsoft Windows, DOS, and BSD;[4] it supports emulating several instruction sets, including x86, MIPS, 32-bit ARMv7, ARMv8, PowerPC, SPARC, ETRAX CRIS and MicroBlaze.
- KVM Hosting
- Here QEMU deals with the setting up and migration of KVM images. It is still involved in the emulation of hardware, but the execution of the guest is done by KVM as requested by QEMU.
- Xen Hosting
- QEMU is involved only in the emulation of hardware; the execution of the guest is done within Xen and is totally hidden from QEMU.
QEMU can save and restore the state of the virtual machine with all programs running. Guest operating-systems do not need patching in order to run inside QEMU.
QEMU supports the emulation of various architectures, including:
The virtual machine can interface with many types of physical host hardware. These include: hard disks, CD-ROM drives, network cards, audio interfaces, and USB devices. USB devices can be completely emulated (mass storage from image files, input devices), or the host's USB devices can be used (however, this requires administrator privileges and does not work with all devices).
Virtual disk images can be stored in a special format (qcow or qcow2) that only take up disk space that the guest OS actually uses. This way, an emulated 120 GB disk may occupy only a few hundred megabytes on the host. The QCOW2 format also allows the creation of overlay images that record the difference from another (unmodified) base image file. This provides the possibility for reverting the emulated disk's contents to an earlier state. For example, a base image could hold a fresh install of an operating system that is known to work, and the overlay images are used. Should the guest system become unusable (through virus attack, accidental system destruction, etc), the user can delete the overlay and reconstruct an earlier emulated disk-image version.
QEMU can emulate network cards (of different models) which share the host system's connectivity by doing network address translation, effectively allowing the guest to use the same network as the host. The virtual network cards can also connect to network cards of other instances of QEMU or to local TAP interfaces. Network connectivity can also be achieved by bridging a TUN/TAP interface used by QEMU with a non-virtual Ethernet interface on the host OS using the host OS's bridging features.
QEMU integrates several services to allow the host and guest systems to communicate; for example, an integrated SMB server and network-port redirection (to allow incoming connections to the virtual machine). It can also boot Linux kernels without a bootloader.
QEMU does not depend on the presence of graphical output methods on the host system. Instead, it can allow one to access the screen of the guest OS via an integrated VNC server. It can also use an emulated serial line, without any screen, with applicable operating systems.
Simulating multiple CPUs running SMP is possible.
QEMU does not require administrative rights to run, unless additional kernel modules for improving speed are used (like KQEMU), or when some modes of its network connectivity model are utilized.
The Tiny Code Generator (TCG) aims to remove the shortcoming of relying on a particular version of GCC or any compiler, instead incorporating the compiler (code generator) into other tasks performed by QEMU at run time. The whole translation task thus consists of two parts: blocks of target code (TBs) being rewritten in TCG ops - a kind of machine-independent intermediate notation, and subsequently this notation being compiled for the host's architecture by TCG. Optional optimisation passes are performed between them.
TCG requires dedicated code written to support every architecture it runs on. It also requires that the target instruction translation be rewritten to take advantage of TCG ops, instead of the previously used dyngen ops.
Starting with QEMU Version 0.10.0, TCG ships with the QEMU stable release.[6]
KQEMU was a Linux kernel module, also written by Fabrice Bellard, which notably sped up emulation of x86 or x86-64 guests on platforms with the same CPU architecture. This worked by running user mode code (and optionally some kernel code) directly on the host computer's CPU, and by using processor and peripheral emulation only for kernel-mode and real-mode code. KQEMU could execute code from many guest OSes even if the host CPU did not support hardware-assisted virtualization. KQEMU was initially a closed-source product available free of charge, but starting from version 1.3.0pre10,[7] it was relicensed under the GNU General Public License. QEMU versions starting with 0.12.0 (as of August 2009) support large memory which makes them incompatible with KQEMU.[8] Newer releases of QEMU have completely removed support for KQEMU.
QVM86 was a GNU GPLv2 licensed drop-in replacement for the then closed-source KQEMU. The developers of QVM86 ceased development in January, 2007.
Kernel-based Virtual Machine (KVM) has mostly taken over as the Linux-based hardware-assisted virtualization solution for use with QEMU in the wake of the lack of support for KQEMU and QVM86.[citation needed]
Intel's Hardware Accelerated Execution Manager (HAXM) is an open-source alternative[9] to KVM for x86-based hardware-assisted virtualization on Windows and macOS. As of 2013 Intel mostly solicits its use with QEMU for Android development.[10] Starting with version 2.9.0, the official QEMU includes support for HAXM.
Supported disk image formats[edit source]
QEMU supports the following disk image formats:[11]
Hardware-assisted emulation[edit source]
The MIPS-compatible Loongson-3 processor adds 200 new instructions to help QEMU translate x86 instructions; those new instructions lower the overhead of executing x86/CISC-style instructions in the MIPS pipeline. With additional improvements in QEMU by the Chinese Academy of Sciences, Loongson-3 achieves an average of 70% the performance of executing native binaries while running x86 binaries from nine benchmarks.[13]
Virtualization solutions that use QEMU are able to execute multiple virtual CPUs in parallel. For user-mode emulation QEMU maps emulated threads to host threads. For full system emulation QEMU is capable of running a host thread for each emulated virtual CPU (vCPU). This is dependent on the guest having been updated to support parallel system emulation, currently ARM and Alpha. Otherwise a single thread is used to emulate all virtual CPUS (vCPUS) which executes each vCPU in a round-robin manner.
VirtualBox, released in January 2007, uses some of QEMU's virtual hardware devices, and has a built-in dynamic recompiler based on QEMU. As with KQEMU, VirtualBox runs nearly all guest code natively on the host via the VMM (Virtual Machine Manager) and uses the recompiler only as a fallback mechanism - for example, when guest code executes in real mode.[14] In addition, VirtualBox does a lot of code analysis and patching using a built-in disassembler in order to minimize recompilation. VirtualBox is free and open-source (available under GPL), except for certain features.
Xen, a virtual machine monitor, can run in HVM (hardware virtual machine) mode, using Intel VT-x or AMD-V hardware x86 virtualization extensions and ARMCortex-A7 and Cortex-A15 virtualization extension.[15] This means that instead of paravirtualized devices, a real set of virtual hardware is exposed to the domU to use real device drivers to talk to.
QEMU includes several components: CPU emulators, emulated devices, generic devices, machine descriptions, user interface, and a debugger. The emulated devices and generic devices in QEMU make up its device models for I/O virtualization.[16] They comprise a PIIX3 IDE (with some rudimentary PIIX4 capabilities), Cirrus Logic or plain VGA emulated video, RTL8139 or E1000 network emulation, and ACPI support.[17] APIC support is provided by Xen.
Xen-HVM has device emulation based on the QEMU project to provide I/O virtualization to the VMs. Hardware is emulated via a QEMU "device model" daemon running as a backend in dom0. Unlike other QEMU running modes (dynamic translation or KVM), virtual CPUs are completely managed to the hypervisor, which takes care of stopping them while QEMU is emulating memory-mapped I/O accesses.
KVM (Kernel-based Virtual Machine) is a FreeBSD and Linux kernel module that allows a user space program access to the hardware virtualization features of various processors, with which QEMU is able to offer virtualization for x86, PowerPC, and S/390 guests. When the target architecture is the same as the host architecture, QEMU can make use of KVM particular features, such as acceleration.
In early 2005, Win4Lin introduced Win4Lin Pro Desktop, based on a 'tuned' version of QEMU and KQEMU and it hosts NT-versions of Windows. In June 2006,[18]Win4Lin released Win4Lin Virtual Desktop Server based on the same code base. Win4Lin Virtual Desktop Server serves Microsoft Windows sessions to thin clients from a Linux server.
In September 2006, Win4Lin announced a change of the company name to Virtual Bridges with the release of Win4BSD Pro Desktop, a port of the product to FreeBSD and PC-BSD. Solaris support followed in May 2007 with the release of Win4Solaris Pro Desktop and Win4Solaris Virtual Desktop Server.[19]
SerialICE is a QEMU-based firmware debugging tool running system firmware inside of QEMU while accessing real hardware through a serial connection to a host system. This can be used as a cheap replacement for hardware ICEs.[20]
WinUAE Amiga emulator introduced in version 3.0.0 the support for CyberStorm PPC and Blizzard 603e boards using QEMU PPC core.[21]
Emulated hardware platforms[edit source]
Besides the CPU (which is also configurable and can emulate the Intel Sandy Bridge[22]), the following devices are emulated:
- CD-ROM/DVD-drive using an ISO image
- Floppy disk
- ATA controller or Serial ATA AHCI controller
- Graphics card (Cirrus CLGD 5446 PCI VGA-card,Standard-VGA graphics card with Bochs-VESA-BIOS-Extensions - Hardware level, including all non-standard modes, and an experimental patch that can accelerate simple 3D graphics via OpenGL, Red Hat QXL VGA or VirtIO GPU)
- Network card (Realtek 8139C+ PCI network adapter)
- Depending on target: i82551, i82557b, i82559er, NE2000 PCI, NE2000 ISA, PCnet, RTL8139, e1000 (PCI Intel Gigabit Ethernet), SMC91c111, Lance and mcf_fec.[23][24]
- NVMe disk interface
- Parallel port
- PC speaker
- i440FX/PIIX3 (PCI and ISA) or Q35/ICH9 (PCIe and LPC) chipsets
- PS/2-mouse and -keyboard
- SCSI controller (LSI MegaRAID SAS 1078, LSI53C895A, NCR53C9x as found in the AMD PCscsi and Tekram DC-390 controllers)
- Serial interface
- Sound card (Sound Blaster 16, ES1370 PCI, Gravis Ultrasound, AC97, and Intel HD Audio[25])
- Watchdog timer (Intel 6300 ESB PCI, or iB700 ISA)
- USB 1.x/2.x/3.x controllers (UHCI, EHCI, xHCI)
- USB devices: audio, Bluetooth dongle, HID (keyboard/mouse/tablet), MTP, serial interface, CAC smartcard reader, storage (bulk-only transfer and USB Attached SCSI), Wacom tablet
- Paravirtualized VirtIO devices: block device, network card, SCSI controller, serial interface, balloon driver, 9pfs filesystem driver
- Paravirtualized Xen devices: block device, network card, console, framebuffer and input device
The BIOS implementation used by QEMU starting from version 0.12 is SeaBIOS. The VGA BIOS implementation comes from Plex86/Bochs.The UEFI firmware for QEMU is OVMF.
QEMU emulates the following PowerMac peripherals:
- UniNorth PCI bridge
- PCI-VGA-compatible graphics card which maps the VESA Bochs Extensions
- Two PMAC-IDE-Interfaces with hard disk and CD-ROM support.
- NE2000 PCI adapter
- Non-volatile RAM
- VIA-CUDA with ADB keyboard and mouse.
OpenBIOS is used as the firmware.
QEMU emulates the following PREP peripherals:
- PCI bridge
- PCI VGA-compatible graphics card with VESA Bochs Extensions
- Two IDE interfaces with hard disk and CD-ROM support
- Floppy disk drive
- NE2000 network adapter
- Serial interface
- PREP non-volatile RAM
- PC-compatible keyboard and mouse
On the PREP target, Open Hack'Ware, an Open-Firmware–compatible BIOS, is used.
QEMU can emulate the paravirtual sPAPR interface with the following peripherals:
- PCI bridge, for access to virtio devices, VGA-compatible graphics, USB, etc.
- Virtual I/O network adapter, SCSI controller, and serial interface
- sPAPR non-volatile RAM
On the sPAPR target, another Open-Firmware–compatible BIOS is used, called SLOF.

QEMU booted into the ARM port of
Fedora 8QEMU emulates the ARMv7 instruction set (and down to ARMv5TEJ) with NEON extension.[26] It emulates full systems like Integrator/CP board, Versatile baseboard, RealView Emulation baseboard, XScale-based PDAs, Palm Tungsten|E PDA, Nokia N800 and Nokia N810 Internet tablets etc. QEMU also powers the Android emulator which is part of the Android SDK (most current Android implementations are ARM based). Starting from version 2.0.0 of their Bada SDK, Samsung has chosen QEMU to help development on emulated 'Wave' devices.
In 1.5.0 and 1.6.0 Samsung Exynos 4210 (dual-core Cortex a9) and Versatile Express ARM Cortex-A9 ARM Cortex-A15 are emulated. In 1.6.0, the 32-bit instructions of the ARMv8 (AARCH64) architecture are emulated, but 64-bit instructions are unsupported.
The Xilinx Cortex A9-based Zynq SoC is modelled, with the following elements:
- Zynq-7000 ARM Cortex-A9 CPU
- Zynq-7000 ARM Cortex-A9 MPCore
- Triple Timer Counter
- DDR Memory Controller
- DMA Controller (PL330)
- Static Memory Controller (NAND/NOR Flash)
- SD/SDIO Peripheral Controller (SDHCI)
- Zynq Gigabit Ethernet Controller
- USB Controller (EHCI - Host support only)
- Zynq UART Controller
- SPI and QSPI Controllers
- I2C Controller
QEMU has support for both 32 and 64-bit SPARC architectures.
When the firmware in the JavaStation (sun4m-Architecture) became version 0.8.1 Proll,[27] a PROM replacement used in version 0.8.2, was replaced with OpenBIOS.
QEMU emulates the following sun4m/sun4c/sun4d peripherals:
- IOMMU or IO-UNITs
- TCX Frame buffer (graphics card)
- Lance (Am7990) Ethernet
- Non-volatile RAM M48T02/M48T08
- Slave I/O: timers, interrupt controllers, Zilog serial ports, keyboard and power/reset logic
- ESP SCSI controller with hard disk and CD-ROM support
- Floppy drive (not on SS-600MP)
- CS4231 sound device (only on SS-5, not working yet)
Emulating Sun4u (UltraSPARC PC-like machine), Sun4v (T1 PC-like machine), or generic Niagara (T1) machine with the following peripherals:
- UltraSparc IIi APB PCI Bridge
- PCI VGA compatible card with VESA Bochs Extensions
- PS/2 mouse and keyboard
- Non-volatile RAM M48T59
- PC-compatible serial ports
- 2 PCI IDE interfaces with hard disk and CD-ROM support
- Floppy disk
Supported peripherals:
- MicroBlaze with/without MMU, including
- AXI Timer and Interrupt controller peripherals
- AXI External Memory Controller
- AXI DMA Controller
- Xilinx AXI Ethernet
- AXI Ethernet Lite
- AXI UART 16650 and UARTLite
- AXI SPI Controller
Supported peripherals:
From the Milkymist SoC
- UART
- VGA
- Memory card
- Ethernet
- pfu
- timer
![[icon]](https://upload.wikimedia.org/wikipedia/commons/thumb/1/1c/Wiki_letter_w_cropped.svg/20px-Wiki_letter_w_cropped.svg.png) | This section is empty. You can help by adding to it. (January 2011) |
| This section is empty. You can help by adding to it. (August 2012) |
External trees exist supporting the following targets:
source - https://en.wikipedia.org/wiki/QEMU
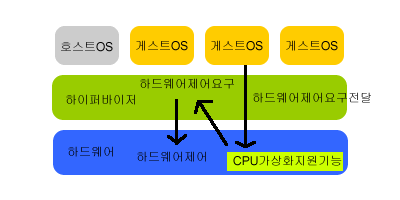
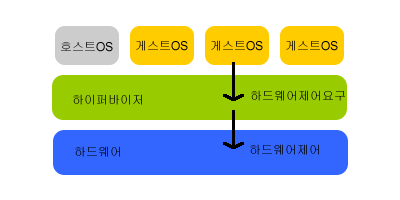
하이퍼바이저(hypervisor)는 호스트 컴퓨터에서 다수의 운영 체제(operating system)를 동시에 실행하기 위한 논리적 플랫폼(platform)을 말한다. 가상화 머신 모니터(virtual machine monitor, 줄여서 VMM)라고도 부른다.
하이퍼바이저는 일반적으로 2가지로 나뉜다. [1]
- Type 1 (native 또는 bare-metal)
운영 체제가 프로그램을 제어하듯이 하이퍼바이저가 해당 하드웨어에서 직접 실행되며 게스트 운영 체제는 하드웨어 위에서 2번째 수준로 실행된다. 이런 방식의 하이퍼바이저는 1960년대 IBM이 개발한 CP/CMS에서 시작되었으며 IBM의 z/VM으로 이어졌다. 최근에는 Xen, Citrix의 XenServer, VMware의 ESX Server, L4 마이크로커널, TRANGO, IBM의 POWER 하이퍼바이저(PR/SM), 마이크로소프트의 하이퍼-V, 패러랠서버, 썬의 로지컬 도메인 하이퍼바이저 등이 있다. 또 히타치의 Virtage 하이퍼바이저같이 플랫폼의 펌웨어에 하이퍼바이저를 넣기도 하며 KVM은 하이퍼바이저 안에 완전한 리눅스 커널을 넣었는데 이것도 Type 1 이다.
하이퍼바이저는 일반 프로그램과 같이 호스트 운영 체제에서 실행되며 VM 내부에서 동작되는 게스트 운영 체제는 하드웨어에서 3번째 수준으로 실행된다. VM의 대표적인 종류는 VMware Server, VMware Workstation, VMware Fusion, QEMU, 마이크로소프트의 버추얼 PC와 버추얼 서버, Oracle(SUN)의 버추얼박스, SWsoft의 Parallels Workstation과 Parallels Desktop이 있다.
하이퍼바이저란 System/370의 CP-67을 재작성한 CP-370에서 유래되었으며 1972년 VM/370으로 발표하였다. 하이퍼바이저 콜(hypervisor call), 곧 하이퍼콜(hypercall)이란 게스트 운영 체제가 (보다 높은 수준의) 제어 프로그램에서 직접 서비스에 접근할 수 있는 반가상화(paravirtualization) 인터페이스로 인용된다. - (같은 수준의) 운영 체제에서 감시자 호출(supervisor call)을 요청하는 것과 비슷하다. (슈퍼바이저란 IBM 메인프레임에서 감시 프로그램 상태로 실행되는 운영 체제 커널을 말한다.)
최초의 하이퍼바이저로 1967년 1월 제작된 IBM의 CP-40은 전가상화(Full virtualization) 기능을 제공하였는데 IBM CP/CMS 운영 시스템의 첫 번째 버전이 되었다. CP-40은 가상화 기능을 지원하게끔 개조된 전용 S/360-40에서 실행되었다. 그 이전부터 컴퓨터 하드웨어는 여러 개의 사용자 응용 프로그램을을 실행하기에 충분한 가상화가 이루어지고 있었다. CP-40에서 하드웨어의 감시 프로그램 상태(supervisor state) 또한 여러 개의 운영 체제가 동시에 실행할 수 있을만큼 가상화가 되어 있었다.
CP-40은 곧 전가상화 기능을 가진 첫 컴퓨터 시스템이었던 IBM System/360-67용의 CP-67로 다시 작성되었다. 이 머신은 1966년 첫 출하를 시작했는데 가상 메모리를 위한 페이지 변환 테이블 하드웨어를 내장하고 있었으며 입출력과 인터럽트 핸들링을 포함한 모든 커널 작업들의 전가상화하기 위한 기술들이 사용되었다. (이것들은 정식 운영 체제에 해당하는 것으로 운이 없었던 TSS/360은 전가상화를 사용하지 않았다.) CP-40과 CP-67은 둘다 1967년부터 사용되기 시작했다. CP/CMS는 1968년에서 1972년 동안 IBM 고객에게 별도의 지원 없이 소스 코드 형태로 제공되어 쓰였다.
CP/CMS는 메인프레임으로 강력한 시분할 시스템을 구축하기 위한 시도 가운데 하나였다. 여러 개의 운영 체제를 동시에 실행시키기 위해 하이퍼바이저는 견고성과 안정성을 증가시켰다. 하나의 운영 체제가 중단되더라도 다른 운영 체제가 중단 없이 작업을 계속 할 수 있었다. 확실히 이것은 안정된 메인프레임 시스템에서 시스템을 위험에 빠트리거나 추가 개발 시스템 없이 새로운 하드웨어나 운영 체제 개발, 디버그를 할 수 있었다.
IBM System/370 시리즈는 1970년 가상화 기능이 없이 발표되었으나 1972년 추가되었으며 그 이후 모든 후계 시스템에서 찾아 볼 수 있다. (zSeries같은 오늘날의 모든 IBM 메인프레임은 1960년대의 IBM S/360 시리즈와 하위 호환성을 가지고 있다.)
1972년 발표에 S/370용 CP/CMS의 재이식에 VM/370도 포함되었다. CP/CMS과는 달리 IBM은 몇가지 릴리즈의 이전과 같은 소스 코드 형태로 배포하긴 했지만 이 버전의 지원을 제공하였다. VM은 가상 머신(Virtual Machine)을 의미하며 하드웨어 인터페이스를 가상화했다는 점이 강조되었다. VM과 CP/CMS은 모두 대학이나 기업 사용자, IBM과 같은 시분할 제조업체에게 일찍부터 채택되어 빠른 개발 작업에 사용되었다.
사용자는 개발을 진행하는 동안 능동적으로 역할을 하였는데 현재의 오픈 소스 프로젝트에서 보이는 추세를 예상시켰다. 그러나 연속된 논쟁과 호된 경쟁 속에서 IBM의 내분으로 시분할은 일괄 처리(batch processing)에 밀려났으며 VM은 MVS가 사라진 지 수십 년이 지났으나 IBM의 다른 메인프레임 운영 체제에 남아있다. 다시 인기를 얻어 최근에 zSeries의 리눅스 플랫폼과 같은 기존의 z/VM에 지원되고 있다.
위에서 말한 것과 같이 VM 제어 프로그램은 가상머신 속의 DIAG(진단) 명령어를 가로채는 하이퍼바이저 콜 핸들러를 포함하고 있으며 이것은 파일 시스템 액서스 같은 가상화되지 않은 작업을 실행하는 데 빠른 경로를 제공한다. (DIAG는 모델 의존적인 특권 명령어로 보통 프로그램에 사용되지 않으며 가상화도 되지 않는다. 그래서 호스트 운영 체제로 신호를 보내는 용도로 사용된다.) CP/CMS이 release 3.1으로 처음 재작성 되었을 때 DIAG를 사용하여 System/360 SVC(supervisor call) 명령어와 유사한 운영 체제 인터페이스를 제공하였는데 SVC의 시스템 가상화 때문에 시스템을 수정하거나 확장할 필요는 없었다.
몇 가지 요인이 유닉스나 리눅스 서버 제조업체들이 가상화 기술을 다시 사용하게 만들었다.
- 하드웨어 능력의 확대로 한 컴퓨터에서 동시에 작업할 수 있는 양이 증가하였다.
- 서버를 통합하여 비용이 줄고 관리를 간소화하였다.
- 서버 저장소나 렌더 저장소 같은 대규모 멀티프로세서와 클러스터 장비를 제어할 필요가 있었다.
- 하이퍼바이저 아키텍처로 인해 보안성, 신뢰성, 장비의 독립성이 증가하였다.
- 특정한 운영 체제에 의존적인 응용 프로그램을 다른 하드웨어나 운영 체제 환경에서 실행시킬 필요가 있었다.
대형 유닉스 제조업체인 선 마이크로시스템즈, HP, IBM, SGI는 2000년 이전부터 가상화된 하드웨어를 판매하고 있었다. 이것들은 보통 크고 무거우며 비싼 가격표(하이엔드의 경우 수백만 달러)를 달고 있었고 가상화도 IBM의 System-P 서버, 선의 CoolThreads T1000, T2000, T5x00 서버, HP 9000 Superdome 시리즈 같은 몇가지 중형 시스템에서나 사용할 수 있었다.
썬의 로지컬 도메인 하이퍼바이저 같이 다수의 호스트 운영 체제는 게스트 운영 체제를 실행하기 위해 변경되었다. 2006년 후반 솔라리스, 리눅스(우분투와 젠투), FreeBSD는 하이퍼바이저 상에서 실행되도록 이식되었다. (그리고 완전 가상화로 게스트 운영 체제에서 독립되어 같은 프로세서에서 동시에 실행할 수 있었다.) Wind River의 Carrier Grade Linux 또한 선의 하이버바이저에서 실행하기 위한 계획에 있다. SPARC 프로세서에서 전가상화는 어렵지 않다. 그 이유는SPARC 아키텍처가 1980년대 중반부터 가상화에 방해되는 낡은 구조를 제거하기 시작했다. (아래의 x86 프로세서에서의 가상화와 비교해 보자.)
IBM의 매우 비슷한 기술로는 logical partitioning(LPAR)으로 알려진 것으로 System/390, zSeries, pSeries, iSeries 시스템에 적용되어 있다.
비슷한 경향은 x86/x64서버 플랫폼에서 Xen과 같은 오픈 소스 프로젝트에서 주도하는 가상화 노력으로 살펴볼 수 있다. 이것들은 리눅스와 솔라리스 커널에 하이퍼바이저를 구축하여 내장하고 있다. 이 기술은 대형 시스템에서 데스크탑으로 확대된 것으로 다음 섹션에서 설명하겠다.
[편집]PC와 데스크톱 시스템
높은 수익을 내는 서버 하드웨어 시장 영역에 대한 관심은 전통적인 데스크톱 PC를 포함하여 인텔 x86 명령셋 컴퓨터의 하이퍼바이저 개발을 이끌고 있다. 초기의 PC 하이퍼바이저는 상업적인 VMware로 1998년 발표하였다. 2005년 Parallels 사에서 발표한 Parallels Workstation은 주로 PC에서 사용되었으며 2006년에는 맥 OS X에서 실행되는 Parallels Desktop for Mac을 발표하였다.
x86 아키텍처를 사용하는 대부분의 PC 시스템에서는 특히 가상화가 어렵다. x86에서의 전가상화는 하이퍼바이저의 복잡함과 실행 성능에 중대한 희생을 치른다.
다른 대안으로 하이퍼바이저에 의해 가상의 머신 입출력 명령을 실행하는 것보다 하이퍼바이저에 시스템 콜을 발생시키기 위해 게스트 운영 체제를 변경하는 것을 필요로 한다. 이것을 Xen에서는 반가상화(paravirtualization), Parallels Workstation에서는 하이퍼콜(hypercall), IBM의 VM에서는 진단 코드(DIAGNOSE code)라 부른다. VMware는 가상화에서 가장 느린 곳에 게스트용 장치 드라이버를 사용하여 보완했다. 시스템 콜을 하이퍼바이저로 보내는 방법은 모두 같다. Mach와 L4 같은 마이크로커널은 게스트 운영 체제의 반가상화를 실현하기에 충분히 유연하다.
CPU 제조업체는 자사의 제품에 하드웨어 가상화를 위한 원조를 추가하였다. 인텔의 VT(코드네임 Vanderpool)와 AMD의 AMD 가상화 또는 AMD-V(코드네임 Pacifica)는 x86의 가상화에 어렵거나 비능률적인 부분을 확장하여 하이퍼바이저의 지원을 추가로 제공한다. 이것은 전가상화를 위해 좀 더 단순한 가상화 코드와 높은 성능을 가능하게 한다.
Xen과 같은 또 다른 것들은 소프트웨어 만으로 가상 머신을 실현하였다. Xen은 리눅스와 같은 일반 호스트 운영 체제에서 동작되며 반가상화와 함께 게스트 운영 체제를 수정하지 않고도 인텔의 VTx 하드웨어 가상화 확장을 사용한 완전 가상화 둘 다 실행할 수 있다. Xen은 변경하지 않은 윈도 XP의 실행을 시연하는데 성공하였다. Xen의 배포판에는 변경된 FreeBSD, Linux, NetBSD, 벨 연구소의 Plan 9이 포함되어 있다. 유저 프로그램은 변경없이 Xen에서 작동된다. 또 Xen은 선의 xVM 서버의 결과물로 오픈 솔라리스 커널로 이식을 시작하였다.
2008년 마이크로소프트는 새로운 Type 1 하이퍼바이저로 하이퍼 V(코드네임은 Viridian으로 이전에는 윈도 서버 가상화로 알려졌다.)를 윈도 서버 2008를 발표한 지 180일 안에 출하하려고 하며 가장 낮은 수준에서 운영 체제와 통합을 특징으로 한다.[2] 윈도 비스타에서 시작된 윈도 운영 체제의 새 버전은 Viridian 하이퍼바이저에서 실행시켰을 때 성능을 끌어올리는 확장을 포함하고 있다.
[편집]임베디드 시스템
가상 머신은 휴대폰과 같은 임베디드 시스템에는 최근에 나타났다. 응용 프로그램을 프로그래밍하기 위해 리눅스나 마이크로소프트 윈도와 같은 높은 수준의 운영 체제 인터페이스를 제공하기 위한 욕망와 같은 시기 전통적인 실시간 운영 체제(RTOS)의 API의 유지에서 시작되었다. 낮은 수준의 RTOS 환경은 종래의 기능을 지원하기 위해서 계속해서 유지할 필요가 있었는데 높은 수준의 운영 체제 실시간 성능은 많은 임베디드 응용 프로그램에 맞지 않았다.
임베디드에 사용되는 하이퍼바이저는 그런 이유로 반드시 실시간 성능이 충족되어야 하며 설계 기준이 다른 영역에서 사용되는 하이퍼바이저는 맞지 않는다. 리소스가 한정된 임베디드 시스템의 특성이 있는데 특히 배터리로 구동되는 모바일 시스템은 작은 메모리 크기와 낮은 오버헤드같은 더 앞선 필요 조건을 강요한다. PC 분야에서 X86 아키텍처를 흔히 볼 수 있는 것에 비해 임베디드 분야에서는 폭넓은 다양한 아키텍처가 사용된다. 가상화를 지원하기 위해서는 메모리 보호가 필요하며(메모리 관리 유닛 형태나 최소한 메모리 보호 유닛 형태) 유저 모드와 특권 모드가 구별되기 때문에 대부분의 마이크로프로세서는 해당되지 않는다. 이말은 미들에서 하이엔드에 걸쳐 임베디드 시스템 용도로 널리 사용되는 x86, MIPS, ARM, PowerPC 같은 아키텍처들은 계속 남게 된다는 것이다. 임베디드 시스템의 제조업체는 보통 자신들의 운영 체제 소스 코드를 가지고 있으며 전가상화의 필요성은 그다지 없었다. 그 대신 반가상화 높은 성능이 가상화 기술을 선택하게 만들었으며 ARM은 최근에 자사의 TrustZone 기술로 전가상화에 대한 지원을 추가하였다.
최초의 상업적 모바일 임베디드 시스템 하이퍼바이저로 판매된 것은 도시바 휴대폰에 사용된 OKL4이며 L4 마이크로커널의 상업용 버전으로 x86, ARM, MIPS 프로세서를 지원한다. 또, 다른 임베디드 시스템으로 TRANGO가 있는데 ARM, MIPS, PowerPC를 지원한다.[3]
[편집]참조 자료
[편집]바깥 고리
===================================================================================
컴퓨터 용어에서, 하이퍼 바이저 ( hypervisor )는 컴퓨터 가상화 기술의 하나 인 가상 머신 (가상 머신)을 실현하기위한 제어 프로그램이다. 가상화 모니터 및가상화 OS 라는 것도있다.
이름 [ 편집 ]
하이퍼 바이저를 직역하면 "상위 관리자"가된다. 응용 프로그램 소프트웨어 에서보고, 운영 시스템 (OS, 특히 커널 ) 것을 수퍼바이저 라고 그 시스템 호출 을 수퍼바이저 콜이라고도 부르는데, 가상 기계 의 경우 OS를 더 상위의 제어 프로그램이 관리하는 지정 명칭으로한다.
개요 [ 편집 ]
하이퍼 바이저는 크게 나누어 두 종류가 만든 가상 기계 (가상 머신)에서 각각의 OS (게스트 OS)를 달릴 수있다.
또한 게스트 OS를 수정하지 않고 그대로 가동 할 (하드웨어를 완전히 에뮬레이트 하는)을 완전히 가상화, 성능 등의 이유로 게스트 OS에 수정이 필요한 것을 반 가상화 라고도 부른다.
또한, 가상 기계에서도 단순한 물리적 분할 ( PPAR )에서 특히 자원 관리를하지 않은 경우, 하이퍼 바이저는 존재하지 않는다.
분류 [ 편집 ]
하이퍼 바이저의 분류 방법은 다수 있지만, 여기에서는 그 작동 방식에 따라 두 가지 유형으로 분류한다.
Type 1 ( "기본"또는 "베어 메탈") 하이퍼 바이저 [ 편집 ]

베어 메탈 하이퍼 바이저 Materiel = 하드웨어, Hyperviseur = 하이퍼 바이저, OS Privilégié = 관리 OS, OS invité = 게스트 OS 하이퍼 바이저가 하드웨어에서 직접 실행하고 모든 OS (게스트 OS)는 하이퍼 바이저상에서 동작하는 방식을 가리킨다. 협의의 "하이퍼 바이저"보기 만 가리킨다.
이 방식의 하이퍼 바이저는 IBM 이 1960 년대에 개발 한 CP / CMS 가 처음으로 현재 IBM z / VM 의 조상이다. 최근의 예는 다음과 같다.
이것의 파생 상품으로는 플랫폼의 펌웨어 에 포함 된 하이퍼 바이저가 다음이있다.
또한 KVM 하이퍼 바이저에서 Linux 커널을 완전히 묻어 버리는 것, 이것 또한 Type1이다. 대부분의 대형 메인 프레임에는이 기능이 채워진.
Type 2 ( "호스트") 하이퍼 바이저 [ 편집 ]

호스팅 하이퍼 바이저 Materiel = 하드웨어, OS hôte = 호스트 OS, OS invité = 게스트 OS 하드웨어에서 먼저 다른 OS를 실행 (이 OS를 호스트 OS 라고 함), 그 위에 하이퍼 바이저 (호스트 OS의 응용 프로그램으로) 실행, 나아가서는 하이퍼 바이저에서 또는 다른 OS (이 OS를 게스트 OS 라고 부른다)을 실행하는 방법이다. 협의에서는 Type 2 하이퍼 바이저에는 포함되지 않는다.
예는 다음과 같다.
역사 [ 편집 ]
"하이퍼 바이저"라는 용어는 System/370 에 CP-67 를 다시 구현 한 IBM의 CP-370이 기원이며, VM/370 로 1972 년에 출시되었다. hypervisor call 또는 hypercall 라는 용어는 반 가상화 인터페이스에서 참조되지만, 무엇에서 게스트 OS가 (상위 계층)의 제어 프로그램에서 서비스에 직접 액세스하거나 또는 같은 수준의 OS에supervisor call 을 무엇으로 할 가하는 것과 비슷하다. ( 관리자 라는 용어는 IBM의 메인 프레임에서 운영 체제 커널 이 supervisor state 로 동작하고 있다고 기술되어있다.)
메인 프레임 [ 편집 ]
하이퍼 바이저는 메인 프레임 에서 가장 먼저 구현되었다. 소프트웨어 전체 가상화 를 처음 제공 한 것은 IBM 의 CP-40 에서 연구용으로 1967 년 1 월부터 생산이 시작되었다. CP-40은 또한 CP-67 VM/370, VM / XA, VM / ESA되어, 현재의 z / VM 에 연결되어 있으며, 게스트 OS로 z / OS , z / VSE 등 다른, Linux 를 다수 운영 시키는 용도 (서버 통합)에서도 사용되고있다. 또한 국산 메인 프레임들도 동일한 가상화 OS (후지쯔 AVM, 히타치 제작소의 VMS 등)을 가지고있다.
- → 자세한 내용은 z / VM # 개발 경위 및 메인 프레임 # 종류 를 참조
서버 [ 편집 ]
여러 가지 요인에 의해, UNIX 와 Linux 서버 공급 업체 사이에서 가상화 기술이 다시 사용되게되었다.
- 하드웨어 능력의 확대에 의한 1 대당 동시에 처리 할 수있는 양의 증가
- 서버 군 조립을 통한 비용 절감 및 관리의 단순화.
- 대규모 멀티 프로세서 및 클러스터 서버, 즉 서버 팜 및 렌더 팜 에 설치를 관리 할 필요가 나왔다.
- 보안 및 안정성 개선과 하이퍼 바이저 아키텍처를 사용하여 장치에 의존하지 않아도되었다.
- 복잡한 OS에 의존하는 응용 프로그램을 다른 하드웨어와 OS 환경에서 작동하는 요구가있다.
IBM 과 썬 마이크로 시스템즈 , HP , SGI 등 주요 UNIX 벤더는 2000 년 이전보다 가상화 된 하드웨어를 판매하고 있었다. 이러한 하드웨어는 일반적으로 서버 클래스 (고급 수백만 달러)의 가격표를 달고있다. 가상화도 일부 미드 레인지 시스템, IBM의 System p 서버와 썬 마이크로 시스템즈의 CoolThreads의 T1000 및 T2000 서버에서 이용 가능하다.
IBM은 메인 프레임 용의 논리적 파티셔닝 ( LPAR )를 서버 ( pSeries , iSeries , Power Systems )에 이식했다. 현재는 게스트 OS의 정지없이 자원의 변경이 가능 (D-LPAR)에서 CPU (코어)는 10 분의 1 단위로 할당하므로 (마이크로 파티셔닝) 외에도 고급 이외의 모델에 탑재하고 있다.
산의 논리적 도메인 (LDOM) 하이퍼 바이저에서 게스트 OS로 동작시키기 위해 몇 가지 호스트 OS 변화가 이루어지고있다. 2006 년 후반에는 Solaris 및 Linux ,FreeBSD 는 하이퍼 바이저상에서 동작하도록 이식 된 (그리고 완전 가상화 게스트 OS에 관계없이 실현할 수있게 되었기 때문에, 동일한 프로세서에서 이러한 OS 가 동시에 동작 할 수있게되었다). Wind River의 Carrier Grade Linux 또한 산의 하이퍼 바이저상에서 동작하는 계획이다. SPARC 프로세서에서 완전 가상화를 실현하는 일은 그리 어려운 것은 아니다. 완전 가상화에 대한 노력이 1980 년대 중반부터 시작된 것으로, SPARC 아키텍처는 가상화 방해 오래된 구조를 신중하게 제거했기 때문이다.
비슷한 경향은 Linux 의 x86/x64 서버 플랫폼, Xen과 같은 오픈 소스 프로젝트에서 가상화 기술을 수중에 넣으려고하는 움직임이 보인다. 이 기술은 거대한 시스템에서 데스크탑에 이르고있다. 이에 대해서는 다음 절에서 설명.
" x86 가상화 "도 참조.
높은 이익을 자랑하는 서버 하드웨어 시장 분야에 관심을 가지고 있기 때문에 기존의 데스크톱 PC 를 포함한 Intel의 x86 명령 세트 컴퓨터 용 하이퍼 바이저의 개발이 이루어지고있다. 초기의 PC 용 하이퍼 바이저의 하나는 1998 년에 발표 된 상업용 VMware 이다. Parallels 사는 Parallels Workstation 을 2005 년에 발표했지만, 그 주된 용도는 PC에서 사용 것이었다. 2006 년에는 Mac OS X상에서 동작하는 Parallels Desktop for Mac 을 발표했다.
대부분의 PC 시스템에서 사용되는 x86 아키텍처는 특히 가상화가 어렵다. x86에서 (표준 하드웨어 세트라는 환상을 표현하는) 전체 가상화는 하이퍼 바이저가 너무 너무 복잡해 런타임 성능에 심각한 문제가 생긴다.
다른 방법으로는 하이퍼 바이저에 의해 시뮬레이션 된 시스템의 I / O 명령을 실행하는 것보다, 하이퍼 바이저에 시스템 콜을 발행하도록 게스트 OS를 변경하는 것을 요구한다. 이것은 Xen 에서 사용되는 반 가상화 라는 것이며, Parallels Workstation 에서는 "hypercall"라는 것이며, IBM의 가상 기계 는 "진단 코드"라는 것이다. VMware는 게스트의 장치 드라이버를 붙이는 것으로, 가상화시 가장 처리에 시간이 걸리는 곳을 보충하고있다. 이 모두는 같은 시스템 콜 하이퍼 바이저에 전달하고있다. Mach 및 L4 같은 마이크로 커널은 게스트 OS의 반 가상화하려면 충분히 유연하다.
CPU 업체들은 제품에 가상화 지원기구를 추가 해왔다. 인텔 의 가상화 기술 (Intel VT)와 AMD 의 AMD-V 는 원래 가상화에 어렵지하고 비효율적 인 x86 아키텍처를 확장하여 하이퍼 바이저의 실현을 지원하는기구이다. 이 구조는 가상화 코드를 더 단순하고 완전 가상화에서 더 높은 성능을 가능하게하는 것이다.
Xen과 같은 다른 것에 대해서는 가상 기계 를 소프트웨어만으로 구현하고있다. Xen은 Linux 와 같은 일반 호스트 OS에서 작동하는, 그리고 반 가상화 혹은 Intel VT를 사용한 (OS 변경을하지) 완전 가상화 모두 작동시킬 수있다. Xen은 무 변경 WindowsXP를 동작시키는 데모에 성공했다. Xen의 배포판은 수정 된 FreeBSD나 Linux , NetBSD , 벨 연구소 의 Plan9 버전이 이미 포함되어있다. 사용자 프로그램은 변경없이 Xen에서 실행이 가능하다.
2006 년, 마이크로 소프트는 새로운 Type1 하이퍼 바이저 시스템 인 코드 명 Viridian 개발을 시작, 2008 년 6 월 30 일 정식 버전을 Hyper-V 로 공개 한 [1] . 이 시스템은 최하층에서 OS와 통합하도록 설계되어있다. Windows Vista 를 비롯한 Windows 의 새로운 버전은 Viridian 하이퍼 바이저에서 실행 시켰을 경우에 성능을 올릴 확장을 포함한다.
임베디드 시스템 [ 편집 ]
가상 기계는 휴대폰 과 같은 임베디드 시스템 에서 최근 볼 수있게되었다. 이 문제는 한편, 동시에 기존의 실시간 운영 체제 (RTOS) API를 유지하면서, Linux 및Microsoft Windows 같은 응용 프로그램 프로그래밍의 높은 수준 OS 인터페이스를 제공하는 요구에 기인하고있다. 낮은 수준 RTOS 환경은 기존의 기능을 지원하기 위해 계속 유지할 필요가있다. 높은 수준 OS의 실시간 성능은 많은 임베디드 애플리케이션에 있어서는 만족스러운 것은 아니다.
따라서 임베디드 하이퍼 바이저는 실시간 성이 요구되어 그 설계 기준은 다른 분야에서 사용되고있는 하이퍼 바이저에는 적용되지 않는다. 많은 임베디드 시스템에서 사용할 수있는 자원이 미리 정해져있는 성질을 가져, 특히 배터리의 모바일 기기에서 더 작은 메모리 저소비 전력으로 동작하는 것을 요구된다. 결국 PC 세계에서는 x86 아키텍처가 도처에 존재하는 것과는 대조적으로, 임베디드 분야에서보다 폭 넓고 다양한 아키텍처를 사용하고있다. 가상화는 메모리 보호 기능 (메모리 관리 유닛 의 모양 또는 또는 최소한 아키텍처로 메모리 보호 기능이있는 것)와 CPU 모드 의 구분 (사용자 모드와 특권 모드) 기능이 필요하기 때문에, 많은 마이크로 컨트롤러 는 제외되어 버린다. 이 기능을 충족은 미들 레인지에서 하이 엔드 임베디드 시스템에서 널리 사용되는 x86과 MIPS , ARM , PowerPC 밖에 남지 않는다.
임베디드 시스템 제조업체들은 보통 자신들이 사용하고있는 OS의 소스 코드를 가지고 있기 때문에, 완전 가상화 의 필요성은별로 없다. 그러나, 반 가상화 는 성능이 좋은 장점이 있기 때문에, 보통 그것이 가상화 기술로 선택된다. 비록 ARM은 최근 TrustZone 기술을 이용한 전체 가상화 지원을 추가했다.
상업용으로 먼저 하이퍼 바이저가 내장 된 판매 된 모바일 임베디드 시스템은 OKL4 ( 도시바 모바일 폰)이다. 이것은 L4 마이크로 커널의 상업 버전이다. 이것은 x86과 ARM, MIPS 프로세서를 지원하고있다. 임베디드 시스템 용으로 사용되는 다른 시스템에 TRANGO이라는 것이 있고, ARM 및 MIPS, PowerPC를 지원하고있다. 마찬가지로 임베디드 시스템 용으로 VirtualLogix VLX가 x86-VT, ARM을 지원하고있다. VLX는 해외에서의 네트워크 인프라, 모바일 폰에서 채용 실적은 많다.준 국내 제품으로는 웰 인 테크놀로지 EM-VRT와 에루밋쿠 · 웨스코무 사 ACCEL 시리즈가 있으며, 국내에서 채용 실적이 많은 RTOS 인 ITRON 과 범용 OS 동시 실행을 가능하게하고있다. 또한 TOPPERS 프로젝트의 일환으로 개발 된 SafeG도 TrustZone 기술을 이용한 임베디드 구현 하나이다.
각주 [ 편집 ]
- ^ 해상忍( 2008 년 6 월 27 일 ). " 미 MS, 가상화 기술 "Windows Server 2008 Hyper-V"를 공식 발표 "(일본어). 마이 코미 쟈날. 2008 년 7 월 6 일 보기.
관련 항목 [ 편집 ]
외부 링크 [ 편집 ]
===================================================================================
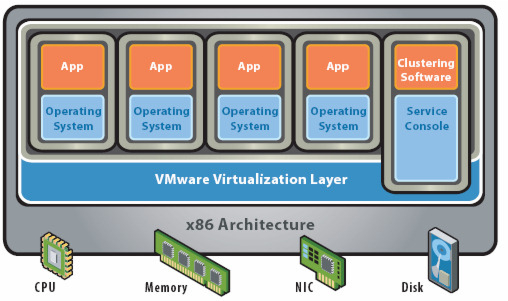
요즘 가상화 기술이 주목을 받고있죠. 그중에서도 서버의 가상화는 많은 회사들이 안고있는 하드웨어의 관리, 재난에 의한 시스템의 신속한 복구등 여러가지 문제를 해결해줄 수 있는 방법으로 각광을 받고있습니다. 이런 서버의 가상화는 하이퍼바이저, 가상OS, VMM(Virtual Machine Monitor=가상머신에 CPU나 기억장치 등의 리소스를 가상화하여 제공하는 소프트웨어,가상화 레이어라고도 함)라고도 불리며 크게 두가지 "Type1 (네이티브, 베어메탈 방식)"과 "Type2 (호스트형 방식)"으로 나눌 수 있습니다.
Type1 (일반적으로 하이퍼바이저(Hypervisor)형 가상화라고 불립니다.)
일반적으로 하이퍼바이저(Hypervisor)형 가상화라고 불립니다. 이 하이퍼바이저형 가상화는, VMM을 물리 컴퓨터의 하드웨어상에 직접 동작을 시키는 방법으로 호스트 OS가 필요없습니다.
호스트 OS에 할당할 리소스가 필요없기에 호스트형 가상화에 비해
오버헤드가 적고 물리 컴퓨터 리소스의 관리가 유연한게 특징입니다만, 자체적으로 관리기능을 갖고 있지않기에 별도의 관리콘솔(내지는 관리 컴퓨터)가 필요합니다.
이런 하이퍼바이저형 가상화 소프트웨어에는
VMware의
ESX/ESX i Server,
Citrix의
XenServer,
Oracle의
VM Server,
썬의
xVM Server,
마이크로소프트의
Hyper-V,
Virtual Iron의 Virtual Iron,
Parallels의
Parallels Server등이 있습니다.
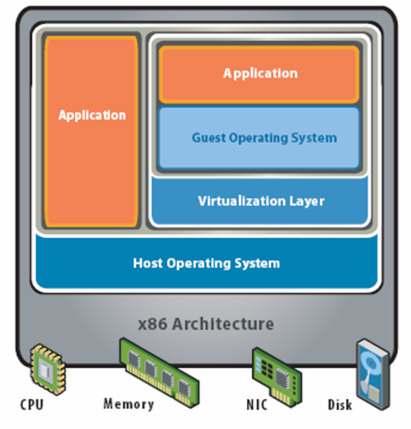
Type 2 (일반적으로 호스트(Hosted)형 가상화라고 불립니다.)
일반적으로 호스트(Hosted)형 가상화라고 불립니다. 이 호스트형 가상화는 물리 컴퓨터상의 호스트 OS위에 VMM(Virtual Machine Monitor)가 인스톨되어져 이 VMM위에 게스트 OS를 동작시키는 방법입니다.
이 호스트형 가상화는 물리 컴퓨터의 하드웨어를 에뮬레이트하기 때문에 오버헤드는 크지만, 게스트 OS의 종류에 그다지 제약이 없습니다. 그렇기 때문에 Windows에서
FreeBSD까지 다양한 게스트 OS를 동작시킬 수 있고, 물리 컴퓨터 역시 데스크톱뿐만이 아니라, 노트북에서도 동작합니다.
이런 호스트형 가상화 소프트웨어에는
VMware의
VMware Workstation,
VMware Server,
VMware Player,
마이크로스프트의
Virtual Server 2005 R2,
Virtual PC,
썬의
VirtualBox,
Parallels의
Parallels Workstation등이 있죠. 이 호스트형 가상화는 무엇보다도 손쉽게 도입이 가능하다는 점일겁니다.
PS 1>저도 몇년전부터 가상화에 관심을 두고 공부를 하고 있는 중이어서 알게된 정보를 이렇게 블로그에 남기고 있습니다. 읽다가 틀린 점이 있으면 알려주세요~
출처 - http://virtualhive.tistory.com/22
이전에 서버가상화의 종류에는 크게 두가지가 있다고 했습니다. 그중 하이퍼바이저형 가상화에는 또다시 전가상화와 반가상화로 나뉩니다.
전가상화(Full-Virtualization)
:전가상화는 하드웨어를 완전히 가상화하는 방식입니다. 하드웨어를 완전히 가상화하기 때문에 게스트 OS에 아무런 수정없이, 또한
Windows에서 Linux까지 다양한 OS를 이용할 수 있는 장점이 있습니다. 전가상화를 실현하기 위해서는 물리적인 가상화
지원기능, 즉 CPU의 VT(Virtualization Technology)를 이용할 필요가 있습니다만, 이 때문에 퍼포먼스의
저하가 발생한다는 단점이 생깁니다. 전가상화를 이용한 하이퍼바이저인 VMware의 ESX Server나 마이크로소프트의 Hyper-V 등의 하드웨어 전제조건중 CPU에 Intel-VT나 AMD-V의 기능이 필수인 점은 바로 이 때문입니다.
전가상화(Full-Virtualization)
반가상화(Para-Virtualization)
:전가상화와 달리 하드웨어를 완전히 가상화하지않습니다. 그렇기 때문에 게스트 OS가 직접 하드웨어를 제어하는 것이 아니라, 하이퍼바이저에게 의뢰, 하이퍼바이저가 제어를 하기에 높은 퍼포먼스를 유지할 수 있습니다.
Xen이 주목을 받고있는 이유중 하나죠.
물론 반가상화도 단점이 있습니다. 반가상화를 실현하기 위해서는 게스트 OS의 커널의 일부분을 수정해야 한다는 점입니다. 그렇기
때문에 이용할 수 있는 게스트 OS는 오픈소스에 한정되어있습니다. 마이크로소프트가 소스를 공개하지않는한 말이죠. 흐흐
반가상화(Para-Virtualization)
출처 - http://virtualhive.tistory.com/36