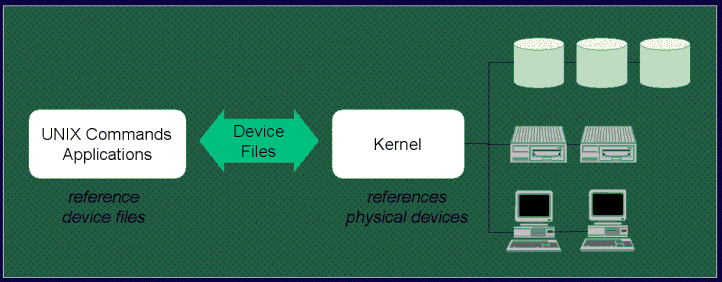
RAC (Real Application Cluster)
RAC (Real Application Cluster) : DB 서버의 장애를 대비해서 DB 서버를 2대 이상 설치하는 것. 2대의 DB서버의 내용은 반드시 같아야 한다.
Clusterware : DB 서버를 관리해주는 프로그램. RAC 내에서 어떻게 작동하고 관리하는지 알아야한다. Clusterware를 관리하는 것이 어렵다.
※ DB 서버를 하나 설치 하는 것을 Single 이라고 한다. 2대 이상 설치하는 것을 RAC.
모든 DB는 instance(memory)와 Database(저장소)가 존재한다.
CRS(Cluster Ready Services)프로그램 : 사용자가 DB에 접속을 할 경우 직접 DB로 접속되는 것이 아니라 CRS로 접속하여 CRS가 node1과 node2 중
어느 node 로 접속 할 지를 분배해 준다. CRS 데몬은 어떠한 장비가 살아있고 죽어있는지의 상태를 모두 알고 있어야 한다.
그리고 자기가 관리하는 서버의 IP 및 서버가 몇 대가 있는지를 알고 있어야 한다. 이러한 정보들을 OCR 이라는 파일에 저장되어 있다. Cluster ware 에 CRS 프로그램이 포함되어 있는 것이다. CRS는 엔진에 CRS라는 Directory가 생성되고 그 안에 설치가 된다.
OCR : 모든 자원(instance) 들을 관리한다.
Vote : instance 의 활성 , 비활성 상태를 저장하고 있는 파일. CRS 가 이 파일을 보고 정보를 얻는다
Oracle Parallel Server (OPS) oracle 8i
DB 서버의 병렬 : RAC의 모태라고 생각하면 쉽다.
가
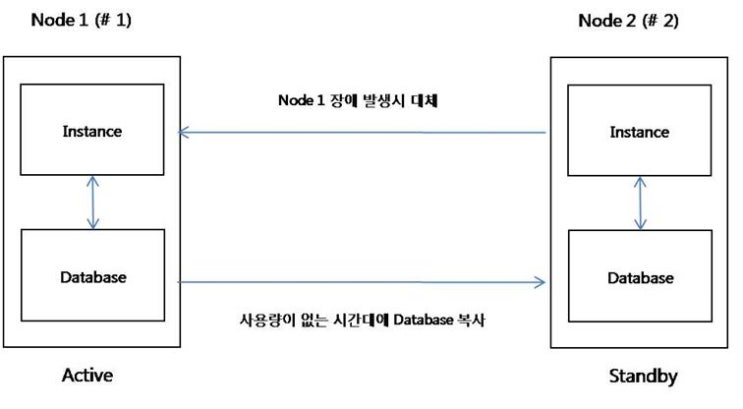
격대비 효과가 없다. 장애 발생시에만 효과가 있다. Standby DB는 평소에는 사용되지 않다가 장애가 발생시에만 대체가 되기
때문이다. 평소 active 상태인 node1 만 사용하기 때문에 node1에 부하가 일어날 수 있다. 또한 평소에는 DB의
사용량이 많기 때문에 사용량이 없는 시간(야간)에 node1 의 내용을 node2 에 복사한다. 만약 node 1의
instance가 장애가 발생하면 standby 상태인 node 2 의 instance 가 대체 된다.
Q) node 1 과 node 2 의 내용은 항상 같을까??
A) 항상 같을 수가 없다. 하드 디스크가 따로 나뉘어져 있기 때문에 항상 같을 수가 없다.
RAC
OPS 의 단점을 보안하여 나온 기술
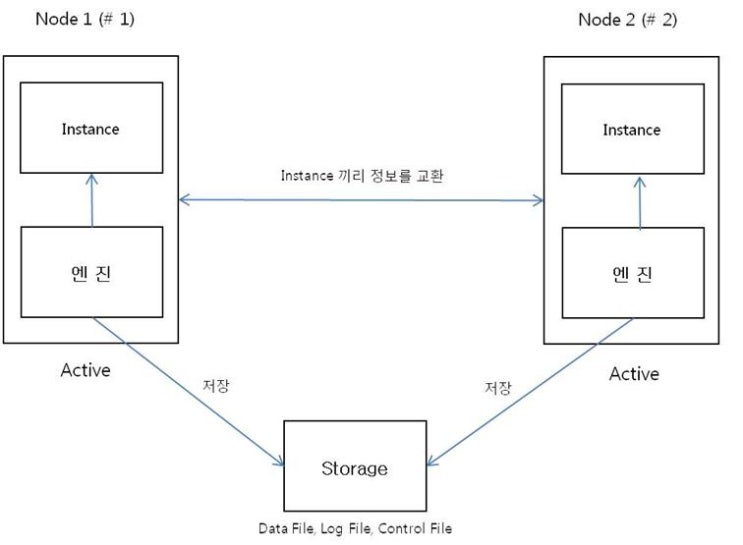
하드 디스크(Storage)를 하나를 둔다. Node 1에서 작업을 하거나 node2 에서 작업을 하거나 저장은 하나의 하드디스크에 저장한다. 그리고 2개의 DB 서버 모두 Active 상태이다.
Node1, Node2 모두 activy 상태이기 때문에 부하가 OPS 보다 적게 발생한다.
엔진은 각각 깔고, 사용자가 저장하는 파일들만 하드 디스크에 저장된다. Data file, Log file, Control file 등이 하드디스크에 저장이 된다. Node 에는 엔진만 설치 되어 있다.
인스턴스 끼리 정보를 주고 받는다.
RAC
구축시 하나의 서버만 DB를 구축한 후 다른 node에 copy해서 서버 이름만 봐꾸어 주면 된다. 그 후에 node1,
node2를 불러오면 RAC가 구축되는 것이다. CRS는 하나의 DB서버에만 설치하면 설치 완료후에 프로그램이 자동으로
node2에 설치를 하게 된다. 이때 node 1과 node2간의 통신을 할 때 암호를 묻지 않도록 설정을 해놓아야 한다.
RAC 를 설치할 때 가장 어려운 관문
1. Network 설정.
2. Disk 설정.
가장 중요하다.
Network 설정
RAC 에서 사용하는 network 의 종류는 3가지가 있다. 이 3가지 IP 의 차이를 알아보자.
서버 하나당 LAN 카드 2개 IP는 3개가 필요하다.
Node
1 과 node 2 는 반드시 통신이 되어야 한다. VIP 는 CRS가 설치된 후에 작업을 하기 때문에 설치 후에
network가 되면 된다. public 은 public끼리 통신이 되어야 한다. Private는 private , vip는
vip 끼리 통신이 되어야 한다.
/etc/hosts 파일에 node1 과 node2의 IP를 기입해 주어야 한다.
IP 종류
1. public IP : 외부에서 관리자가 접속하는 IP.
2. private IP (Inter Connect)
: Instance 끼리 정보를 주고 받는다. 이때 사용하는 IP가 private IP이다. Node1 과 Node2 가 통신할
때만 사용되는 IP이다. 사용자가 쓰는 것이 아니라 CRS가 instance 끼리 통신하는데 사용한다. 외부에서 접근이 되지
않는다. 그렇기 때문에 private IP는 사설 IP를 많이 부여해 준다.
3. virtual IP : CRS 가 로드밸런싱 할 때 쓰는 IP
한 서버에 LAN 카드가 총2개라고 하였다.
VIP와public이 LAN 카드 하나를 동시에 같이 사용하고, private 가 남은 LAN카드 하나를 사용한다.
Q) 관리자가 관리 용도로 or 장애 복구 용도로 putty 또는 ssh 로 접속할 때 사용하는 IP가 Public IP 이다.
Q)
A 사용자가 Node1에 접속하여 홍길동을 검색하는 select문을 날렸다. 헌데 Node 1 에 instance에는
홍길동이라는 것이 없고, storage에 있다. 그런데 node2를 보니 instance에 홍길동이 있다. 이럴때는
storage에서 instance로 올리는 것보다 instance에서 받는 것이 빠르기 때문에 node2 의 홍길동을 전달
받는다. RAC는 instance를 서로 공유하여 사용한다. 이때 사용하는 IP가 private IP 이다.
Disk 설정
File System : 하드디스크를 운영체제가 관리하는 방식. 응용프로그램(oracle)이 os 에게 디스크의 데이터 I/O를 요청한다.
장점 - 관리가 쉽다. 단점 - 속도가 느리다
Raw Device : 응용프로그램이 운영체제(OS)를 거치지 않고 직접 Storage에 I/O를 일으킨다.
장점 - OS 를 거치지 않기 때문에 속도가 빠르다. 단점 - 관리하기가 힘들다.
Raw Device 명령 = dd
ASM(Automatic Storage Management) : file system과 Raw Device의 단점을 보완. 편리성도 좋고 더 빠르다. Oracle에서 만든 하드디스크를 관리하는 명령.
RAC를 구현하는 방식에는 위처럼 3가지 방식이 있다. 10g 에서는 보통 Raw Device, 11g 에서는 무조건 ASM으로 RAC를 구현한다.
LVM : 물리적인 여러 디스크를 하나의 논리적인 디스크로 만들어 주는 기술. Raw Device 와 잘 구분해야 한다.
RAC 설치 순서
OS = RHEL 4, Node 1개당 Memory 는 700mb씩 부여
1. OS 설치 – 환경 설정 (node 2개를 동시에 올리는 것 까지)
2. CRS 설치(10.2.0.1) à CRS 패치(10.2.0.4)
3. 엔진 설치 → 엔진 패치
4. netca
5. ASM 설치 → 패치 (Raw Device일 경우 제외)
6. DB 생성 (dbca)
출처 - http://blog.naver.com/dlsrjsl?Redirect=Log&logNo=30107305077
==============================================================
제 1장. RAC(Real Application Cluster)
1. GRID/RAC 개념
1) GRID의 개념
- 사용자가 원하는 데이터가 어디에 있는지, 어떤 컴퓨터가 요청을 처리하는지는 몰라도 원하는 만큼
의 정보를 처리할 수 있음
- 기업의 IT환경에 적용해 보면, 기업내에 산재해 있는 소형 서버들을 연결하여 커다란 컴퓨터 처럼
사용한다는 개념
■ 자원할당 : 자원을 요청하고 필요로 하는 누구든지 원하는 것을 얻을 수 있도록 하는것
■ 정보공유 : 사용자와 Application이 필요로 하는 정보는 언제 어디서나 필요에 따라 이용할 수
있도록 해주는 것
■ 고가용성
- GRID컴퓨팅의 필요성
저렴한 가격으로 기업의 인프라를 효율적으로 활용 할 수 있는 최적의 솔루션
- Oracle GRID 컴퓨팅
기업내 존재하는 중소형 서버들을 GRID 기술로 연결해 유휴 자원을 활용한다는 것
저비용 고효율을 강조하는 기업환경에서 오라클 GRID컴퓨팅 기술을 통해 저렴한 여러개의 서버를
연결시켜 하나의 커다란 서버로 활용가능
그렇기 때문에 고려하여 무리하게 서버를 구입할 필요가 없어짐
Oracle 10g의 g가 GRID의 g
2) RAC 개념
- Oracle Real Application Cluster는 OPS(Oracle Parallel Server)의 후속 제품으로 개발되어
Oracle 9i 버전부터 적용되어 있다
- 동일 데이터베이스를 여러 인스턴스가 접근할 수 있다
- 모든 노드가 동일한 데이터베이스에 접속가능하다
- 데이터베이스 디스크는 모든 노드가 Database에 access를 허용하기 위해 전역으로 사용해야 함
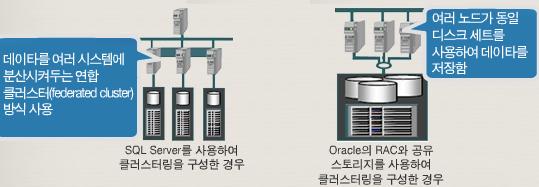
2) RAC의 장점
■ 확장성
- 데이터의 증가로 인한 시스템부하를 발생하면 더 큰 시스템을 구매하고 이관하는데 많은
비용이 소모되었다
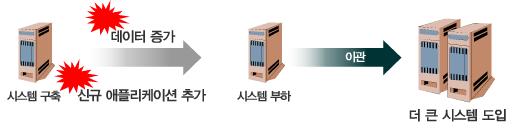
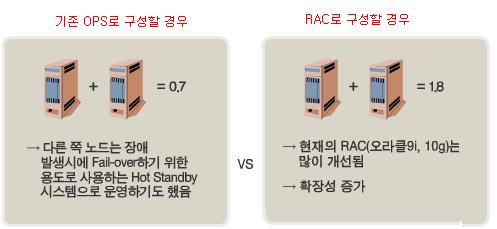
■ 고가용성
- Rolling Patch, Rolling Upgrade로 서비스 정지를 최소화 시켜줌
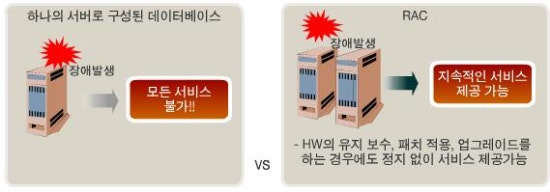
2. RAC구조 및 동작원리
1) RAC구조
물리적인 하나의 데이터베이스를 여러대의 서버가 공유하는 것
모든 노드들은 같은 데이터를 사용하게 되어 논리적으로는 하나의 데이터베이스를 이용하는 것임
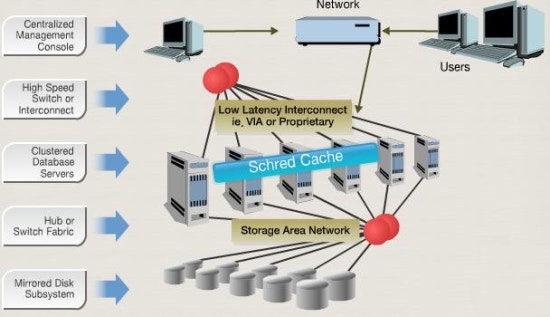
[ 노드 3개를 이용하여 RAC를 구성한 예 ]
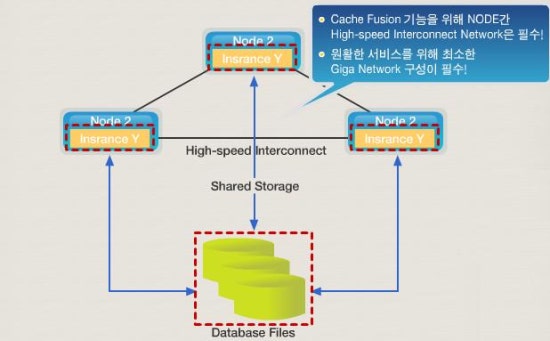
[ 최적의 구성예 ]
3. RAC 구성 시 고려사항
1) RAC 내 공유 오브젝트의 관리

[ 설계방향 ]
- 인스턴스별로 사용하는 오브젝트에 대한 파티션 나누기
: 공유테이블 생성시 경합을 최소화 하기 위해 extent 를 인스턴스별로 할당한다
: 시퀀스 같이 공유하는 오브젝트의 캐시값을 증대시킨다
- LOCK의 배분을 조절(init.ora의 gc_files_to_lock, gc_rollback_segment 등)
: 공유 오브젝트를 중점 관리 테이블스페이스에 집중화 하고, 이 테이블스페이스에 많은
LOCK을 할당한다
: 조회 위주의 데이터와 전혀 공유하지 않는 데이터(한 노드에서만 사용하는 데이터) 에는
LOCK을 최소화 한다
- 동시에 같은 데이터를 액세스 하는 애플리케이션은 한 노드에서 수행하도록 하는 어플리케이션
파티셔팅
: 동일한 어플리케이션은 같은 노드에서 수행하도록 배치한다
: 업무별로 그룹핑하여 노드간에 경합이 없도록 한다
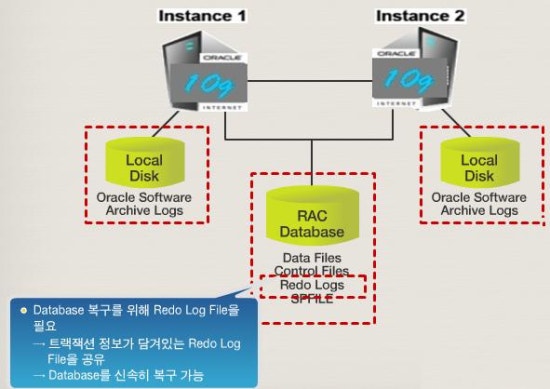
2) 인스턴스 장애 시 복구요구 시간 산정
- 하나의 노드에 장애가 발생 했을때 얼마나 빠른 시간내에 서비스를 할수 있는가에 대한 요구사항을
기반으로 인스턴스 복구 시간을 고려해 구성해야 함
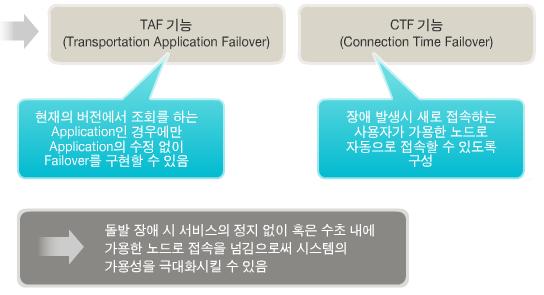
3) 어플리케이션 서비스의 자동복구 요구
- 돌발 장애시 사용자가 모르게 복구되기를 원한다면
4) 자원의 효율적인 사용요구
- 많은 사용자가 시스템 사용시 모든 노드가 균일하게 사용하도록 해야 한다