다음 글은 다음 논문에 대한 요약이다. 자바의 RMI 가 이 때의 RPC에서 얼마나 발전한 메커니즘인지를 여실히 알게해 주는 글이었다.
Andrew D. Birrell and Bruce J. Nelson
Xerox Palo Alto Research Center
Published: ACM Transactions on Computer Systems, Vol. 2, No. 1,
February 1984, pages 39-59.
Goals
Simplicity
- Make RPC as similar to procedure calls as possible simple semantics easy to understand
- Make distrusted computation easier
Efficiency
- Make sematic of RPC package as powerful as possible without losing efficiency
Security
- Secure end-to-end communications with RPC
Generality
- Procedures are well-known type
Procedure Calls:
Transfer of control and data within a program
Remote Procedure Calls (RPC):
Extend procedure calls across communication network
Caller:
Environment that invokes RPC
Callee:
Environment where procedure is to execute
Basic RPC Mechanism
- Caller invoke a remote procedure and get suspended.
- Parameters are passed across the network to the Callee.
- Callee executes the procedure and produce results.
- Results are passed back to the caller and caller resumes execution.
The authors wanted their implementation of this concept to be relatively transparent to the programmer,
so that an RPC call would look and feel semantically like a local procedure call.
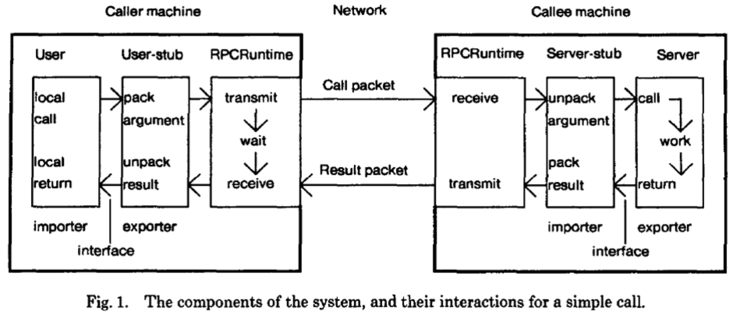
Structure
Five pieces involved: user, user-stub, RPC communications package (RPCRuntime), server-stub, the server.
User
include server’s ID and unique sequence number with each call
specify or select server from available list or bind statically by network address
writes interface, client, and server code but doesn’t need to write any code for communication mechanism
RPC Runtime
manages communication between machines/processes
stub of user and server
- Server and client link to programmatically generated stubs of a common interface module at compile time
- stubs pack and unpack the requiring and required procedure call's network data
user stub
- imports the exported procedure's prototypes
server stub
- exports the prodecures
Server
register their exported interfaces with secure database servers
returns results to separate address space
executes the called procedure
Binding
- Naming and Location
Naming: Specifying what machine to bind to.
Location: Determining machine address of the callee and specifying the procedure to be invoked using Grapevine database
- Interface
The caller needs to bind to a callee that can perform the remote procedure. This is specified for the callee
by the abstraction that the authors call an interface.
An interface consists of two components:
(1) Type – specify which interface the caller expects the callee to implement.
This concept is similar to an object oriented programming interface
(2) Instance – specify which particular implementer of an abstract interface is desired.
The instance is similar to an object that implements the OOP interface.
- Binding Types
- Decision about instance made dynamically
- Specify type, but dynamically pick instance
- Specify type and instance at compile time
- Binding Events
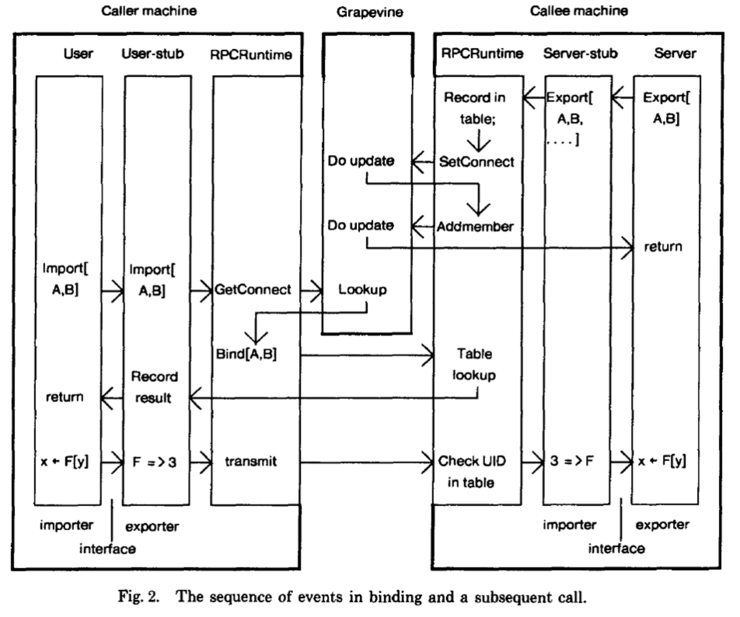
Exporter: specifies network address, identifier and table index
Importer: iterates through member list returned by Grapevine
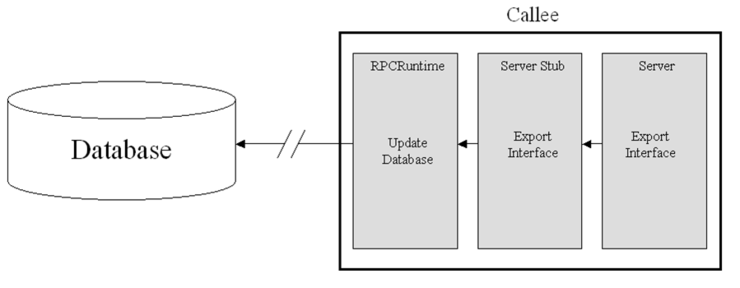
- Binding Events on Callee
+ The caller binds to the callee by specifying something to uniquely identify the callee (Naming in this case) and
the callee’s location.
+ But first the caller must find out what callees are available to handle the request at the time of the procedure call.
This is accomplished by a database lookup:
+ When a callee wishes to export an interface (make it available to callers), it stores information about its
interface in a network accessible database.
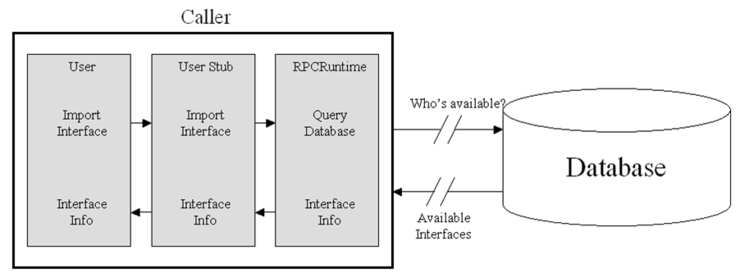
-Binding Events on Caller
The caller can then find the server callee in a database lookup:
By specifying a particular instance of the desired interface type and receiving location information
about that instance, or
By specifying the type of the interface and receiving a list of instances that implement that type,
and then iterating through them to find an available match.
Protocol
The protocol used is intended for small, discrete chunks of data, each of which can contain
- Identifiers specifying caller, callee and call
- Requested procedure and procedure arguments
- Procedure results
- Acknowledgements of received packets
- Exception information
Note: a caller may send requests for acknowledgement to the callee, and as long as the callee responds,
the caller may wait indefinitely for results if the remote procedure deadlocks or loops (just like local procedure calls).
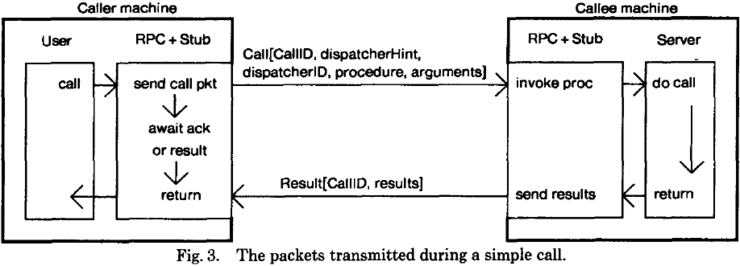
- Simple Calls
Retransmission of a packet (either from caller or callee) occurs until an acknowledgement is received.
To the caller, a received packet containing the procedure results is viewed as an acknowledgement.
To the callee, a received packet containing a new procedure call is viewed as an acknowledgement of
the last procedure result sent.
Each call by the caller carries a unique identifier so that subsequent calls to the same procedure
may be processed, but duplicate packets (from retransmissions) for the same call will be discarded.
Any given caller (process or thread on a given machine) will have at most one outstanding remote call.
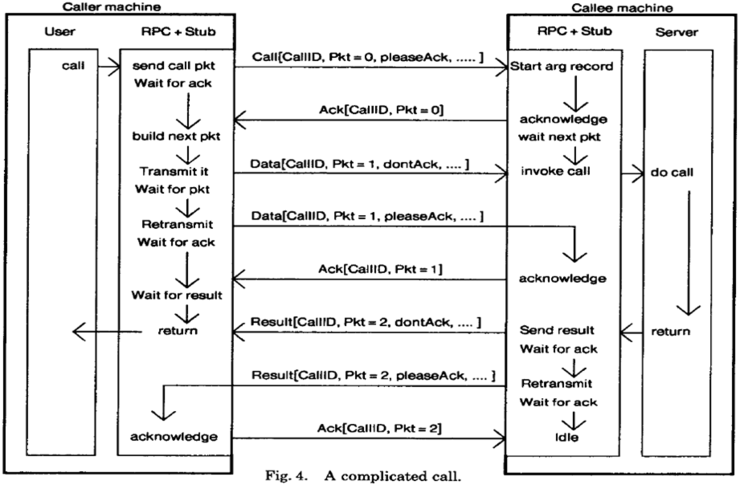
- Complicated Calls
An acknowledgement is expected for each packet sent.
The caller may send additional packets, called probes, if the callee is taking a long time to send results.
After a certain threshold of probes sent without an acknowledgment, the caller may raise
an exception to the user about a communication failure (again, a deadlocked callee can’t be detected). -- not good of extra overhead
If the contents of a packet (procedure arguments or return results) are too large to fit in one packet,
multiple packets are sent with all but the last requiring acknowledgement before transmission of the next.
Each packet is sequentially marked.
Advantages of RPC protocol
- Minimal per-connection setup and teardown costs
- Minimal state when connection is idle
Server just keeps last sequence number
Client has a list of server addresses & IDs
- Minimize delay between RPC request and response – no handshaking phase
- No idle time communication, i.e.: keep-alive packets
Exceptions
Exceptions for RPC are published in a server’s interface along with all of the normal procedure calls.
Propagating any exceptions back to the caller and any handlers waiting there to catch them.
Callee can transmit an exception instead of result packet. Exception packet is handled as new call packet.
RPCRuntime call failed exception, raised by the callee raised when there are communication difficulties.
Processes - optimizations
Processes:
A server callee maintains a pool of available server processes to handle incoming requests:
- This saves the cost of creating a new process to handle each request.
- A new process is created to handle a new request when the available processes are busy.
- To save on the costs of context switches between processes, each packet contains Ids of calling and serving processes.
Optimizations:
- Minimize the costs of maintaining connections.
- Avoid costs of establishing and terminating connections.
- Reduce the number of process switches involved in a call.
Other Optimizations:
- Use the subsequence packet as ACK
- Bypass software layer if within same network
Security
- Encryption end to end – based security for calls
- Garpevine can be used as an authentication server
in failure
- Machine failures are handled by re-transmission and re-binding.
- Mesa
has an exceptions and catch mechanism that RPC runtime passes back
exception packets. (only pass back exceptions defined in I/F)
Performance
- Measurements made for remote calls between two Dorados computers connected by Ethernet (2.94 Mbps)
- Ethernet shared with other users, but the network was lightly loaded.
- Did not use any encryption facilities.
- 12000 calls made on each procedure.
- Interval timed is from the time the user invokes a local procedure to the return of the procedure call.
- Performance Summary:
Mainly RPC overhead – not due to local call
For small packets, RPC overhead dominates
For large packets, transmission time dominates
Environment
Cedar:
developing and programming environment. Designed to be used on
single-user workstation. Also used for the construction of servers.
Dorado:
Powerful machine with 24 bit virtual address space.
Network:
2.94 megabit / sec Ethernet
Protocol:
PUP
Language:
Mesa (modified for the purpose of Cedar)
출처 - http://blog.naver.com/ahtz?Redirect=Log&logNo=20116355337
'System > Common' 카테고리의 다른 글
| linux - File Descriptor (0) | 2011.12.12 |
|---|---|
| Character Device File vs Block Device File (0) | 2011.12.08 |
| 심볼릭 링크 vs 하드링크 (0) | 2011.12.08 |
| 솔라리스와 리눅스 런레벨 비교 (0) | 2011.12.05 |
| 파일 시스템 구조 (0) | 2011.12.04 |