1.1 변수란?
컴퓨터 언어에서 변수(variable)란, 값을 저장할 수 있는 메모리상의 공간을 의미한다. 계산을 하기 위해서 변수를 사용하지 않고 값을 직접 사용할 수도 있지만, 의미있는 이름의 변수에 저장하여 사용하는 것이 더 바람직하다.
변수의 값은 바뀔 수 있으며, 하나의 변수에는 단 하나의 값만을 저장할 수 있다. 그래서 값을 여러 번 저장하면 마지막에 저장한 값을 갖게 된다.
1.2 변수의 선언
변수를 사용하기 위해서는 먼저 변수를 선언해야한다. 변수가 선언되면 메모리 공간에 변수의 타입에 알맞은 크기의 메모리공간이 확보되어, 값을 저장할 준비가 되는 것이다.
변수를 선언하는 방법은 다음과 같다.
변수타입 변수이름; int number; // 정수형 변수 number를 선언한다. |
변수를 선언할 때는 변수의 타입과 이름을 함께 써주어야 한다. 위의 예는 number라는 이름의 정수형 변수를 선언한 것이다. 변수타입은 변수에 담을 값의 종류와 범위를 충분히 고려하여 결정해야한다.
변수를 선언한 후부터는 변수를 사용할 수 있으며, 변수를 사용하기에 앞서 적절한 값을 저장해주는 것이 필요하다. 이것을 변수의 초기화라고 하는데, 보통 아래와 같이 변수의 선언과 함께 한다.
// 정수형 변수 number를 선언하고 변수의 값을 10으로 초기화 했다. int number = 10; // 위 문장은 아래의 두 문장과 동일하다. int number; number=10; |
변수의 종류에 따라 변수의 초기화를 생략할 수 있는 경우도 있지만, 변수는 사용되기 전에 적절한 값으로 초기화 하는 것이 좋다.
[참고] 지역변수는 사용되기 전에 초기화를 반드시 해야 하지만 클래스변수와 인스턴스변수는 초기화를 생략할 수 있다. 변수의 초기화에 대해서는 후에 자세히 학습하게 될 것이다.
1.3 명명규칙(Naming Convention)
변수의 이름, 메서드의 이름, 클래스의 이름 등 모든 이름을 짓는 데는 반드시 지켜야 할 공통적인 규칙이 있으며 다음과 같다.
1. 대소문자가 구분되며 길이에 제한이 없다. - True와 true는 서로 다른 것으로 간주된다. 2. 예약어를 사용해서는 안 된다. - true는 예약어라서 사용할 수 없지만, True는 가능하다. 3. 숫자로 시작해서는 안 된다. - top10은 허용하지만, 7up는 허용되지 않는다. 4. 특수문자는 '_'와 '$'만을 허용한다. - $harp은 허용되지만, S#arp은 허용되지 않는다. |
[참고]예약어는 keyword 또는 reserved word라고 하는데, 프로그래밍언어에서 구문에 사용되는 단어를 뜻한다. 그래서, 예약어는 이름으로 사용될 수 없다.
예약어는 앞으로 차차 배워 나가게 될 것이므로 지금은 간단히 훑어보는 보는 정도면 충분하다.

[표2-1]자바에서 사용되는 예약어
[참고] 이 밖에도 goto와 const가 더 있지만 사용되지 않는다.
그 외에 필수적이지는 않지만, 자바프로그래머들에게 권장하는 규칙들은 다음과 같다.
1. 클래스 이름의 첫 글자는 항상 대문자로 한다. - 변수나 메서드의 이름의 첫 글자는 항상 소문자로 한다. 2. 여러 단어로 이루어진 이름은 단어의 첫 글자를 대문자로 한다. - lastIndexOf, StringBuffer 3. 상수의 이름은 모두 대문자로 한다. 여러 단어로 이루어진 경우 '_'를 사용하여 구분한다. - PI, MAX_NUMBER |
위의 규칙들은 반드시 지켜야 하는 것은 아니지만, 코드를 보다 이해하기 쉽게 하기 위한 자바 프로그램들간의 암묵적인 약속이다. 가능하면 지키도록 노력하자.
[참고] 자바에서는 모든 이름에 유니코드에 포함된 문자들을 사용할 수 있지만, 클래스이름은 ASCII코드(영문자)로 하는 것이 좋다. 유니코드를 인식하지 못하는 운영체계(OS)도 있기 때문이다.
변수 타입
기본형의 개수는 모두 8개이고, 참조형은 프로그래머가 직접 만들어 추가할 수 있으므로 그 수가 정해져 있지 않다. 참조형 변수를 선언할 때는 변수의 타입으로 클래스의 이름을 사용하므로 클래스의 이름이 변수의 타입이 된다. 그러므로 새로운 클래스를 작성한다는 것은 새로운 참조형을 추가하는 셈이다. 다음은 참조변수를 선언하는 방법이다.
Date클래스 타입의 참조변수 today를 선언한 것이다. 참조형 변수는 null 또는 객체의 주소를 값으로 갖으며 참조변수의 초기화는 다음과 같이 한다.
객체를 생성하는 연산자 new의 연산결과는 생성된 객체의 주소이다. 이 주소가 대입연산자(=)에 의해서 참조변수 today에 저장되는 것이다. 이제 참조변수 today를 이용해서 생성된 객체를 사용할 수 있게 된다. [참고]기본형은 저장할 값(Data)의 종류에 따라 구분되므로 기본형 변수의 종류를 얘기할 때는 자료형(Data Type)이라는 용어를 쓰고, 모든 참조형은 종류에 관계없이 4 byte의 주소(0x0 ~ 0xffffffff 또는 null)을 저장하기 때문에, 참조형 변수들은 값(Data)이 아닌, 어떤 객체의 주소를 담을 것인가에 따른 객체의 종류에 의해서 구분되므로, 참조형 변수의 종류를 구분할 때는 자료형(Data Type)대신 타입(Type)이라는 용어를 사용한다. 타입이 자료형을 포함하는 보다 넓은 의미의 용어이므로 반드시 구분해서 사용할 필요는 없다. 2.1 기본형(Primitive Types) 기본형에는 모두 8개의 타입이 있으며, 크게 논리형, 문자형, 정수형, 실수형, 4가지로 구분된다.
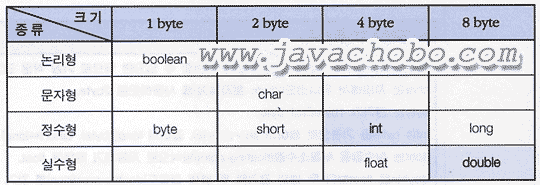 [표2-2]기본형의 종류와 크기 [참고] 4개의 정수형(byte, short, int, long)중에서 int형이 기본(default) 자료형이며, 실수형(float, double)중에서는 double형이 기본 자료형이다. 논리형인 boolean은 나머지 7개의 자료형과 연산이 가능하지 않지만, char는 문자를 내부적으로 정수값 코드로 저장하고 있기 때문에 정수형과 밀접한 관계가 있다. 정수형과 실수형의 경우에는 여러 개의 변수형이 있지만, 특별히 큰 값을 다루어야 하지 않는 한 int 와 float를 주로 사용한다.  [표2-3] 8가지 기본형(Primitive Type)과 저장 가능한 값의 범위 [참고] float와 double의 음의 최대값과 최소값은 양의 최대값과 최소값에 각각 음수 부호를 붙이면 된다. 실수형은 소수점이하의 자리수, 즉 정밀도가 중요하기 때문에, 얼마나 0에 가까운 값을 표현할 수 있는지도 큰 의미를 갖는다. 각 자료형이 가질 수 있는 값의 범위를 정확히 외울 필요는 없고, 정수형(byte, short, int, long)의 경우 -2n-1~ 2n-1-1(n: bit수)이라는 정도만 기억하고 있으면 된다. 예를 들어 int형의 경우 32bit(4byte)이므로 -231~ 231-1의 범위를 갖는다. 210=1024≒103이므로 231=210*210*210*2 = 1024 * 1024 * 1024 * 2 ≒ 2 * 109 따라서, int형은 대략 9자리수(약 2,000,000,000)의 값을 저장할 수 있다는 것을 알 수 있다. 9자릿수에 가까운 자리수(7자리나 8자리)의 수를 계산할 때는 넉넉하게 long형(약 19자리)을 사용하는 것이 좋다. 연산 중에 저장범위를 넘어서게 되면 원하지 않는 값을 결과로 얻게 될 것이기 때문이다. 정수형에서 int를 실수형에서는 float를 주로 사용하므로, int와 float의 범위를 기억해서, int와 float의 범위를 넘는 값을 다뤄야 할 때 long과 double을 사용하면 된다. 기본 자료형의 크기를 쉽게 외우는 방법은 다음과 같다.
2.2 논리형 - boolean 논리형에는 boolean, 한가지 밖에 없다. boolean형 변수에는 true와 false 중 하나를 저장할 수 있으며 기본값(default)은 false이다. boolean형 변수는, 대답(yes/no), 스위치(on/off) 등의 논리구현에 주로 사용된다. 그리고, boolean형은 true와 false, 두 가지의 값만을 표현하면 되므로 기본형 중에서 가장 크기가 작은 1 byte이다. [참고] 1 byte는 8 bit이므로 2의 8제곱, 256가지의 값을 표현할 수 있다. 따라서 boolean형은 크기가 1byte이므로 256가지의 값을 표현할 수 있으나, true와 false, 2가지의 값만을 표현하는데 사용되고 있다. 아래 문장은 power라는 boolean형 변수를 선언하고 true로 변수를 초기화 했다.
[주의] Java에서는 대소문자를 구별하기 때문에 TRUE와 true는 다른 것으로 간주하므로 주의하도록 한다. 2.3 문자형 - char 문자형 역시 char 한가지 밖에 없다. 기존의 많은 프로그래밍의 언어에서 문자형의 경우 1 byte(ASCII코드)의 크기를 갖지만, Java에서는 유니코드(Unicode)문자 체계를 사용하기 때문에 크기가 2byte이다. [참고] Unicode는 세계 각 국의 언어를 통일된 방법으로 표현할 수 있게 제안된 국제적인 코드 규약이다. 미국에서 개발되어진 컴퓨터는 그 구조가 영어를 바탕으로 정의되어 있기에 26자의 영문 알파벳과 몇 가지 특수 문자를 표현하기에는 1바이트로 충분하였기 때문에 모든 정보(문자)가 1바이트를 단위로 표현되고 있었으나 동양3국의 언어 표현인 한글, 한자 또는 일어 등과 같은 문자는 그 구조가 영어와 달라서 1 바이트로는 표현이 불가능하기에 2바이트로 조합하여 하나의 문자를 표현하는 컴퓨터의 구조적 문제점을 바탕으로 유니코드가 만들어 졌다. 유니코드에 대한 보다 자세한 내용은 원한다면,http://www.unicode.org/standard/translations/korean.html을 방문해보도록 하자. [참고]아스키는 128개의 가능한 문자조합을 제공하는 7비트(bit) 부호로, 처음 32개의 부호는 인쇄와 전송 제어용으로 사용된다. 보통 기억장치는 8비트(1바이트, 256조합)이고, 아스키는 단지 128개의 문자만 사용하기 때문에 나머지 비트는 특수문자에 사용된다. char형의 크기는 2 byte이므로 16진수로 0000부터 ffff까지, 문자를 표현하는데 65536개(2의 16제곱)의 코드값을 사용할 수 있으며, char형 변수는 이 범위 내의 코드값 하나를 저장할 수 있다. 예를 들어 알파벳 A의 유니코드값은 0041이다. char형 변수에 문자 A를 저장하려면 아래와 같이 한다.
char형 변수 firstLetter를 선언하고, 문자 A를 저장했다. char형 변수에 문자를 저장할 때는 "(홑따옴표)로 문자를 둘러싼다. 두 번째는 문자의 코드를 이용해서 문자형 변수 firstLetter에 값을 저장했다. 문자형 변수에 값을 저장하는 데는 위의 두 가지 모두 가능하지만, 주로 첫 번째 방식으로 문자를 저장한다. 다음은 char형이 저장되는 방식을 short형과 함께 비교해 보았다. 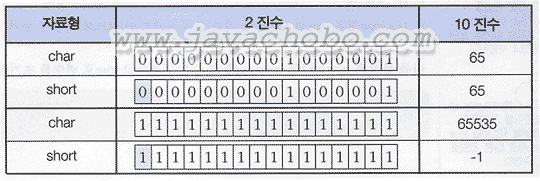 [표2-4]char형과 short형의 값 비교 char형이나 short형은 크기가 모두 2 byte(16 bit)지만, 범위가 다르다. char형은 0~65535이고 short형은 -32768~32767이다. 하지만, 둘 다 2 byte이기 때문에 표현할 수 있는 수는 65536개로 같다. char형은 문자의 코드값을 저장하므로 음수를 필요로 하지 않기 때문에 2진수로 표현했을 때의 첫 번째 자리를 부호에 사용하지 않는다. 반면에 short형은 첫 번째 자리를 부호를 표현하는데 사용하기 때문에 서로 다른 범위를 갖게 되는 것이다. 이처럼 char형은 정수형과 표현방식이 같기 때문에 정수형과 깊은 관계가 있다. 만일 어떤 문자의 코드값을 알고 싶으면, char형 변수를 정수형(int)으로 변환하면 된다. 어떤 타입(Type, 형)을 다른 타입으로 변환하는 것을 형변환(캐스팅, casting)이라고 하는데, 형변환에 대해서는 후에 자세히 설명하도록 하겠다. 지금은 문자의 코드값을 알아내는 방법과, 어떤 코드가 어떤 문자를 나타내는가를 알아내는 방법이 있다는 정도만 알면 된다.
위의 예제를 실행하면 65가 화면에 출력되는데, 문자 A의 코드가 10진수로 65임을 뜻한다.(16진수로는 41)
이 예제는 코드값 65(16진수로 41)가 어떤 문자를 뜻하는지를 알아낼 수 있는 방법을 알려 준다. [참고] char형은 크기가 2byte이고, 2byte는 16bit이므로 2의 16제곱(65536)개의 값을 저장할 수 있다. 0을 포함하므로 범위는 0~65535, 16진수로는 0x0000~0xffff가 된다. 두 예제에서 볼 수 있듯이 char형의 변수를 정수형(int)으로 변환(casting)하면, 변수에 저장되어 있는 문자의 코드값을 10진수로 얻을수 있다(CharToCode.java). 반대로 한 코드가 어떤 문자를 나타내는지 알고 싶으면, 코드를 정수형 변수에 저장한 다음, char형으로 변환하여 출력하면 된다(CodeToChar.java). 임의로 0~65535사이의 값을 하나 선택한 다음, CodeToChar.java를 이용해서 선택한 코드가 어떤 문자를 뜻하는지를 알아보거나 반복문을 이용해서 유니코드 전체를 출력해 보는 것도 흥미로울 것이다. 10진수로 66(16진수로 42)을 문자형으로 변환하여 출력하면 어떤 문자가 출력될까? [참고]유니코드(Unicode)는 ASCII코드와의 호환을 위해서, 유니코드 코드번호 1부터 128까지의 문자를 ASCII코드의 1부터 128까지의 문자와 동일하게 지정하였다. 영문자 이외에 Tab이나 space 등의 특수문자를 저장하려면 아래와 같이 하도록 한다.
\t는 실제로는 두 문자로 이루어져 있지만, 단 한 문자 Tab을 의미한다. 아래의 표는 Tab과 같이 특수한 문자를 어떻게 표현할 수 있는지 알게 해준다. 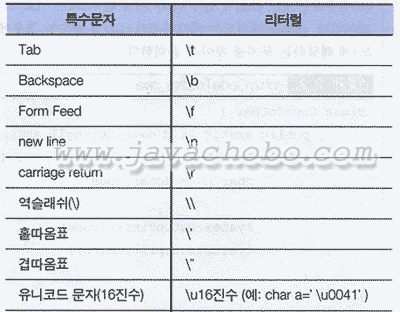 |
3.1. 형변환(Casting)이란?
모든 리터럴과 변수에는 타입이 있다는 것을 배웠다. 프로그램을 작성하다 보면, 서로 다른 타입의 값으로 연산을 수행해야하는 경우가 자주 발생한다.
모든 연산은 기본적으로 같은 타입의 피연산자(Operand)간에만 수행될 수 있으므로, 서로 다른 타입의 피연산자간의 연산을 수행해야하는 경우, 연산을 수행하기 전에 형변환을 통해 같은 타입으로 변환해주어야 한다.
형변환이란, 변수 또는 리터럴의 타입을 다른 타입으로 변환하는 것이다. |
예를 들어 int형 값과 float형 값의 덧셈연산을 수행하려면, 먼저 두 값을 같은 타입으로 변환해야하므로, 둘 다 int형으로 변환하던가 또는 둘 다 float형으로 변환해야한다.
3.2 형변환 방법
기본형과 참조형 모두 형변환이 가능하지만, 기본형과 참조형 사이에는 형변환이 성립되지 않는다. 기본형은 기본형으로만 참조형은 참조형으로만 형변환이 가능하다.
형변환 방법은 매우 간단하며 다음과 같다.
(타입이름)피연산자 |
피연산자 앞에 변환하고자 하는 타입의 이름을 괄호에 넣어서 붙여 주기만 하면 된다. 여기에 사용되는 괄호는 특별히 캐스트연산자(형변환 연산자)라고 하며, 형변환을 캐스팅(Casting)이라고도 한다.
캐스트연산자는 수행결과로 피연산자의 값을 지정한 타입으로 변환하여 반환한다. 이 때, 형변환은 피연산자의 원래 값에는 아무런 영향도 미치지 않는다.
| [예제2-7] CastingEx1.java |
class CastingEx1 { public static void main(String[] args) { double d = 100.0; int i = 100; int result = i + (int)d; System.out.println("d=" + d); System.out.println("i=" + i); System.out.println("result=" + result); } } |
| [실행결과] |
| d=100.0 i=100 result=200 |
double변수 d와 int변수 i의 덧셈 연산을 하기 위해 캐스트연산자를 이용해서 d를 int형으로 변환하여 덧셈연산을 수행하였다. 그리고 그 결과를 int변수 result에 저장하였다.
int형과 int형의 연산결과는 항상 int형 값을 결과로 얻으므로 result의 타입을 int형으로 하였다.
결과의 첫째 줄을 보면 d=100.0으로 형변환 후에도 d에 저장된 값에는 변함이 없다. 캐스트연산자를 이용해서 d를 형변환 하였어도 d에 저장된 값에는 변함이 없음을 알 수 있다. 단지, 형변환 한 결과를 덧셈에 사용했을 뿐이다.
[참고]캐스트 연산자는 우선순위가 매우 높기 때문에 덧셈연산 전에 형변환이 수행되었다.
3.3 기본형의 형변환
8개의 기본형 중에서 boolean을 제외한 나머지 7개의 기본형 간에는 서로 형변환이 가능하다.
 [표2-10]기본형간의 형변환
[표2-10]기본형간의 형변환 [참고]char형은 십진수로 0~65535의 코드값을 갖는다. 문자 'A'의 코드는 십진수로 65이다.
각 자료형 마다 표현할 수 있는 값의 범위가 다르기 때문에 범위가 큰 자료형에서 범위가 작은 자료형으로의 변환은 값 손실이 발생할 수 있다.
예를 들어 실수형을 정수형으로 변환하는 경우 소수점 이하의 값은 버려지게 된다. 위의 표에서도 알 수 있듯이 float리터럴인 1.6f를 int로 변환하면 1이 된다.
반대로 범위가 작은 자료형에서 큰 자료형으로 변환하는 경우에는 절대로 값 손실이 발생하지 않으므로 변환에 아무런 문제가 없다.
[참고]실수형을 정수형으로 변환할 때 소수점 이하의 값은 반올림이 아닌 버림으로 처리된다는 점에 유의하도록 하자.
| [예제2-8] CastingEx2.java |
class CastingEx2 { public static void main(String[] args) { byte b = 10; int i = (int)b; System.out.println("i=" + i); System.out.println("b=" + b); int i2 = 300; byte b2 = (byte)i2; System.out.println("i2=" + i2); System.out.println("b2=" + b2); } } |
| [실행결과] |
| i=10 b=10 i2=300 b2=44 |
byte형 값을 int형으로, int형 값을 byte형으로 변환하고 그 결과를 출력하는 예제이다. byte와 int는 모두 정수형으로 각각 1 byte(8 bit)와 4 byte(32 bit)의 크기를 갖으며, 표현할 수 있는 값의 범위는 byte가 -27 ~ 27-1(-128~127), int가 -232 ~ 232-1이다.
byte의 범위를 int가 포함하고 있으며, int가 byte보다 훨씬 큰 표현 범위를 갖고 있다. 아래 그림에서 볼 수 있는 것과 같이 byte값을 int값으로 변환하는 것은 1 byte에서 4 byte로 나머지 3 byte(24자리)를 단순히 0으로 채워 주면 되므로 기존의 값이 그대로 보존된다.
하지만, 반대로 int값을 byte값으로 변환하는 int값의 상위 3 byte(24자리)를 잘라내서 1 byte로 만드는 것이므로 기존의 int값이 보존될 수도 있고 그렇지 않을 수도 있다.
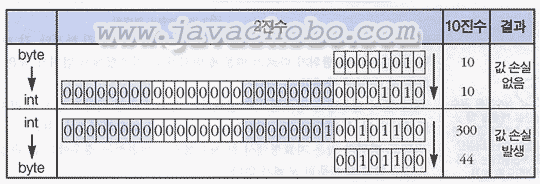
[표2-10]byte와 int간의 형변환
원칙적으로는 모든 형변환에 캐스트연산자를 이용한 형변환이 이루어져야 하지만, 값의 표현범위가 작은 자료형에서 큰 자료형의 변환은 값의 손실이 없으므로 캐스트 연산자를 생략할 수 있도록 했다.
그렇다고 해서 형변환이 이루어지지 않는 것은 아니고, 캐스트 연산자를 생략한 경우에도 JVM의 내부에서 자동적으로 형변환이 수행된다.
반면에 값의 표현범위가 큰 자료형에서 작은 자료형으로의 변환은 값이 손실될 가능성이 있으므로, JVM이 자동적으로 형변환하지 않고 프로그래머에게 캐스트 연산자를 이용하여 형변환을 하도록 강요하고 있다.
위의 예제에서도 int i = (int)b;를 int i = b;와 같이 캐스트 연산자를 생략할 수 있으나 byte b2 = (byte)i2;에서는 캐스트 연산자를 생략해서 byte b2 = i2;와 같이 할 수 없다.
값의 표현범위가 큰 자료형에서 작은 자료형으로의 형변환에 캐스트 연산자를 사용하지 않으면 컴파일시 에러가 발생한다.
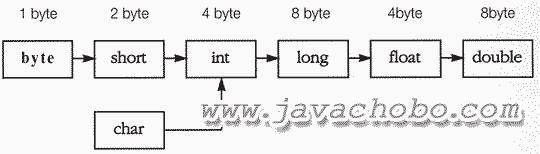
[그림2-3]기본형의 자동형변환이 가능한 방향
위의 그림은 형변환이 가능한 7개의 기본형을 왼쪽부터 오른쪽으로 표현할 수 있는 값의 범위가 작은 것부터 큰 것의 순서로 나열한 것이다.
화살표방향으로의 변환, 즉 왼쪽에서 오른쪽으로의 변환은 캐스트 연산자를 사용하지 않아도 자동형변환이 되는 변환이며, 그 반대 방향으로의 변환은 반드시 캐스트 연산자를 이용한 형변환을 해야 한다.
보통 자료형의 크기가 큰 것일 수록 값의 표현범위가 크기 마련이지만, 실수형은 정수형과는 값을 표현하는 방식이 다르기 때문에 같은 크기일지라도 실수형이 정수형보다 훨씬 더 큰 표현 범위를 갖기 때문에 float와 double이 같은 크기인 int와 long보다 오른쪽에 위치한다.
short과 char은 모두 2 byte의 크기를 갖지만, short의 범위는 -215 ~ 215-1(-32768~32767)이고 char의 범위는 0~216-1(0~65535)이므로 서로 범위가 달라서 둘 중 어느 쪽으로의 형변환도 값 손실이 발생할 수 있으므로 자동적으로 형변환이 수행될 수 없다.
위의 그림을 참고하여 형변환 시에 캐스트 연산자를 생략할 수 있는지 또는 캐스트 연산자를 사용해야하는지를 결정하도록 한다.
| << 요약정리 >> |
| 1. boolean을 제외한 나머지 7개의 기본형들은 서로 형변환이 가능하다. 2. 기본형과 참조형 간에는 서로 형변환이 되지 않는다. 3. 서로 다른 타입의 변수간의 연산에는 형변환이 요구되지만, 값의 범위가 작은 타입에서 큰 타입으로의 변환은 생략할 수 있다. |
출처 - http://cafe.naver.com/javachobostudy
'Development > JavaEssential' 카테고리의 다른 글
| java - 연산자 2 (1) | 2012.10.07 |
|---|---|
| java - 반복문 (0) | 2012.10.03 |
| String과 StringBuffer의 성능에 대해서... (0) | 2012.05.02 |
| 조건문 (0) | 2012.04.19 |
| 연산자 1 (0) | 2012.04.19 |





