JavaScript Regular Expressions
A regular expression is a sequence of characters that forms a search pattern.
The search pattern can be used for text search and text replace operations.
What Is a Regular Expression?
A regular expression is a sequence of characters that forms a search pattern.
When you search for data in a text, you can use this search pattern to describe what you are searching for.
A regular expression can be a single character, or a more complicated pattern.
Regular expressions can be used to perform all types of text search and text replace operations.
Syntax
Example:
Example explained:
/w3schools/i is a regular expression.
w3schools is a pattern (to be used in a search).
i is a modifier (modifies the search to be case-insensitive).
Using String Methods
In JavaScript, regular expressions are often used with the two string methods: search() and replace().
The search() method uses an expression to search for a match, and returns the position of the match.
The replace() method returns a modified string where the pattern is replaced.
Using String search() With a Regular Expression
Example
Use a regular expression to do a case-insensitive search for "w3schools" in a string:
var n = str.search(/w3schools/i);
The result in n will be:
Try it Yourself »
Using String search() With String
The search method will also accept a string as search argument. The string argument will be converted to a regular expression:
Example
Use a string to do a search for "W3schools" in a string:
var n = str.search("W3Schools");
Try it Yourself »
Use String replace() With a Regular Expression
Example
Use a case insensitive regular expression to replace Microsoft with W3Schools in a string:
var res = str.replace(/microsoft/i, "W3Schools");
The result in res will be:
Try it Yourself »
Using String replace() With a String
The replace() method will also accept a string as search argument:
Did You Notice?
 | Regular expression arguments (instead of string arguments) can be used in the methods above. Regular expressions can make your search much more powerful (case insensitive for example). |
|---|
Regular Expression Modifiers
Modifiers can be used to perform case-insensitive more global searches:
| Modifier | Description |
|---|---|
| i | Perform case-insensitive matching |
| g | Perform a global match (find all matches rather than stopping after the first match) |
| m | Perform multiline matching |
Regular Expression Patterns
Brackets are used to find a range of characters:
| Expression | Description |
|---|---|
| [abc] | Find any of the characters between the brackets |
| [0-9] | Find any of the digits between the brackets |
| (x|y) | Find any of the alternatives separated with | |
Metacharacters are characters with a special meaning:
| Metacharacter | Description |
|---|---|
| \d | Find a digit |
| \s | Find a whitespace character |
| \b | Find a match at the beginning or at the end of a word |
| \uxxxx | Find the Unicode character specified by the hexadecimal number xxxx |
Quantifiers define quantities:
| Quantifier | Description |
|---|---|
| n+ | Matches any string that contains at least one n |
| n* | Matches any string that contains zero or more occurrences of n |
| n? | Matches any string that contains zero or one occurrences of n |
Using the RegExp Object
In JavaScript, the RegExp object is a regular expression object with predefined properties and methods.
Using test()
The test() method is a RegExp expression method.
It searches a string for a pattern, and returns true or false, depending on the result.
The following example searches a string for the character "e":
Example
patt.test("The best things in life are free!");
Since there is an "e" in the string, the output of the code above will be:
Try it Yourself »
You don't have to put the regular expression in a variable first. The two lines above can be shortened to one:
Using exec()
The exec() method is a RegExp expression method.
It searches a string for a specified pattern, and returns the found text.
If no match is found, it returns null.
The following example searches a string for the character "e":
Example 1
Since there is an "e" in the string, the output of the code above will be:
Try it Yourself »
Complete RegExp Reference
For a complete reference, go to our Complete JavaScript RegExp Reference.
The reference contains descriptions and examples of all RegExp properties and methods.
source - http://www.w3schools.com/js/js_regexp.asp
JavaScript RegExp Reference
RegExp Object
A regular expression is an object that describes a pattern of characters.
Regular expressions are used to perform pattern-matching and "search-and-replace" functions on text.
Syntax
Example:
Example explained:
- /w3schools/i is a regular expression.
- w3schools is a pattern (to be used in a search).
- i is a modifier (modifies the search to be case-insensitive).
For a tutorial about Regular Expressions, read our JavaScript RegExp Tutorial.
Modifiers
Modifiers are used to perform case-insensitive and global searches:
| Modifier | Description |
|---|---|
| i | Perform case-insensitive matching |
| g | Perform a global match (find all matches rather than stopping after the first match) |
| m | Perform multiline matching |
Brackets
Brackets are used to find a range of characters:
| Expression | Description |
|---|---|
| [abc] | Find any character between the brackets |
| [^abc] | Find any character NOT between the brackets |
| [0-9] | Find any digit between the brackets |
| [^0-9] | Find any digit NOT between the brackets |
| (x|y) | Find any of the alternatives specified |
Metacharacters
Metacharacters are characters with a special meaning:
| Metacharacter | Description |
|---|---|
| . | Find a single character, except newline or line terminator |
| \w | Find a word character |
| \W | Find a non-word character |
| \d | Find a digit |
| \D | Find a non-digit character |
| \s | Find a whitespace character |
| \S | Find a non-whitespace character |
| \b | Find a match at the beginning/end of a word |
| \B | Find a match not at the beginning/end of a word |
| \0 | Find a NUL character |
| \n | Find a new line character |
| \f | Find a form feed character |
| \r | Find a carriage return character |
| \t | Find a tab character |
| \v | Find a vertical tab character |
| \xxx | Find the character specified by an octal number xxx |
| \xdd | Find the character specified by a hexadecimal number dd |
| \uxxxx | Find the Unicode character specified by a hexadecimal number xxxx |
Quantifiers
| Quantifier | Description |
|---|---|
| n+ | Matches any string that contains at least one n |
| n* | Matches any string that contains zero or more occurrences of n |
| n? | Matches any string that contains zero or one occurrences of n |
| n{X} | Matches any string that contains a sequence of X n's |
| n{X,Y} | Matches any string that contains a sequence of X to Y n's |
| n{X,} | Matches any string that contains a sequence of at least X n's |
| n$ | Matches any string with n at the end of it |
| ^n | Matches any string with n at the beginning of it |
| ?=n | Matches any string that is followed by a specific string n |
| ?!n | Matches any string that is not followed by a specific string n |
RegExp Object Properties
| Property | Description |
|---|---|
| constructor | Returns the function that created the RegExp object's prototype |
| global | Checks whether the "g" modifier is set |
| ignoreCase | Checks whether the "i" modifier is set |
| lastIndex | Specifies the index at which to start the next match |
| multiline | Checks whether the "m" modifier is set |
| source | Returns the text of the RegExp pattern |
RegExp Object Methods
| Method | Description |
|---|---|
| compile() | Deprecated in version 1.5. Compiles a regular expression |
| exec() | Tests for a match in a string. Returns the first match |
| test() | Tests for a match in a string. Returns true or false |
| toString() | Returns the string value of the regular expression |
source - http://www.w3schools.com/jsref/jsref_obj_regexp.asp
############## 정규표현식
1. 확장문자 (: backslash)
- s : 공백 문자(스페이스, 탭, 폼 피드, 라인 피드)
- b : 단어의 경계
- B 이를 제외한 모든 문자 매칭
- d : 숫자
- D : 숫자가 아닌 문자 [^0-9] 와 동일
- w : 알파벳, 숫자로 된 문자, 밑줄 기호(_) [A-Za-z0-9]
- W : w의 반대 문자 [^A-Za-z0-9]
- 특수문자 : 특수문자 자체를 의미 예) + (+ 기호 자체)
2. 특수문자
- * : 0회 이상 반복
- + : 1회 이상 반복
- ? : 0 또는 1개의 문자 매칭
- . : 정확히 1개 문자 매칭
3. 플래그
- g : 전역매칭
- i : 대소문자 무시
- m : 여러 줄 매칭
4. 기타
- () : 괄호로 묶인 패턴은 매칭된 다음, 그 부분을 기억한다.
- $1,...,$9 : 괄호로 갭처한 부분 문자열이 저장 됨.
- | : ~또는~
- {} : 반복 횟수
############## 간단한 정규 표현식
var re = /a/ --a 가 있는 문자열
var re = /a/i --a 가 있는 문자열, 대소문자 구분 안함
var re = /apple/ -- apple가 있는 문자열
var re = /[a-z]/ -- a~z 사이의 모든 문자
var re = /[a-zA-Z0-9]/ -- a~z, A~Z 0~9 사이의 모든 문자
var re = /[a-z]|[0-9]/ -- a~z 혹은 0~9사이의 문자
var re = /a|b|c/ -- a 혹은 b 혹은 c인 문자
var re = /[^a-z]/ -- a~z까지의 문자가 아닌 문자("^" 부정)
var re = /^[a-z]/ -- 문자의 처음이 a~z로 시작되는 문장
var re = /[a-z]$/ -- 문자가 a~z로 끝남
상기에 정의된 간단한 표현식을 아래에 넣어 직접 해 보시기 바랍니다.
var str = "sample string";
re.test(str)?"true":"false";
* 특수문자('''', ''^'', ''$'', ''*'', ''+'', ''?'', ''.'', ''('', '')'', ''|'', ''{'', ''}'', ''['', '']'')를 검색할 경우는 '''' 를 넣는다.
############## 간단한 응용예제
var re = /s$/; -- 공백체크
var re = /^ss*$/; -- 공백문자 개행문자만 입력 거절
var re = /^[-!#$%&'*+./0-9=?A-Z^_a-z{|}~]+@[-!#$%&'*+/0-9=?A-Z^_a-z{|}~]+.[-!#$%&'*+./0-9=?A-Z^_a-z{|}~]+$/; --이메일 체크
var re = /^[A-Za-z0-9]{4,10}$/ -- 비밀번호,아이디체크 영문,숫자만허용, 4~10자리
var re = new RegExp("(http|https|ftp|telnet|news|irc)://([-/.a-zA-Z0-9_~#%$?&=:200-377()]+)","gi") -- 홈페이지 체크
var re = "<[^<|>]*>"; -- 태그제거
var re = /[<][^>]*[>]/gi;-- 태그제거
str = str.replace(RegExpTag,"");
var RegExpJS = "<script[^>]*>(.*?)</script>"; -- 스크립트 제거
str = str.replace(RegExpJS,"");
var RegExpCSS = "<style[^>]*>(.*?)"; -- 스타일 제거
str = str.replace(RegExpCSS,"");
var RegExpHG = "[ㄱ-ㅎ가-힣]"; -- 한글 제거
str = str.replace(RegExpHG,"");
var RegExpDS = /<!--[^>](.*?)-->/g; -- 주석 제거
str6 = str.replace(RegExpDS,"");
var regExp = /[a-z0-9]{2,}@[a-z0-9-]{2,}.[a-z0-9]{2,}/i; --이메일 체크
## 기타 응용
re = new RegExp("^@[a-zA-Z0-9]+s+","i");//문장의 처음이 @이고 문자가 1나 이상 있으면 ok
기타 상기와 동일하나 약간씩 다른 샘픔
영숫자 조합책크
if ((new RegExp(/[^a-z|^0-9]/gi)).test(frm.loginid.value)) {
alert("ID는 영숫자 조합만 사용하세요");
frm.loginid.focus();
}
홈페이지 주소 책크
function chk(v){
str='';
re = new RegExp("^http://","i");
re.test(v)?str='y':str='n';
alert(str);
}
hanmail인지를 책크
function chk(v){
str='';
re = new RegExp("hanmail.net","i");
re.test(v)?str=true:str=false;
return str
}
//본문내에서 도메인 구하기
var patt = /(http(s)?://)?w+(.w+)+/gi;
var result = (aa.value.match(patt));
//본문내에서 url구하기
상기와 유사 var patt = /(http(s)?://)?w+(.w+).S*/gi;
########### 정규식 메소드 및 사용법
참조 http://eknote.tistory.com/1251
참조 http://www.javascriptkit.com/javatutors/redev3.shtml
RegExp.exec(string)
RegExp.test(string)
String.match(pattern)
String.search(pattern)
String.replace(pattern,string)
String.split(pattern)
출처 - http://www.shop-wiz.com/board/main/view/root/javascript2/16
자바스크립트 정규표현식

출처 - http://iamnotokay.tistory.com/26
이메일 체크 정규식
/^[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*\.[a-zA-Z]{2,3}$/i;
핸드폰번호 정규식
/^\d{3}-\d{3,4}-\d{4}$/;
일반 전화번호 정규식
/^\d{2,3}-\d{3,4}-\d{4}$/;
아이디나 비밀번호 정규식
/^[a-z0-9_]{4,20}$/;
var regExp = /^01([0|1|6|7|8|9]?)-?([0-9]{3,4})-?([0-9]{4})$/;
if ( !regExp.test( document.frm.hp.value ) ) {
alert("잘못된 휴대폰 번호입니다. 숫자, - 를 포함한 숫자만 입력하세요.");
return false
}
알고 있어야 할 8가지 정규식 표현 from nettuts+
 이 쓴 유용한 정규식 표현에 대한 글 을 올려서 내용 정리합니다. 정규식만 잘 써도 Validation이나 String을 다루기가 무척 편할텐데 쓸때마다 헷갈리고 약간은 어렵게 느껴지고 쉽게 다가가지지 않는게 정규식인것 같습니다.
이 쓴 유용한 정규식 표현에 대한 글 을 올려서 내용 정리합니다. 정규식만 잘 써도 Validation이나 String을 다루기가 무척 편할텐데 쓸때마다 헷갈리고 약간은 어렵게 느껴지고 쉽게 다가가지지 않는게 정규식인것 같습니다.Vasili는 정규식에 대해서 잘 모르면 Regular Expressions for Dummies
스크린캐스트 시리즈를 보기 권하고 있습니다. 시간내서 보면 꽤 도움이 될듯 합니다. 자리 잡고 스크린캐스트 보게는 잘 안되는것 같습니다. 글을 읽어도... ㅎㅎ정규표현식을 공부해도 막상 적용하려면 약간 막막하고 헷갈리기 마련인데 웹개발할 때 보통 많이 사용할 만한 내용을 위주로 설명해 주었기 때문에 이해하기도 쉽고 활용해서 쓰기에 꽤나 유용할 듯 보입니다. (위에도 간단히 밝혔지만 nettuts+의 올라온 포스팅을 번역,정리한 내용입니다.) 간단한 정규표현식 문법은 전에 올린 포스팅을 참고하시면 될 것 같습니다.
Matching a Username

1 2 | // Pattern/^[a-z0-9_-]{3,16}$/ |
문자열의 시작부분을 찾는 ^ 다음에 소문자(a-z)나 숫자(0-9), 언더스코어(_), 하이픈(-)가 나올 수 있고 {3, 16}은 앞의 캐릭터들( [a-z0-9_-] )이 최소 3개에서 15개 이하로 나와야 하고 문자열의 끝을 의미하는 $가 마지막에 나옵니다.
Match되는 스트링 : my-us3r_n4m3
Match되지 않는 문자열 : th1s1s-wayt00_l0ngt0beausername (너무 김)
Matching a Password

1 2 | // Pattern/^[a-z0-9_-]{6,18}$/ |
username부분과 아주 유사합니다만 유일하게 다른 부분은 글자수가 3~16자가 아니라 6~18자라는 부분( {6,18} )입니다.
Match되는 스트링 : myp4ssw0rd
Match되지 않는 문자열 : mypa$$w0rd (달러($)표시가 포함되어 있음)
Matching a Hex value

1 2 | // Pattern/^#?([a-f0-9]{6}|[a-f0-9]{3})$/ |
이번에서 문자열의 시작을 찾는 ^로 시작합니다. 그 다음 number sign(#)은 뒤에 물음표(?)가 있기 때문에 옵션입니다. 물음표(?)는 그 앞에 나온 캐릭터가(여기서는 number sign)이 선택사항(있어도 되고 없어도 되는)임을 의미합니다. 그 다음에 나오는 그룹(괄호 안에 있는)에서 2가지 경우를 가질 수 있습니다. 첫번째는 a와 f사이의 소문자나 숫자가 6번나오는 것입니다. 세로바(|)는 3개의 a와 f사이의 소문자나 숫자가 대신 나올수도 있음을 으미합니다. 마지막으로 문자열의 끝을 의미하는 $가 위치합니다.
6개의 문자열을 앞에 둔 이유는 #ffffff같은 Hex값을 파서가 잡아내도록 하기 위한 것으로 반대로 3개의 문자열 검사를 앞에 두었다면 파서는 뒤의 3개의 f는 빼로 오직 #fff만을 잡아냈을 것입니다.
Match되는 스트링 : #a3c113
Match되지 않는 문자열 : #4d82h4 (h 가 포함되어 있음)
Matching a Slug

1 2 | // Pattern/^[a-z0-9-]+$/ |
mod_rewrite나 pretty URL을 사용해 본적이 있다면 이 정규표현식을 사용하게 될 것입니다. 시작 문자열인 ^가 처음에 나오고 뒤이어 소문자, 숫자, 하이픈(-)이 한개 또는 한개이상(+기호)나오고 마지막으로 문자열의 끝인 $가 나옵니다.
Match되는 스트링 : my-title-here
Match되지 않는 문자열 : my_title_here (언더스코어( _ ) 가 포함되어 있음)
Matching an Email
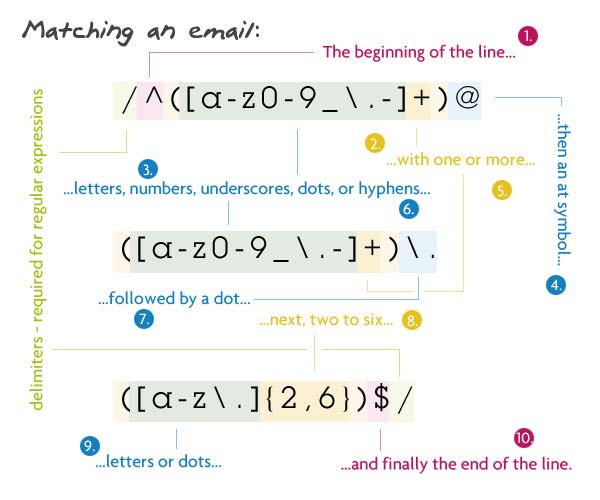
1 2 3 | // Pattern/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/ |
문자열의 시작인 ^로 시작하고 첫번째 그룹(괄호 안)에서 1개 또는 그 이상의 소문자, 숫자, 언더스코어( _ ), 점(.), 하이픈(-)가 나옵니다. escape하지 않은 점(.)은 다른 문자를 의미하기 때문에 점(.)은 이스케이프 해줍니다.(\.) 그 뒤에 앳 기호(@)가 나오고 그 다음 1개또는 그 이상의 소문자, 숫자, 언더스코어( _ ), 점(.), 하이픈(-)으로 구성된 도메인명이 옵고 그 후 점(이스케이프된)이 소문자와 점으로 된 2~6개의 문자열이 옵니다. 2~6개로 한 이유는 .co.kr이나 .ny.us같은 국가 TLD(Top-Level-Domain)때문이며 마지막으로 문자열의 끝($)인 옵니다.
Match되는 스트링 : john@doe.com
Match되지 않는 문자열 : john@doe.something (TLS가 너무 김)
Matching a URL
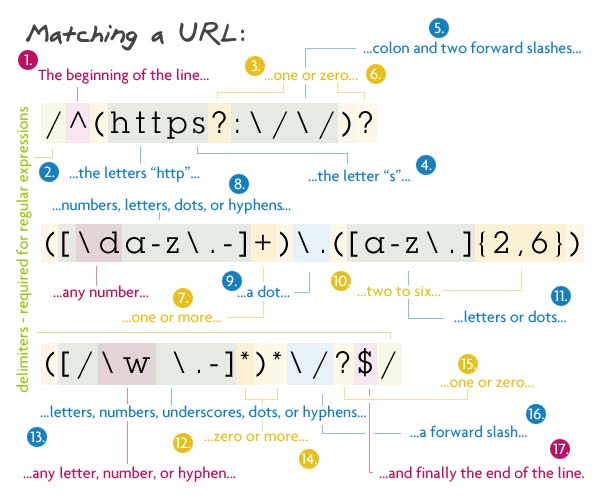
1 2 | // Pattern/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w_\.-]*)*\/?$/ |
이 정규표현식은 위에 나온 정규표현식의 최종본이라고 할 수 있습니다.
첫번째 그룹은 모두 옵션인데 이것은 URL이 "http://"나 "https://" 또는 둘다 없이 시작하도록 한다. s뒤에 물음표(?)는 URL이 http와 https를 모두 허용한다. 이 그룹전체를 선택사항으로 하기 위해서 뒤에 물음표(?)를 추가했습니다.
다음은 도메인명으로 한개이상의 숫자, 문자열, 점(.), 하이픈(-)뒤에 또다른 점(.)이 오고 그 뒤에 2~6개의 문자와 점이 옵니다. 이어지는 부분을 추가적인 파일과 디텍토리에 대한 부분으로 이 그룹에서는 갯수에 관계없이 슬래쉬(/), 문자, 숫자, 언더스코어(_), 스페이스, 점(.), 하이픈(-)이 나올 수 있으며 이 그룹은 많은 수의 디렉토리와 파일과 매치됩니다. 물음표(?)대신 별표(*)를 사용한 것은 별표는 0 또는 1이 아닌 0 또는 1개이상을 의미하기 때문입니다. 만약 물음표(?)를 사용했다면 오직 한개의 파일/디렉토리만 매치될 수 있었을 것입니다.
그 뒤에 슬래시(/) 매치되지만 이것은 선택사항이며 마지막으로 문자열의 끝($)이 나타납니다.
Match되는 스트링 : http://net.tutsplus.com/about
Match되지 않는 문자열 : http://google.com/some/file!.html (느낌표가 포함되어 있음)
Matching an IP Address
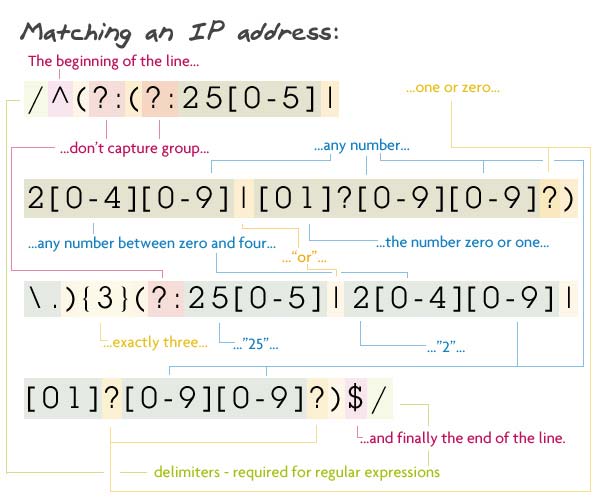
1 2 3 | // Pattern/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/ |
자, 저는 거짓말을 하지 않습니다. 이 정규표현식은 제가(Vasili) 작성하지 않았고 이곳
에서 가져왔습니다. 정규식이 첫번째로 잡아낸 그룹은 실제로 매치된(captured)된 그룹이 아닙니다. 왜냐하면 ?: 가 그안에 위치하고 있기 때문입니다. ?:는 파서가 이 그룹을 잡아내지 않도록 합니다. 또한 이 잡히지 않는 그룹은 3번 반복되기를 원합니다.(그룹의 끝에 {3}) 이 그룹은 또다른 서브그룹과 점(.)을 담고 있고 파서는 점(.)이 뒤에 있는 서브그룹을 매치하려고 찾습니다.
서브그룹은 또다른 잡히지 않는(non-captured) 그룹입니다. 이것은 0~5가 뒤에 오는 "25"거나 0~4와 모든 숫자가 뒤에 오는 "2"이거나 옵션이 0 또는 2개의 숫자가 이어지는 숫자들의 문자셋의 묶음입니다.
이 3가지가 매치된 이후에 다음 캡쳐되지 않는 그룹으로 들어갑니다. 이것은 0~5가 이어지는 "25" 또는 0~4와 함께 오는 "2" 그리고 마지막에 다른 숫자(0이나 두자리 숫자)가 옵니다.
마지막 문자($)와 함께 이 복잡한 정규표현식이 끝납니다.
Match되는 스트링 : 73.60.124.136
Match되지 않는 문자열 : 256.60.124.136 (첫번째 숫자는 250~255이어야 함)
Matching an HTML Tag
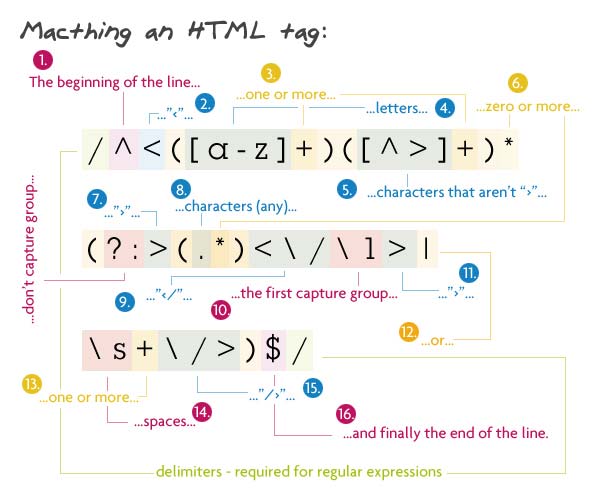
1 2 | // Pattern/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/ |
이 포스팅에서 가장 유용한 정규표현식 중의 하나입니다. 이것은 어떤 HTML태그도 매치할 수 있고 일반적으로 라인의 첫번째에서 시작합니다.
첫번째로 오는 것은 태그이름입니다. 이것은 반드시 한개이상의 문자가 되어야 하며 첫번째로 잡히는 그룹이기도 합니다. 이것은 닫는태그를 잡았을 때 찾아야 할 값입니다. 다음에는 태그의 속성입니다. 이것은 >를 제외한 어떤 문자도 올 수 있습니다. 옵션사항이지만 1개이상의 캐릭터와 매치되기를 원하기 때문에 별표가 사용되었습니다. 플러스기호는 속성과 값을 이루고 별표는 원하는 만큼의 속성(attribute)가 매치될 수 있도록 합니다.
다음으로 세번째 non-capture그룹이 오는데 내부에 >기호가 담길 것이고 컨텐츠부분과 닫는태그가 있습니다.(공백과 슬래시(/), > 기호) 첫옵션은 문자들에 이어지는 >기호를 찾습니다. \1은 캡쳐된 첫번째 그룹에서의 내용을 표현하는데 사용됩니다. 이 경우에는 태그의 이름이 됩니다. 이제 태그이름이 매치되지 않으면 자신의 닫는태그를 찾기를 원합니다. 이것은 "/>"가 이어지는 한개이상의 공백이 필요합니다.
Match되는 스트링 : <a href="http://net.tutsplus.com/">Nettuts+</a>
Match되지 않는 문자열 : <img src="img.jpg" alt="My image>" /> (속성은 >기호를 가질 수 없음)
내용은 아주 좋은데 급하게 작성했더니 번역이 영 그렇네요. 원문가서 보시길....(은근슬쩍 급하게 해서 번역이 이런 척... ㄷㄷㄷ)
출처 - http://blog.outsider.ne.kr/360
*본 페이지는 IE용 태그를 사용하였으므로, firefox 등에서는 정상작동하지 않을 수 있습니다.
*테스트를 해보실라문 요기를 클릭
차례
- 1. 정규식이란?
- 2. 정규식 만들기
- 3. 정규식 표현법
- 4. 정규식 사용 예제
- 5. Javascript 정규식 함수
- 6. 정규식으로 만든 유용한 Javascript 함수
- 7. Java 정규식 함수
1. 정규식이란?
- String의 검색, 치환, 추출을 위한 패턴.
- 언어별 사용법은 대동소이함.
- 패턴예>전화번호 형식, 이메일 형식 등.
2. 정규식 만들기
- Javascript
- var regexp = /pattern/[flags] ;
var test = regexp.test(to be checked) - var regexp = new RegExp("pattern"[, "flags"]);
var test = regexp.test(to be checked) - flags for javascript
- g : global match, 일반적으로 패턴이 1번만 발견되면 찾기를 종료하지만, g flag가 있으면, 문자열 내에서 모든 패턴을 찾는다.
- i : ignore case, 대소문자를 고려하지 않고 체크한다.[a-z]와 [A-Z]는 같은 표현이 된다.
- m : match over multiple lines, 여러 줄에 걸쳐 체크를 한다.
- Java
- java.util.regex package
- Pattern p = Pattern.compile("pattern");
Matcher m = p.matcher("string to be checked");
boolean b = m.matches(); - boolean b = Pattern.matches("pattern", "string to be checked");
3. 정규식 표현법
*ⓥ는 valid, ⓘ는 invalid
*형광 초록 바탕 부분은 매칭되는 부분.
*예제는 javascript 기준이며, 언어에 따라 다소 차이가 발생할 수 있다.
| 문자 | 용도 | 예제 |
|---|---|---|
| \ |
|
|
| ^ | 문자열의 시작. []안에서는 not의 의미 * ^A는 "A로 시작"이라기 보다는 "시작 직후에 A가 나온다"는 의미로 해석하는 것이 좋다. 즉, 시작과 끝과 같은 빈 공간을 하나의 문자로 간주하는 것이 좋다. | /^A/g
|
| $ | 문자열의 마지막 | /t$/
|
| * | 0번 이상 반복 | /ab*d/g
|
| + | 1번 이상 반복 ( = {1,} ) | /ab+d/g
|
| ? | 0번 이나 1번 | /e?le?/g
|
| . | new line 을 제외한 모든 글자 | /.n/g
|
| (x) | x를 체크하고 체크한 값을 변수로 저장 | /(f..) (b..)/
|
| (?:x) | x를 체크하고 체크한 값을 변수로 저장하지 않음 | /(?:f..) (b..)/
|
| x|y | x 또는 y | /green|red/
|
| x(?=y) | x후에 y가 나오고, x부분만 매칭되는 부분으로 간주 | /blah(?=soft|hard)/
|
| x(?!y) | x가 나오고 그 뒤에 y가 있으면 안 됨 | /blah(?!hard)/
|
| {n} | 앞에 지정한 것이 n개 | /.{3}/
|
| {n,} | 앞에 지정한 것이 n개 이상 | /.{3,}/
|
| {n,m} | 앞에 지정한 것이 n~m개 | /.{3,5}/
|
| [xyz] | x나 y나 z. []안에는 얼마든지 쓸 수 있다. | /[abc]{2}/
|
| [x-z] | x에서 z까지 | /[a-z]{4,}/g
|
| [^xyz] | x,y,z를 제외한 나머지 모든 것 | /[^a-z]{2,}/g
|
| [\b] | 백스페이스. \b와 혼동하지 말것. | /[\b]/g
|
| \b | 단어의 경계.[\b]와 혼동하지 말것. | /\bn[a-z]/g
|
| \B | \b 를 제외한 전부 | /\Bn[a-z]/g
|
| \cX | 컨트롤X와 매칭. \cM은 컨트롤M과 매칭 | |
| \d | 숫자.[0-9]와 같음 | /\d/g
|
| \D | \d 를 제외한 전부 | /\D/g
|
| \f | form-feed | |
| \n | new line | |
| \r | carriage return | |
| \s | white space ex>탭, 띄어쓰기, \n, \r | /k\s/g
|
| \S | \s 를 제외한 전부 | /k\S/g
|
| \t | 탭 | |
| \v | vertical tab | |
| \w | 알파벳+숫자+_. [A-Za-z0-9_]와 동일 | /\w/g
|
| \W | \w 빼고 전부 | /\W/g
|
| \n | \n이 자연수일때, ()로 지정한 n번째 정규식 | /(.{2})e tru\1 is out \1ere/
|
| \xhh | hh는 hexacode, | /[\x21-\x40]/g
|
| \uhhhh | hhhh는 hexacode, | /[\u3131-\u3163\uac00-\ud7a3]/g
|
4. 정규식 사용 예제
/^[0-9]/
|
/^\w+$/
|
/^[a-zA-Z][\w\-]{4,11}$/
|
/^[0-9]{2,3}-[0-9]{3,4}-[0-9]{4}/
|
/^0\d{1,2}-[1-9]\d{2,3}-\d{4}$/
|
/^[\.a-zA-Z0-9\-]+\.[a-zA-Z]{2,}/
|
/^(?:[\w\-]{2,}\.)+[a-zA-Z]{2,}$/
|
/^[_a-zA-Z0-9\-]+@[\._a-zA-Z0-9\-]+\.[a-zA-Z]{2,}/
|
/^[\w\-]+@(?:[\w\-]{2,}\.)+[a-zA-Z]{2,}$/
|
/^([a-z]+):\/\/((?:[a-z\d\-]{2,}\.)+[a-z]{2,})(:\d{1,5})?(\/[^\?]*)?(\?.+)?$/i
|
/^[ㄱ-ㅣ가-힣]+$/
|
5. Javascript 정규식 함수
| 함수 | 코드예제 | 코드설명 |
|---|---|---|
| Array RegExp.exec (to be checked) | var myRe=/d(b+)(d)/ig; var myArray = myRe.exec("cdbBdbsbz"); /d(b+)(d)/gi
| myArray.index =1 ; (처음으로 매칭되는 위치, 컴터가 늘 그렇듯 위치는 0번째부터 센다.) myArray.input = cdbBdbsbz; (체크할 대상) myArray[0] = dbBd;(검사에 통과한 부분) myArray[1] = bB;(1번째 괄호에서 체크된 부분) myArray[2] = d;(2번째 괄호에서 체크된 부분) myRe.lastIndex =5 ; (다음번 체크를 하기위한 위치.) myRe.ignoreCase = true; (/i 플래그 체크) myRe.global = true; (/g 플래그 체크) myRe.multiline = false; (/m 플래그 체크) RegExp.$_ = cdbBdbsbz;(입력한 스트링) RegExp.$1 = bB;(1번째 괄호에서 체크된 부분 ) |
| boolean RegExp.test(to be checked) | var myRe=/d(b+)(d)/ig; var checked = myRe.test("cdbBdbsbz"); document.write("checked = " + checked +";<br>"); /d(b+)(d)/gi
| 실행결과: checked = true; |
| String RegExp.toString() | var myRe=/d(b+)(d)/ig; var str = myRe.toString(); document.write(str); | 실행 결과: /d(b+)(d)/gi |
| String String.replace(pattern or string, to be replaced) | var str = "abcdefe"; document.write(str.replace("e" , "f")); | 실행 결과: abcdffe e가 2번 있지만, 첫번째 인자가 정규식이 아니라 문자열일 경우는 첫번째 것만 바꾼다. |
var str = "aba"; document.write(str.replace(/^a/ , "c")); | 실행 결과: cba | |
var re = /(\w+)\s(\w+)/; var str = "John Smith"; newstr = str.replace(re, "$2, $1"); document.write(newstr) | 실행 결과: Smith, John re에 의해서 찾아진 문자열 들은 re에서 ()로 표현된 순서대로 $1, $2와 같이 변수로 저장된다. | |
var re = /\s(?:http|https):\/\/\S*(?:\s|$)/g; var str = "url is http://iilii.egloos.com/ !!\n"; str += "blah home: http://www.blah.co.kr"; newstr = str.replace(re, function (str,p1,offset,s) { return "<a href='" + str + "'>" + str + "</a>"; } ).replace(/\n/, "<br>"); document.write(newstr); | url is http://iilii.egloos.com/ !! blah home: http://www.blah.co.kr str: 찾은 문자열 p1: ()에서 검색된 1번째 문자열. 마찬가지로 p2,p3 등도 가능 offset: str을 찾은 위치 s : 원본 문자열. | |
| Array String.match(regular expression | var str = "ABCdEFgHiJKL"; var myResult = str.match(/[a-z]/g ); for(var cnt = 0 ; cnt < myResult.length; cnt++){ document.write(cnt +":" + myResult[cnt] +"<br>"); } document.write("비교<br>"); var str = "ABCdEFgHiJKL"; var myResult = /[a-z]/g.exec(str); for(var cnt = 0 ; cnt < myResult.length; cnt++){ document.write(cnt +":" + myResult[cnt] +"<br>"); } | 실행 결과: 0:d 1:g 2:i 비교 0:d String.match(RegExp) =>g flag가 있으면 다 찾아낸다. RegExp.exec(String) =>g flag가 있어도, 한 개만 찾고 끝낸다. |
| Array String.split([separator[, limit]]) | var str = "ABCdEFgHiJKL"; var myResult = str.split(/[a-z]/g , 3); for(var cnt = 0 ; cnt < myResult.length; cnt++){ document.write(cnt +":" + myResult[cnt] +"<br>"); } | 실행 결과: 0:ABC 1:EF 2:H 주어진 문자열을 separator를 기준으로 limit 만큼 자른다. |
6. 정규식으로 만든 유용한 Javascript 함수
String removeTags(input)HTML tag부분을 없애준다 |
function removeTags(input) { return input.replace(/<[^>]+>/g, ""); }; |
| example> var str = "<b>blah</b> <i>soft</i>"; document.write(str +"<br>"); document.write(removeTags(str)); blah soft blah soft |
String String.trim()문자열의 앞뒤 공백을 없애준다. |
String.prototype.trim = function() { return this.replace(/^\s+|\s+$/g, ''); }; |
| example> var str = " untrimed string "; document.write("========" + str+ "==============<br>"); document.write("========" + str.trim() + "=============="); ======== untrimed string ============== ========untrimed string============== |
String String.capitalize()단어의 첫 글자를 대문자로 바꿔준다. |
String.prototype.capitalize = function() { return this.replace(/\b([a-z])/g, function($1){ return $1.toUpperCase(); }) ; }; |
| example> var str = "korea first world best"; document.write(str.capitalize()); Korea First World Best |
String number_format(input)입력된 숫자를 ,를 찍은 형태로 돌려준다 |
function number_format(input){ var input = String(input); var reg = /(\-?\d+)(\d{3})($|\.\d+)/; if(reg.test(input)){ return input.replace(reg, function(str, p1,p2,p3){ return number_format(p1) + "," + p2 + "" + p3; } ); }else{ return input; } } |
| example> document.write(number_format(1234562.12) + "<br>"); document.write(number_format("-9876543.21987")+ "<br>"); document.write(number_format("-123456789.12")+ "<br>"); 1,234,562.12 -9,876,543.21987 -123,456,789.12 |
7. Java 정규식 함수
Pattern p = Pattern.compile("(a*)(b)");
Matcher m = p.matcher("aaaaab");
if (m.matches()) {
for (int i = 0; i < m.groupCount() + 1; i++) {
System.out.println(i + ":" + m.group(i));
}
} else {
System.out.println("not match!");
}
result>
0:aaaaab
1:aaaaa
2:b
0번째는 매칭된 부분.
|
String a = "I love her";
System.out.println(a.replaceAll("([A-Z])", "\"$1\""));
result>
"I" love her
자바도 $1을 쓸 수 있다.
|
Pattern p = Pattern.compile("cat");
Matcher m = p.matcher("one cat two cats in the yard");
StringBuffer sb = new StringBuffer();
while (m.find()) {
m.appendReplacement(sb, "dog");
System.out.println(sb.toString());
}
m.appendTail(sb);
System.out.println(sb.toString());
result>
one dog
one dog two dog
one dog two dogs in the yard |
출처 - http://kio.zc.bz/Lecture/regexp.html
'Development > JavaScript' 카테고리의 다른 글
| 브라우저 중앙 위치에서 팝업 띄우기 (0) | 2012.07.04 |
|---|---|
| javascript - setTimeout, setinterval (0) | 2012.07.01 |
| spin.js 예제 (0) | 2012.06.21 |
| JSON - jackson 사용 (0) | 2012.06.08 |
| Javascript - return true; return false; (0) | 2012.05.23 |





