많은 사람들이 관계를 맺고, 이 관계가 정보가 되는 소셜 서비스에서는
데이터를 효과적으로 다루기 위하여 보다 본질적인 방법을 고안할 필요가 있습니다.
이번 글에서는 NoSQL 시스템이 발생하게 된 이유에 대해 설명하고,
NoSQL 시스템을 분류해 보도록 하겠습니다.
NoSQL 분류 기준
저장시스템 같은 플랫폼뿐만 아니라, 컴퓨터 자체를 포함하여 서비스를 만들기 위한 모든 플랫폼은 읽기와 쓰기가 기본입니다. 운동 경기에서 공격과 수비가 기본인 것과 마찬가지 입니다. 몇 가지 예를 들어 보겠습니다.
컴퓨터의 원형 모델이라고 하는 폰노이만 구조의 내장 프로그램 컴퓨터의 이론적 근간은 Turing machine이라 불리는 수학적 모델입니다. 이 모델은 다음과 같은 구성 요소로 이루어져 있습니다.
• 무한히 길고, 셀로 구성되며, 각 셀에는 하나의 기호를 쓸 수 있는 테이프
• 셀에서 기호를 읽거나 쓰고 왼쪽이나 오른 쪽으로 한 칸 움직일 수 있는 헤드
• 상태 전이 테이블
• (현재 상태, 현재 셀에서 읽은 기호) → (다음 상태, 셀에 쓸 기호, 왼쪽/오른쪽)
상태 전이 테이블을 프로그램을 ‘서비스’라 생각하면 플랫폼이 해주는 일은 읽기/쓰기 입니다.
이러한 읽기/쓰기는 CPU micro architecture부터 클라우드 서비스까지 시스템 규모에 상관없이 반드시 있어야하는 기본 기능입니다.
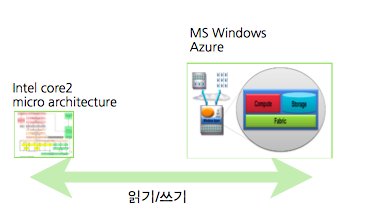
• Intel core2 micro architecture: 하드웨어 구성 측면에서 pipelining 부분과 out-of-order execution,ALU를 빼고 생각하면, 나머지 부분은 모두 읽고 쓰는 연산을 위한 구성입니다.
• MS Windows Azure: Azure같은 클라우드 시스템에서도 읽고 쓰는 Storage 부분이 핵심 부분입니다.
쓰기를 한 데이터를 읽고 이렇게 읽은 데이터를 바탕으로 계산하고 다시 중간 결과 데이터를 쓰고 이러한 읽기-계산-쓰기 작업을 반복하는 것이 프로그램입니다.
인터넷 서비스 또한 마찬가지입니다.
‘읽고 쓰기가 기본’이라는 The Platform 독자들이라면 당연히 아시는 이야기를 장황하게 하는 이유는 그 기본에서 NoSQL같은 저장시스템이 갖춰야할 핵심 기능을 생각해볼 수 있기 때문입니다.
앞으로 논의할 NoSQL 시스템을 분류하는데 사용할 기준을 미리 정리해 보겠습니다.
데이터 모델 및 쿼리 모델
Turing machine은 테이프 한 셀만 읽기/쓰기를 하지만, 실제 시스템에서는 그보다는 훨씬 다양하고 복잡한 읽기/쓰기가 필요합니다. 읽기/쓰기의 대상이 되는 저장 모델을 데이터 모델이라 하고 읽고 쓰는 명령어 모델을 쿼리 모델이라 하겠습니다. 쿼리 모델을 API라고 할 수도 있지만, 저장 모델에 대한 읽기/쓰기 연산이라는 점을 강조하기 위해서 RDBMS에서 주로 사용하는 용어인 쿼리를 사용하겠습니다. 데이터 모델과 쿼리 모델은 동전의 양면처럼 서로 밀접한 관련성이 있습니다. 객체 지향 관점의 예를 들어보면 클래스 instance와 클래스에 정의된 method와 같은 관계입니다.
데이터 분산
한 컴퓨터에서 서비스가 요구하는 쿼리를 처리하지 못하는 경우가 발생합니다. 이러한 상황은 쿼리를 처리하기 위해 사용하는 CPU, 메모리, 디스크, 네트워크의 용량/처리량의 한계때문에 발생합니다. 이러한 문제를 해결하기 위해서 한 컴퓨터의 처리량을 높이는 scale-up 접근 방식은 비용이 많이 들기도 하지만 아키텍처 특성상 처리 요구량을 감당하지 못하는 경우가 많습니다. 이러한 이유로 두 대 이상의 컴퓨터에 서비스가 요구되는 쿼리 처리를 위한 자원을 분산하는 방식을 취할 수 밖에 없는데 이러한 접근 방식을 scale-out 접근 방식이라 합니다.
큰 스케일의 서비스를 위한 분산의 기본 원칙은 서비스의 요구 수준 내에서 나누면 나눌수록 쿼리 처리량이 늘어나야 한다는 것입니다. 무한하게 scale-out 하는 방식이 있으면 좋겠지만, 하나의 scale-out 접근 방식이 모든 scale-out 요구사항에 적합할 것이라는 가정을 하는 것은 현실적이지 않기 때문에“서비스의 요구 수준 내에서” 라는 조건이 들어갑니다.
가용성을 높이기 위한 복제
한 시스템에 저장된 데이터는 쿼리를 처리하기 위해 필요한 프로그램이나 리소스의 동작 실패로 인해서 읽거나 쓸 수 없는 상태로 빠질 수 있습니다. 따라서 서비스의 고 가용성을 위해서는 데이터와 쿼리 처리를 위한 리소스를 두 곳 이상의 장소에 분산 저장시켜야 하고 이를 복제라고 합니다. 복제는 다음과 같은 세가지 모델로 분류할 수 있습니다[1]
• Transactional replication: 2PC(Two Phase Commit) 프로토콜 등을 이용해서 트랜잭션 단위의 복제를 하는 모델입니다.
• State machine replication: 복제 대상 시스템을 Finite State Machine으로 보고 원본 시스템에서 발생하는 event(연산)를 atomic broadcast (total ordering된 메시지 전달)을 통해서 복제를 하는 방식입니다
• Virtual Synchrony: Group communication 등에서 사용되는 메시지 전달 기술입니다. 프로세스 그룹 내의 동시적 event 발생에 대한 동일한 순서의 메시지 전달을 보장하는 방식입니다. (이 방식은 in-memory 데이터에 대한 방식이라고 합니다.)
연산에 대한 데이터 일관성 모델
RDBMS에는 ACID(Atomicity, Consistency, Isolation, Durability) 속성으로 대변되는 트랜잭션 개념이 있습니다. 트랜잭션은 하나 이상의 쿼리를 논리적으로 묶은 개념이고, 이러한 트랜잭션이 DBMS에 적용되었을 때 시스템이 어떠한 속성을 보장해서 DBMS에 저장된 데이터에 대한 일관성을 유지하는지 밝히는 것입니다. NoSQL 시스템도 마찬가지로 사용자가 시스템에 가한 연산에 대해 시스템이 어떻게 데이터 일관성을 유지해주는지에 대해 밝혀야만 합니다.
RDBMS NoSQL
여러 NoSQL 시스템이 어떠한 특징을 가지고 있는지 알아보기 전에, 어떤 연유에 의해서 NoSQL 저장시스템이 나타나게 되었는지에 대해 알아 보는 것이 좋을 것 같습니다.
Antithesis로서의 NoSQL
NoSQL을 ‘No SQL’로 생각해 보면, RDBMS와 대립하는 시스템으로 생각할 수 있습니다. RDBMS의 대립물로 나오게 되는 논리적 흐름은 다음과 같습니다.
• RDBMS는 관계(relation, table) 형태로 모델링 할 수 있는 데이터 조작 방법으로 SQL 언어를 정의하고 ACID 속성의 트랜잭션 개념을 지원합니다
• 인터넷 스케일 서비스의 매우 높은 데이터 처리량 요구에 의해서 데이터를 분산 처리해야 하는 scale-out 접근 방식이 절실해 졌습니다.
• 기존 RDBMS의 scale-out 접근 방식은 RDBMS의 핵심이라고 할 수 있는 관계 모델과 트랜잭션의 연산 일관성 속성을 유지하는 것을 목적으로 하고 있습니다.
위와 같은 속성을 유지하면서 scale-out하는 것은 어렵습니다. 이는 데이터의 분산과 복제시에도 발생하는 문제입니다.
그래서 DBMS가 보장하는 ACID 기반의 transaction 속성이나 복제 일관성 모델을 완화해서 scale-out 하는 방식을 취합니다
RDBMS의 scale-out
RDBMS에서 scale-out 하는 것은 어렵습니다. 사견입니다만 RDBMS에서 수백 수천대로 scale-out 할 수 있다면 Oracle 등의 전통적 DBMS 강자들이 이미 관련 제품을 내놓지 않았을까요?
RDBMS의 테이블이 여러 컴퓨터에 분산되어 있고, 고 가용성을 위해서 각 데이터는 복제 되어 저장된다고 생각해 봅시다.
우선 ACID를 만족시키며 분산 transaction을 수행하는 것은 scale-out 하기 어렵습니다.
• ACID 속성 중 atomicity를 만족하기 위해서는 2PC 프로토콜과 같은 분산 트랜잭션 프로토콜이 특정 트랜잭션에 관련되어 있는 시스템간에 이뤄져야 합니다.
• ACID 속성 중 isolation level을 맞추기 위해서는 일반적으로 데이터를 locking해야합니다. Locking의 단위는 레코드, 테이블, 인덱스 등이 될 수 있습니다.
• 따라서 분산된 환경에서 Atomic과 Isolated 속성을 만족하기 위해서는 분산 트랜잭션 프로토콜이 진행되는 동안에 관련된 모든 lock이 각 시스템에 걸려 있어야 함을 의미하고, 이러한 방식은 시스템의 서비스 부하가 높아 질수록 많은 lock 경합이 이루어지는 것을 의미합니다. 이러한 경합 때문에 scale-out 하기 어려워 집니다.
그 다음으로 데이터를 복제 분산해서 scale-out 하는 것은 한계가 있습니다.
• 2PC 방식의 transactional replication 방식은 복제 관계에 있는 시스템 중의 하나가 failure 상태로 가는 경우 트랜잭션이 실패하게 되어서 비가용 상태로 빠지는 문제점이 있습니다. 또한 복제 관계에 있는 시스템이 여러 대 있을 때 성능 저하가 일어나는 방식입니다.
• 다른 방식으로 DBMS의 WAL(Write Ahead Logging) 데이터를 복제 시스템으로 전달해서 이를 반영하는 방식을 생각할 수 있습니다. 데이터의 변경이 이루어지는 시스템을 master(또는 primary)라고 하고 데이터의 변경이 적용되는 시스템을 slave(또는 backup)라고 했을 때, master-slave 나 multi-master와 같은 구성을 하게 됩니다.
• Master slave 구성을 하는 경우: 가장 일반적인 복제 방식입니다. 이 방식에서 복제 관계에 있는 시스템이 늘어나면 속도가 이에 비례해서 낮아지게 됩니다
• Multi-master 구성을 하는 경우: 여러 master에서 일어나는 데이터의 쓰기 작업이 상호 충돌을 일으키는 경우 이를 방지하거나 발생했을 때 해결하는 것은 매우 어렵습니다. [2]에서 저자인 Jim Gray는 여기에 대한 연구를 했습니다.[1] (데이터베이스와 트랜잭션 처리 관련된 공적으로1998년에 Turing Award 수상)
개발자에 의한 sharding
일반적인 관점에서 DBMS의 데이터 모델에서 ACID 속성을 만족 시키면서 scale-out 하기는 매우 어렵습니다. 따라서 DBMS 기반으로 scale-out 하기 위해서는 데이터 모델 자체를 단순하게 구성해 데이터를 N개의 서로 독립적인 데이터로 분할하는 방식을 취하고 이 분할 된 데이터 안에서 쿼리가 이루어지도록 개발합니다.
분할 된 데이터 단위를 shard라고 하고 N개의 shard를 M 대의 DBMS 서버에 나누어 서비스 합니다. Shard를 관리하는 것은 DBMS가 아니라 서비스 개발자가 잘 해야 할 일이 됩니다.
이러한 개발자 중심의 sharding 방식은 다음과 같은 어려움이 있습니다.
• Shard 를 정의하는 작업이 일단 필요하겠습니다.
• Shard mapping
• DBMS에서 저장의 기본 단위는 테이블 입니다. 한 테이블에 하나 이상의 shard가 들어가게 되는데 특정 shard가 어느 데이터베이스instance의 어느 테이블로 mapping 되는지 알아야 합니다. 응용 프로그램이 이 정보를 알고 있어서 해당되는 shard 테이블의 위치를 알아야 합니다
• Shard 분산/재분배:
• 각 shard가 똑같지 않으므로 처리량 요구사항이나 데이터 사이즈가 shard 마다 다를 수 있습니다. 이 경우 새로운 데이터베이스 instance를 추가/제거 하고 shard를 재분배 작업이 일어나야 하는데, 개발자가 일일이 신경 써야 하므로 인적 장애가 많이 생길 수 있는 부분이 발생합니다
• 분산/재분배에 의해서 변경된 mapping 정보는 응용 프로그램에 반영이 되어야 합니다
• 변경에 따르는 복제 설정 등의 관리 작업을 해야 합니다
NoSQL의 접근 방식
인터넷 스케일의 데이터 저장시스템은 데이터의 분산을 통한 scale-out 방식의 확장을 지향하고, 고 가용성을 위해 복제를 합니다. RDBMS에서 제공하는 관계 모델과 ACID 속성의 트랜잭션을 지원하는 방식 하에서 scale-out이 어렵다는 것을 알아 보았습니다. 이제 NoSQL 진영에서는 어떠한 접근 방식을 취하는지 알아 보겠습니다.
데이터 모델을 단순화해서 sharding을 한다
쿼리 연산의 데이터 closure가 분산의 기본단위가 되고, 이 단위를 모아서 적당한 수준의 shard를 만들 수 있도록 데이터 모델이 단순하게 구성됩니다. 분산의 기본단위는 key입니다.
• 가장 간단한 모델은 데이터를 하나의 immutable 객체로 봐서 데이터 전체에 대한 읽기 쓰기 만을 지원하는 모델입니다. key-value storage중에서 blob 형태의 데이터 모델을 지원한다고 하는 Dynamo, Membase 가 이 부류에 속한다고 할 수 있습니다.
• Google file system에서 하나의 파일의 구성 단위인 chunk는 globally unique한 64bit identifier를 가지며 기본적으로 chunk에 대한 연산은 chunk의 byte range에 대한 read/write/append(마지막 chunk의 경우) 연산을 지원합니다. 사용자에게 제공되는 저장 abstraction은 파일이지만 이 파일에 대한 연산은 API level에서 chunk 단위로 환원됩니다.
• Blob 형태의 immutable 객체 모델 보다 좀더 복잡한 데이터 모델을 제공하는 시스템도 있습니다.
• Key-Value DB: 데이터를 list, set과 같은 ADT(Abstract Data Structure)로 모델링 해서 해당 구조체에 대해 가능한 연산을 쿼리로 제공하는 database. Redis나 Tokyo Cabinet등이 대표적
• Document-oriented: Object representing notation을 이용해서 임의의 비정규화된 object를 저장하고 object의 property 기반으로 쿼리를 제공해주는 CouchDB나 MongDB가 대표적
• Bigtable, Cassandra와 같이 row-column-timestamp나 row-column family-column 구조의 multi-dimensional map 형태의 데이터 모델을 지원하는 시스템
기본적으로 쿼리는 이 분산 단위의 읽기 쓰기를 지원하지만, 여러 분산 단위에 대한 집계 연산 등을 하기 위해서 map-reduce와 같은 별도의 쿼리 방식을 지원하기도 합니다. 또한 MongoDB와 같은 document-oriented 저장시스템은 document ID 이외에 document의 특정 property에 대해 index 를 걸 수 있도록 해서 빠른 접근 경로를 추가적으로 사용자가 정의할 수 있도록 하고 있습니다.
분산
• Hash 기반
• key 자체의 의미를 따지지 않으므로, 처리량 요구나 데이터 크기에 대해서 자연적인 분산이 이루어 집니다.
• node의 추가/삭제에 의한 mapping 및 재분배 문제를 최소화 하기 위해서 consistent hashing 기반의 분산을 주로 합니다.
• Index 기반
• key 기반의 order-preserving을 유지해서 범위 쿼리가 가능하도록 합니다.
• 메타데이터 서버 기반
• 분산 단위의 위치 정보를 별도의 메타데이터 서버에서 관리하는 방식입니다.
쿼리의 ACID 속성을 완화한다
쿼리 연산의 일관성을 RDBMS의 ACID 속성보다 완화한 형태를 사용합니다. 복제까지 포함해서 생각해 보면 이와 같은 쿼리 속성 완화 현상은 두드러집니다. CouchDB처럼 ACID 속성을 유지해주는 시스템도 있지만, 많은 경우 고가용성을 위해, Consistence나 Isolated를 완화합니다.
몇몇 시스템이 어떻게 완화 하는지 구체적으로 알아 보겠습니다.
• GFS에서는 여러 클라이언트가 동시에 한 파일에 쓰기를 하거나 record append 연산을 할 수 있습니다. 여러 클라이언트의 동시적인 쓰기 작업은 비록 모든 replica에 대해서 동일한 값을 보게 되지만, 각 클라이언트의 write는 (논문 표현으로는) undefined 입니다. Record append 연산은 각 replica에 대해서 적어도 한번은 atomic 하게 쓰인다는 형태의 파일 영역에 대한 일관성 보장을 해줍니다.
• Dynamo의 경우 ‘always writeable’ 해야 하는 서비스 요구에 의해서 quorum 프로토콜의 변형인 sloppy quorum 방식의 복제 및 읽기에 대한 view consistency를 보장하는 방식을 사용합니다. Quorum 프로토콜 방식은 네트워크의 분할이 발생하더라도 정보의 불일치가 생기지 않도록N개의 복제 관계에 있는 시스템간에 R (읽기), W(쓰기) 각 연산에 대해 수행 되야 하는 시스템의 정원의 개수를 정하는 방식입니다 (R + W > N, W > N/2). Dynamo의 경우는 시스템이 일시적 장애에 대비하기 위해서 Hinted-handoff 방식으로 다른 시스템이 자신이 담당하고 있지 않은 key에 대한 쿼리 연산을 할 수 있도록 합니다 (sloppy quorum). 발생할 수 있는 데이터의 불일치는 각 시스템이 데이터에 대한 버전을 관리하고, vector clock 기법을 사용해서 복제 관계에 있는 시스템 들이 유지하는 데이터의 변경에 대한 causal order 를 판단할 수 있도록 해서 읽기 연산을 수행할 때에 시스템이 자동적으로 최신의 (reconciled) 데이터를 판단하거나, 판단이 불가능 한 경우 여러 버전의 데이터를 클라이언트에 전송해서 클라이언트가 판단하도록 합니다.
• Cassandra의 경우 N개의 복제 관계에 있는 node에서 몇 개가 읽기나 쓰기가 성공해야만 하는지에 대해 사용자가 지정을 할 수 있도록 해서 일관성 수준을 조절할 수 있도록 해줍니다. 쓰기의 경우 (Zero, Any, One, Quorum, All) 읽기의 경우 (One, Quorum, All) 지정할 수 있는 option을 제공합니다. Dynamo와 유사하게 timestamp 기반의 ordering을 통해서 read-repair 해서, 읽기 시의 consistency (view consistency)를 제공합니다.
NoSQL 시스템을 분류해 보자
대표적인 NoSQL 저장시스템을 분류해 보겠습니다.
시스템 | 데이터 모델 | 분산 단위 | 분산 방식 | 복제 |
GFS | GFS | chunk | 메타데이터서버 | master-slavea |
Big table | multi dimensional map | row | index (B+tree like) | GFS에 의존 |
Cassandra | multi dimensional map | row | hash/indexb | optional |
MongoDB | Document (JSON) | document | indexc | master-slave |
CouchDB | Document (BSON) | document | indexd | master-master |
Dynamo | Blob | blob | hash | sloppy quorum |
a 전체 시스템이 하나 존재하는 Master node가 replication 관계에 있는 chunk server (replica) 중 하나에 chunk에 대한 쓰기 권한을 빌려주는 방식을 사용합니다. Lease를 받은 replica를 primary라고 부릅니다. Master node에 대한 부담을 줄이기 위해 primary가 살아있는 동안 lease를 연장하는 방식을 사용합니다 (heart beat 메시지에 piggy backing 함)
b 기본적으로 consistent hashing을 하지만 설정으로 Partitioner를 결정할 수 있도록 해 줍니다. (random, order preserving, collating order preserving)
c User defined index 생성 가능
d ID 및 Sequence Number에 대한 index. Sequence Number는 update 마다 증가
어떤 저장시스템을 써야 하지?
“내가 만드는 서비스에 어떤 저장시스템을 써야 하지?” 에 대해 고려할 사항을 적어보겠습니다.
RDBMS는 아직도 기본
우선적으로 고려해야 합니다. 읽기/쓰기 연산이 ACID 형태의 일관성을 요구하는 경우에는 더욱 필수입니다. RDBMS 구성과 추가적인 저장시스템으로 많은 경우 서비스 부하를 분산시킬 수 있습니다.
• 복제를 통한 읽기 분산
• MySQL Cluster와 같이 OLTP 영역에서의 RDBMS scale-out 기술도 고려 대상이 될 수 있습니다. [2]
• RDBMS + Cache + Storage system
• RDBMS 자체의 성능이 부담이 되는 경우, 자주 사용하거나 쿼리 수행 시간이 오래 걸리는 item에 대해서 Arcus와 같은 caching system을 사용할 수 있습니다. 물론 cache하는 데이터에 대한 일관성 모델을 잘 고려해야 합니다.
• 대량의 데이터 저장에 대한 요구가 있다면, 이러한 데이터에 대해서 OwFS와 같은 별도의 storage system을 사용할 수도 있습니다.
• 마지막으로 개발자 구현하는 sharding 기법이 있습니다. 복제, 장애 처리, 복구, shard 분산/재분배의 어려움을 이겨내야 하지만 말입니다.
NoSQL
RDBMS 기반으로는 구현하려는 서비스를 제대로 만들 수 없다고요? 그럼 NoSQL을 사용해야죠. NoSQL의 공통적인 장점은 복제, 장애 처리, 복구, shard 분산/재분배의 어려움을 시스템이 해결해 주는 것입니다. 서비스가 요구하는 데이터 모델 및 일관성과 NoSQL 시스템의 궁합이 맞으면 아주 좋은 선택이 될 수 있습니다. 데이터 모델 별로 장/단점을 알아보도록 하겠습니다.
• Key-Value(blob)
• 단순한 모델인 만큼 속도가 빠른 것이 주 장점입니다.
• Key 단위의 원자적 쓰기/읽기 만을 지원하는 경우가 많습니다. 이 경우 여러 key의 value에 동시 처리를 하면서 serialize 할 수 있는 방법은 없습니다.
• 메모리를 저장소로 사용하는 경우 아주 빠른 get/put을 지원하는 것을 목적으로 하고 있습니다.(내가 서비스하려는 데이터의 양이 메모리 안에 다 들어가는 경우가 제일 좋겠죠.)
• Key에 대한 단위 연산이 빠른 것이지, 여러 key에 대한 연산은 고정적으로 네트워크 전송 지연이 포함되기 때문에 느릴 수 있습니다. (RDBMS테이블에 10만 row 데이터를 select 하는 것과 Key-value 단위로 10만 번 읽는 것은 비교할 수 없을 정도로 Key-Value DB가 느립니다. 10만 건이 아니더라도 10개 100개만 되더라도 성능 차이가 납니다.)
• Key-Value(Structure)
• List, Set 과 같은 ADT를 제공하는 모델이고, 장점은 한 key에 대해 여러 값을 저장할 수 있는 것입니다. Key-BLOB모델에서는 단일 값만Value로 사용할 수 있어서 여러 Key를 사용해 저장해야하는 데이터를 하나의 key만 사용하여 저장할 수 있습니다.
• 단순히 get/set하는 모델보다는 처리 시간이 오래 걸립니다. (하지만 그리 많은 차이가 나지는 않습니다. 데이터 모델에 기인한 성능 차이는 시스템을 어떻게 효율적으로 잘 구현했는가로 극복할 만한 수준이라 생각됩니다.)
• Document oriented
• schema 없이, 임의의 property 를 추가할 수 있는 데이터 모델입니다.
• 이름에서 드러나듯 JSon이나 XML 같은 문서 데이터를 저장하기 적합한 구조입니다.
• Document id나 특정 property 값 기준으로 order-preserving 하는 경우가 많습니다. (이 경우 해당 key 값의 range에 대한 효율적인 연산이 가능해 지므로 이에 대한 쿼리를 제공합니다.)
• 쿼리 처리에 있어서 데이터를 parsing 해서 memory 연산을 해야 하므로 처리 overhead가 key-value나 key-structure 모델보다 크다 할 수 있습니다. (큰 크기의 document를 다룰 때 성능 저하가 발생합니다.)
• Multi-dimensional map
• Bigtable의 경우 row-column-timestamp에 의해서 데이터를 mapping 하고, 데이터 자체는 binary 값입니다.
• Cassandra의 경우 row-column families-column 형태로 데이터를 mapping 하고 데이터 자체는 binary 값입니다.
• 두 모델 모두 데이터 (column)에 대한 grouping 과 access 방식을 구조화 하는 방식으로 데이터를 모델링 할 수 있도록 해줍니다. 자세한 모델링 방법은 이 문서에 적기에는 좀 어렵네요. Cassandra 홈페이지와 [10]번을 참고하시길 바랍니다.
나가며
변하는 데에서 변하지 않는 것을 찾는 것이 학문을 하는 사람이 취해야 할 자세라면, 변하지 않는 부분을 변화시켜 보는 것이 문제를 푸는 개발자의 자세가 아닌가 생각해 봅니다.
Not Only SQL을 위해서~
참고 문헌
[1]. WIKI: Replication(computer science)
http://en.wikipedia.org/wiki/Replication_(computer_science)
[2]. Jim Gray, Pat Helland, Patrick O’Neil, Dennis Shasha – The Danagers of Replication and a Solution: In ACM SIGMOD ‘96
[3]. The problems with ACID, and how to fix them without going NoSQL - http://dbmsmusings.blogspot.com/2010/08/problems-with-acid-and-how-to-fix-them.html
[4]. Werner Vogels, Amazon.com: Eventually Consistent. In ACM Queue Vol6, Issue 6
[5]. Dan Pritchett, E-bay: BASE: An ACID Alternative. In ACM Queue Vol6, Issue 3
[6]. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung: The Google File System
[7]. Fay Chang , Jeffrey Dean , Sanjay Ghemawat , Wilson C. Hsieh , Deborah A. Wallach , Mike Burrows , Tushar Chandra , Andrew Fikes , Robert E. Gruber: Bigtable: A distributed storage system for structured data
[8]. A Lakshman, P Malik – Cassandra: a decentralized structured storage system, In ACM SIGOPS Operating Systems Review, 2010
[9]. Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and Werner Vogels – Dynamo: Amazon’s Highly Available Key-Value Store In ACM SIGOPS 2007
[10]. http://arin.me/blog/wtf-is-a-supercolumn-cassandra-data-model
[1] 데이터베이스가 N개의 서로 독립적인 부분으로 나뉘지 않는 이상, 복제 관계에 있는 N개의 시스템은 동시성 처리 문제 때문에 심각한 성능 저하를 가져올 수밖에 없다
“Update anywhere-anytime-anyway transactional replication has unstable behavior as the workload scales up: a ten-fold increase in nodes and traffic gives a thousand fold increase in deadlocks or reconciliation”
'DB > NoSQL' 카테고리의 다른 글
| nosql - 도입 사례 (0) | 2013.04.29 |
|---|---|
| nosql - 개념 설명 (0) | 2013.04.29 |
| nosql - reference site (0) | 2013.04.29 |
| nosql - 주의 사항 (0) | 2013.04.29 |
| nosql - list (0) | 2013.04.29 |





