NoSQL을 여행하는 히치하이커를 위한 안내서, 송기선
[출처] NoSQL을 여행하는 히치하이커를 위한 안내서, 송기선|작성자 개발자센터
이 안내서는 The Platform 2010년 10월호 NoSQL 특집편을
쉽게 읽을 수 있도록 제작한 안내서이다.
NoSQL 세계에는 도무지 친해질래야 친해질 수 없는 개념과 용어들이 많다.
이 안내서를 읽고나서 NoSQL 세계에서 당황하지 않도록 해보자.
NoSQL(Not only SQL)?
1970년대 이후 데이터를 다루는 가장 좋은 방법은 RDBMS를 사용하는 것이었다. ‘데이터는 RDBMS에’, ‘데이터 조작을 위해서는 SQL을’이라는 당연했던 생각이 최근 흔들리고 있는 가장 첫 번째 이유는 실시간으로 다루어야할 데이터가 폭발적으로 증가했기 때문이다.
데이터가 아무리 많아도 ‘어느 데이터가 어느 RDBMS에 있는지 쉽게 알 수 있고’, ‘각각의 RDBMS가 서로 다른 데이터를 취급하고 있다면’ RDBMS를 사용하는 것이 여전히 좋은 방법이 아닐까 생각할 수 있을 것이다. 그러나 이 경우에도 RDBMS를 사용하는 것이 곤란할 수 있다.
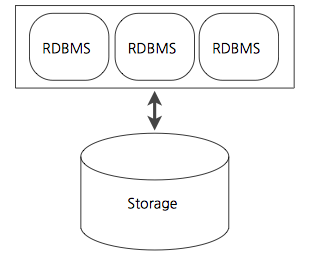
데이터 양과 데이터 처리 요구양을 예측할 수 있다면 위와 같은 시스템을 사용할 수 있을 것이다. (물론 MySQL 등 많은 DBMS가 위 그림과 같은 형태의Clustering을 제대로 지원하는 것은 아니다.)
그러나 데이터가 지속적으로 증가할 때, 그리고 데이터 처리 요구양이 가변적이라면 다른 방식이 필요할 것이다.
즉 ‘데이터 처리를 하는 서버 애플리케이션 개수를 동작 중에 늘리거나 줄이고’(RDBMS 인스턴스 같은), ‘논리적으로 하나의 저장소이면서 언제든지 수평 확장할 수 있는’ 시스템이 필요한 것이다.
보다 더 강력한 High Availability와 Horizontal Scalability를 지원하는 Database가 필요한 것이다.
Schema또한 문제가 된다. Schema는 데이터를 잘 사용하기 위한 방법이라는 게 일반적인 상식이나, 수십/수백 개 또는 그 이상되는 RDBMS table을 일괄적으로 변경하려면 긴 시간의 down time이 발생할 수 밖에 없다.
그래서 Schemaless design이 이야기되고 있는 것이다. 잘 정규화된 데이터 구조보다는 필요에 따라 쉽게 변경할 수 있는 유연성이 더 필요한 기능인 것이다.
정확한 정의는 아니지만 쉬운 이해를 위해 NoSQL은 거대한 Map(Key와 Value를 가지는)이라고 할 수 있다. Map<String, Map<String,Object>>를 여러 개의 저장소에 저장하여 많은 데이터를 다룰 수 있도록 한 것이다.
이때 저장소는 Memcached나 Arcus같이 메인 메모리일 수도 있고, Cassandra나 MongoDB와 같이 디스크일 수도 있다.
이러한 이유로 흔히 Key-Value DB가 NoSQL을 일컫는 것처럼 쓰이고는 한다. Key-Value DB 이외에 다른 NoSQL 종류로는 Graph DB나Documented Oriented DB, Column-Oriented DB가 있는 데, 모두 Map(Key-Value) 구조로 이해할 수 있다.
이렇게 데이터를 Map으로 표현하면 당연히 Schemaless design이 된다.
이런 Key-Value DB는 근래 만들어진 개념이 아니다. 지금의 RDBMS가 체계화되기 이전에 사용한 방식이기도 하고, 임베디드 시스템에서 많이 사용하는 Berkley DB같은 embedded DB에서 사용하는 방식이기도 하다.
NoSQL의 핵심 사항은 위에서 말한 Horizontal Scalability과 High Availability이다. 저장소를 손쉽게 동적으로 추가할 수 있으며, 저장소에 장애가 발생해도 전체 시스템에는 장애가 없어야하는 것이다.
앞서 말했 듯이 Schemaless는 Map(Key-Value) 구조의 데이터 모델을 사용하면서 얻을 수 있다. 그렇다면 Horizontal Scalability과 High Availability는 어떻게 얻을 수 있는 것일까?
NoSQL 구현체마다 다른 아키텍처를 가지고 있지만 대략적인 구조는 다음과 같다고 할 수 있다.
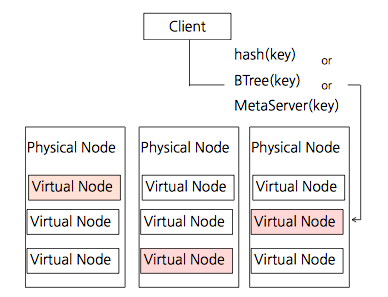
Physical Node란 하나의 서버 머신을 말한다. 이 서버에는 여러 개의 NoSQL 서버 인스턴스를 가동할 수 있는데, 이것이 바로 Virtual Node이다. 각각의 Virtual Node는 자기가 관리하는 Disk Set이 있다.
이렇게 Physical Node에 Virtual Node를 여럿 둘 때의 장점은 Availability나 Scalability이외에도 Physical Node의 성능에 따라, 알맞은 개수의Virtual Node를 두어 Utilization을 꾀할 수 있다는 것이다.
Client는 key를 hashing하여 Virtual Node에 접근 할 수도, Tree를 사용할 수도, Node 정보를 알고 있는 별도의 Meta 정보를 관리하는 서버를 통하여Node에 접근할 수 있다.
같은 데이터를 관리하는 Virtual Node를 두어 Data Replication을 한다. Replication된 데이터에 접근할 수 있는 방법이 명확하다면 High Availability를 보장할 수 있을 것이다. 동적으로 Virtual Node를(또는 Physical Node를) 추가/삭제하고 이때마다 자동으로 데이터가 복제/분산된다면Horizontal Scalability도 보장할 수 있을 것이다.
결국 각각의 NoSQL들은 위 다이어그램을 어떻게 구현했느냐의 차이라고 할 수 있다.
API 모델에서 말한다면, ‘Key는 어떤 형태인가? (Key에 prefix등이 있는가?)’ ‘Value는 어떤 형태인가? (Value로 사용할 수 있는 타입으로는 어떤 것들이 있는가? String, JSon, Serialized Object 등)’일 것이다.
그 다음 생각해 볼 수 있는 것은 어떻게 Virtual Node를 찾아 갈 수 있을 것인가이다.
Hashing function을 사용하는 경우를 이야기해보자면, 일반적인 Hashing function으로는 Virtual Node의 추가/삭제에 대응할 수 없다. hash(key)에 해당하는 Virtual Node가 없다면 데이터를 읽거나 쓸 수 없을 것이다. 설사 있다고 하더라도, replication된 Virtual Node에서 값을 읽을 수 없다면 읽기 성능 향상 기회를 놓치게 되는 것이다.
그리고 어떻게 Replication을 하는 것인가도 중요한 사항이다. Client가 Virtual Node마다 값을 써야하는지 최초 쓰여진 Virtual Node가 Replication대상 Virtual Node에 쓰는 것인지에 대한 방법 차이가 있다. 또한 N개의 replication이 있다고 할 때 N개가 모두 쓰여진 다음에 ‘쓰기 성공’ 결과를 알려야하는지 하나 또는 몇 개의 쓰기만 성공하면 ‘쓰기 성공’이라고 결과를 알려야하는지 방법/구현 상의 차이가 있다.
무엇보다 중요한 점은 Consistency이다. 여러 개의 Client에서 동일 key에 대한 value를 변경하였을 때의 처리이다. RDBMS는 엄격한 Consistency를 보장하나(Strict Consistency), Cassandra, Dynamo, Tokyo cabinet 등은 RDDBMS 보다는 보다 정도가 낮은 Eventually Consistency 모델을 사용한다.
Consistent Hashing
일반적인 hash function을 떠올리자면, ‘key mod N’일 것이다. 이것의 가장 큰 문제점은 Node의 수 N이 변했을 경우이다. Node를 자유롭게 추가/제거할 수 없다면 Scalability보장이 곤란하다. 그래서 새로운 hash function이 필요한데 이를 해결해줄 수 있는 것이 Consistent Hashing이다.
Consistent Hashing의 개념은 매우 단순하다. 다음과 같은 원을 보자.
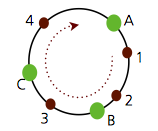
key와 node를 모두 hash하면 int로 표현할 수 있고 다음과 같이 나타낼 수 있다. 초록색 원은 Node이고, 붉은 색 점은 key를 나타낸다.
위 그림에는 총 3 개의 Node(A~C), 4 개의 key(1~4)가 있다. Consistent Hashing의 중요 포인트는 key와 Node를 모두 hashing한다는 것이고, hash(key)에 인접한 hash(node)값을 가지는 node에 value를 저장한다는 것이다.
즉 hash(key) 값이 1, 2인 key는 Node B에 value가 저장된다. 역시 3은 C에, 4는 A에 저장된다.
만약 Node A와 B가 제거되고, Node E가 추가되었다면 다음과 같을 것이다.
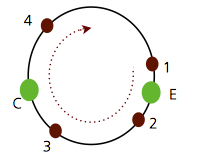
이 때, 4와 1은 E에 2와 3은 C에 저장된다.
Consistent Hashing을 사용하면 replication 또한 쉽다. hash( key + 1), hash(key + 2), hash(key + ...) 하는 식으로 replication 개수만큼 Node에 저장하면 된다. 역시 값을 찾을 때도 hash(key)를 통하여 찾을 수 없다면 hash(key + ...)와 같은 방법으로 값을 읽어올 수 있다.
Data Replication
Consistent Hashing을 이용하여 replication을 한다 하더라도 몇 가지 문제가 남는다. ‘Node 정보(살아 있는 Node list)를 client가 어떻게 아는가?’와‘Replication을 누가하는가?’이다.
Node List를 client가 알고 있어야하면 제대로 Availability를 보장하기 어렵기때문에 Client와 Server 사이에 미들웨어가 필요하다.
역시 쓰기 또한 이 미들웨어가 최초로 담당하게 되는데, replication 쓰기 방법에 따라 Master-Slave 모델인지, No Master(Multi Master)모델인지로 나눌 수 있다.
앞서 말한 미들웨어에서 모든 replication에 정보를 쓸 수도 있지만(즉 모든 쓰기를 마친 다음 client에 통보) Master Node에 쓰기를 명령한 다음 이후Replication은 Master Node에 맡기고 미들웨어는 client에 쓰기 완료를 알릴 수 있다. (이 경우 Strict Consistency 보장이 어렵다.)
Master-Slave 모델에서 Master는 hash(key)에 해당하는 것일 것이고 Slave는 hash(key + ...)에 해당하는 것이다. 읽기/쓰기 비율이 높을 때, 즉 일반적으로 읽기 작업이 많을 때 유리하다. 읽기는 여러 replica에서 읽을 수 있기 때문이다. 이 때 Master가 Slave에게 replication을 하는 방법으로State Transfer와 Operation Transfer가 있다. State Transfer는 저장한 상태만을 전달하는 것이고 Operation Transfer는 node가 받은 operation그 자체를 replica node에 전달하는 것이다.
Multi Master 모델은 쓰기 오퍼레이션이 많을 때 고려할 수 있다. 즉 hash(key), hash(key + ...) 중 어느 하나에 최초로 값을 쓰고, 알고리즘에 따라 각각의 replica에 복제가 되는 방식이다. 이 방식을 사용할 경우 version, time vector 등의 방법이 필요하다.
CAP Theorem
CAP Theorem은 Database가 Consistency, Availability, Partitioning를 모두 만족할 수 없고, 둘만 만족할 수 있다는 것이다.
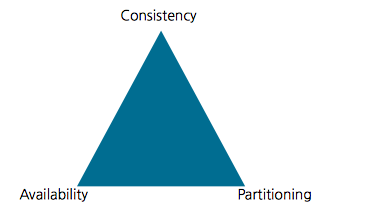
• Consistency: 모든 client가 언제가 같은 상태의 데이터를 바라볼 수 있다.
• Availability: 모든 client가 언제나 데이터에 접근할 수 있다.
• Partitioning: Database가 물리적으로 전혀 다른 Network 공간(IDC가 다르거나 등)에 위치할 수 있다. Network공간 사이가 단절되어도 시스템은 동작할 수 있어야한다.(Partition Tolerance)
일반적으로 RDBMS는 Consistency와 Availability를 만족한다.
반면 NoSQL 제품군들은 크게 Availability와 Partitioning을 만족하는 제품군과 Consistency와 Partitioning을 만족하는 제품군으로 나눌 수 있다.
구글에서 사용하는 BigTable, Documented-Oriented로 유명한 MongoDB, 오랜 역사로 많은 사용자를 확보하고 있는 Berkley DB는 Consistency와Partitioning을 만족하는 제품이다.
반면 Key-Value DB로 유명한 Tokyo Cabinet(물론 Tabular도 지원한다.), Column-Oriented인 Cassandra, Document-Oriented인 CouchDB 등은 Availability와 Partitioning에 좀 더 중점을 두고 있다.
NoSQL을 사용하는 가장 큰 이유가 대용량 데이터 처리인만큼 Partitioning은 반드시 추구해야할 항목인 것이고, 유즈케이스에 따라 Availability 또는Consistency 중 하나를 선택하는 것이다. 즉 시스템이 항상 동작해야하는 것인가와 데이터는 언제나 정확해야하는 것인가 둘 중 하나를 선택해야한다는 것이다.
Consistency에도 여러 모델이 있다. 앞서 (Strict) Consistency를 보장하지 않는다고 밝힌 Cassandra 같은 경우, Eventually Consistency 모델을 사용하고 있다. Eventually Consistency란 concurrent하게 동일 데이터를 여러 client가 읽으려할 때, 어떤 client에서 그 데이터를 쓰고 있는 중이라면 채update가 끝나기 전의 값 상태를(모든 컬럼의 업데이트가 완료되지 않은) 읽을 수 있다는 뜻이다.
바로 이 점이 RDBMS와의 큰 차이점이라고 할 수 있다. 모든 RDBMS는 ACID를 지향한다.
• Atomic: 데이터 업데이트는 성공하거나 실패하거나 이다. 데이터 업데이트 도중 그만둘 수 없다.
• Consistent: 데이터 업데이트 작업은 항상 consistent 상태여야한다. 업데이트 작업이란 어떤 consistent 상태에서 다른 consistent 상태로 변하는 것을 말한다.
• Isolated: 어떤 세션에서 데이터 업데이트를 하고 있을 때 트랜잭션이 끝나지 않았다면, 다른 세션에서 변경한 값을 절대 볼 수 없다.
• Durable: 트랜잭션이 끝났다면, 시스템에 장애가 발생한다하더라도 변경한 값은 유지되어야한다.
반면 NoSQL 제품군들은 위 ACID 항목에서 하나 또는 그 이상을 만족하지 않는다. 이런 것을 BASE(Basically Available, Soft state, Eventually Consistency)라고 부른다.

이 정도 용어와 개념을 익혔다면, 지금부터 이어지는 The Platform 10월 NoSQL 특집편 기사들을 이해하는데 무리가 없을 것이다.
중요한 것은 설사 이해되지 않는 부분이 나타나더라도 절대 당황하지 않는 것이다.
[출처] NoSQL을 여행하는 히치하이커를 위한 안내서, 송기선|작성자 개발자센터
'DB > NoSQL' 카테고리의 다른 글
| nosql - 도입 사례 (0) | 2013.04.29 |
|---|---|
| nosql - 분류 기준 (0) | 2013.04.29 |
| nosql - reference site (0) | 2013.04.29 |
| nosql - 주의 사항 (0) | 2013.04.29 |
| nosql - list (0) | 2013.04.29 |





