리눅스 2.4 패킷 필터링 하우투
Rusty Russell, mailing list netfilter@lists.samba.org
v1.0 Tue Mar 21 23:29:42 EST 2000
이 문서는 2.4 리눅스 커널에서 잘못된 패킷을 필터링하기 위하여 어떻게 iptables 을 이용하는가를 기술한다.
여러분 환영합니다.
이 문서는 여러분이 IP address, network address, netmask, routing, DNS 가 무었인지 알고 있다고 가정합니다. 그렇지 않다면 '네트워크 개념 하우투' 를 읽기를 권유합니다.
이 하우투는 상냥한 소개(이게 여러분을 열받게 하고 지금은 흐리멍텅하고 그러나 무방비인)와 가공되지않은 완전 노출(which would leave all but the hardiest souls confused, paranoid and seeking heavy weaponry)사이를 넘 나들 것이다.
여러분의 네트워크는 안전하지 않다. 빠르고, 편안하면서 그 사용이 좋은 쪽으로만 하도록하고 악한 시도를 허락하지 않도록 하려는 것은 복잡한 영 화관에서 자유로운 대화는 허락하면서 "불이야"하고 외치는 것은 불허하는 것처럼 거의 해결불능의 문제와 같다. 이것에대한 해답은 이 하우투에서 구할 수 없을 것이다.
여러분이 할 수있는 것은 그 절충점을 결정하는 일이다. 나는 이러한 목적 으로 사용할 수 있는 몇몇 도구와 경계하여야할 약점에 대하여 여러분이 좋은 목적으로 사용하고 악의있는 목적으로 사용하지 않기를 바라며, 알려 주려고 한다. 또다른 어려운 문제이다.
세개의 웹사이트가 있다.
netfilter의 메일링 리스트를 위해서는 삼바의 리스트 서버를 보라.
패킷필터는 지나가는 패킷의 해더를 살펴보고 그 전체 패킷의 운명을 결정하는 소프트웨어의 일부이다. 이것은 패킷을 'DROP'(즉, 마치 전혀 전달되지도 못 했던것 처럼 패킷을 거부) 하던가, 'ACCEPT'(즉, 패킷이 지나가도록 내버려 둠) 하던가 또는 다른 더욱 복잡한 무엇을 할 것인가를 결정할 것이다.
리눅스에서 패킷 필터링은 커널 내부에 구성되고(커널의 모듈로서 또는 그 내부에 포함 되는 형태이다), 우리가 패킷으로 해야할 몇몇 복잡한 것이 있다. 그러나, 그 패킷의 헤더를 관찰하고 그 패킷의 운명을 결정하는 기본 원칙은 여전히 적용 된다.
제어, 보안, 관찰가능성
- 제어:
여러분이 내부 네트워크에서 다른 네트워크로 리눅스 박스를 이용하여 접속을 하고자 할때(소위, 인터넷) 여러분은 어떤형태의 전송은 가능하게 하고 다른것은 불가능하게 할 기회를 가진다. 예를 들어, 패킷 헤더에는 목적지의 주소를 포함하고 있고 이것으로 패킷이 바깥 네트워그의 다른곳 으로 가지 않도록 한다. 다른 예로, 나는 Dilbert archives를 호출하기 위하여 넷스케잎을 이용한다. 그곳의 웹페이지에는 doubleclick.net으로 부터의 광고가 있고 넷스케잎은 그 광고를 받기위하여 나의 시간을 소비한 다. doubleclick.net의 주소로 가거나 또는 그곳에서 오는 어떠한 패킷도 허락하지 않도록 패킷필터에게 이야기 해 놓음으로 이 문제를 해결할 수 있다. (이렇게 하는 더 좋은 방법도 있다 : Junkbuster를 보세요)
- 보안:
여러분의 멋지고, 잘 정돈된 네트워크와 인터넷의 혼돈사이에 리눅스 박스 만이 있다면, 여러분의 네트워크로 들어오려는 것을 억제할 수 있다는 것은 근사한 일이다. 예를들어, 여러분은 여러분의 네트워크로부터 나가는 모든 것을 허용하고 싶지만, 반면에 밖으로부터 들어오는, "죽음의 핑"같은, 악의 있는 것에 대하여는 것정이 될 것이다. 다른 예로, 아무리 여러분 리눅스 박스의 모든 계정사용자가 암호를 가지고 있다고 하더도 바깥으로부터의 텔넷시도는 바라지 않을 것이다. 대부분의 사람들처럼 인터넷에서 구경꾼 이 되고 싶고 제공자는 되고싶지 않을 것이다. 간단히 말해서, 접속중에 모든 들어오려는 패킷을 패킷 필터를 이용하거 거부할려고 할 것이다.
- 관찰가능성:
가끔 잘못 설정된 지역네트워크는 패킷을 바깥세상으로 토해놓는다. 패킷 필터에게 어떠한 이상한 일이라도 일어나면 여러분에게 알려 주도록 말해 두는 것은 근사한 일이다. 여러분은 이런 일에대하여 무엇인가를 할 수도 있고 그냥 '이상한 일이네'하고 넘길 수도 있다.
1.1 시리즈 부터 리눅스 커널은 패킷 필터링을 포함하기 시작했다. 제 1세대는 BSD의 ipfw를 기본으로 하였고 1994년 후반기에 Alan Cox에 의해서 포트 되었다. 이것은 리눅스 2.0에서 Jos Vos와 다른이들에 의해서 개선되었고 커널의 필터링 규칙을 제어하는 사용자 툴로는 'ipfwadm'이 사용되었다. 1998년 중반에 리눅스 2.2를 위하여 나는 Michael Neuling의 도움으로 커널에 대하여 열심히 일하였고 사용자 툴료는 'ipchains'를 내놓았다. 마지막으로, 제 4세대 툴이 'iptables'이고 리눅스 2.4를 위하여 1999년 중반에 커널을 제 작성 하였다. 이 하우투 문서가 촛점을 맞추고 있는 것이 이 iptables 에 대한 내용이다.
netfilter를 가지고있는 커널이 필요하다. netfilter는 다른 것들(iptables 모듈 같은)이 붙을수 있는 리눅스 커널의 일반적인 기본 구조이다. 이것은 2.3.15 이상 의 리눅스 커널에 들어있고 커널 설정에서 CONFIG_NETFILTER 에 'Y'로 대답하고 컴 파일한 것이어야 한다.
iptables라는 툴은 커널에게 어떤 패킷을 필터할 것인지를 알려준다. 여러분이 프 로그래머나 변태가 아니라면, 이것이 패킷 필터링을 제어하는 수단이다.
iptables
iptables 는 커널의 패킷 필터링 테이블에 필터링 규칙을 삽입하거나 삭제하는 도구 이다. 이것은 여러분이 무었을 설정했든지, 재부팅시에는 소실된다는 것을 의미한다. 다음번 리눅스가 다시 부팅되었을때 설정 내용들이 재설치 되기를 바란다면 규칙들을 영속시키기를 보아라
iptables는 ipfwadm과 ipchains를 대치한다. 손실없이 iptables 의 사용을 피하고 싶 다면 ipchains와 ipfwadm 사용하기를 보아라.
규칙들을 영속시키기
여러분의 파이어월 설정은 커널에 저장되므로 재부팅시에 손실된다. iptables-save 와 iptables-restore을 구현하는 것은 나의 TODO 리스트에 있다. 이것들이 나오게 되면 정말 좋을 것이다. 약속한다.
그동안은 여러분의 규칙을 설정하는 명령들을 초기화 스크립트에 기록해야 한다. 명 령들중 하나가 실패하였을때를 대비하여 뭔가 이성적인것을 해두어야 한다. (보통 'exec /sbin/sulogin'을 사용한다.)
나는 Rusty이다. 리눅스 IP 파이어월 유지하는 사람이고 적절한 시기에 적절한 장소에 있게된 그냥 워킹코더일 뿐이다. 나는 ipchains를 맹글었다. (실제적인 작업을 한 사람을 볼려면 "How Do I Packet Filter Under Linux?"라는 문서를 보라), 그리고 이번에 패킷 필터링을 구할 수 있을 정도의 많은 것을 배웠다.
WatchGuard는 정말 훌륭한 파이어월 회사이며, 정말 멋진 플럭인 파이어박스를 판매하며 아무것도 하지 않아도 나에게 월급을 준다. 덕분에 나는 이 작품을 만드는데 나의 모든 시간을 소모할 수 있었고, 이전의 작업도 그러하다. 나는 6개월이면 끝마치리라 짐작했지만 12개월이 걸렸다. 그러나 내가 바르게 했다는 생각이 든다. 수많은 수정과 하드디스크 박살과, 한번의 랩탑분실과 몇번의 파일시스템 박살과 한번의 모니터 박살의 결과물이 여기있다.
내가 여기에 있는 동안, 사람들의 잘못된 개념을 고쳐주고 싶다. 나는 커널대왕 이 아니다. 나도 내가 커널대왕이 아닌것을 안다. 왜냐하면 이런 커널에 대한 작 업중 진짜 커널대왕들(David S. Miller, Alexey Kuznetsov, Andi Kleen, Alan Cox 같은) 몇명과 접촉해 봤기 때문이다. 그러나 그들은 심오한 마술을 하느라 너무나 바빴고, 내가 안전한 물 가장자리에서 허우적 거리도록 내버려 두었다.
대부분의 사람들은 단 하나의 PPP 접속만 사용하고 어떤 누구도 이것을 통해서 들어오는 것을 원하지 않는다.
## connection-tracking modules을 삽입한다. (not needed if built into kernel).
# insmod ip_conntrack
# insmod ip_conntrack_ftp
## 내부로부터 오는 것을 제외한 다른 새로운 접속을 막기위하여 새로운 체인을
## 만든다.
# iptables -N block
# iptables -A block -m state --state ESTABLISHED,RELATED -j ACCEPT
# iptables -A block -m state --state NEW -i ! ppp0 -j ACCEPT
# iptables -A block -j DROP
## 입력과 포워드 체인으로부터 그 체인으로 가도록 한다.
# iptables -A INPUT -j block
# iptables -A FORWARD -j block
커널은 '필터' 테이블에 세개의 규칙을 가지고 시작한다. 이것을 파이어월 체인 또는 그냥 체인이라고 한다. 그 세개의 체인은 INPUT, OUTPUT, FORWARD 이다.
이것은 2.0 이나 2.2 커널과는 아주 다르게 움직인다.
이 체인은 아래그림처럼 생겼다.
_____
/ \
-->[ 라우팅 ]--->|포워딩 |------->
[ 판 정 ] \_____/ ^
| |
v ____
___ / \
/ \ | 출력 |
|입력 | \____/
\___/ ^
| |
----> Local Process ----
위 그림에서 세개의 원은 위에서 언급한 세개의 체인을 나타낸다. 패킷이 이 그림에서 동그라미로 나타낸곳에 이르면 그 체인은 그 패킷의 운명을 결정하 기위하여 시험한다. 체인이 그 패킷을 DROP 하라고 하면 패킷은 그곳에서 삭 제된다. 그러나 그 체인이 ACCEPT 하고 하면 이 이 그림의 다음 부분으로 계 속 전달된다.
체인은 규칙의 점검표이다. 각 규칙은 '패킷의 헤더가 이렇게 되어있으면 이 곳에서 무엇을 하라'는 형태로 되어 있다. 규칙이 그 패킷에 맞지 않으면 다 음 규칙을 참고한다. 마지막으로 더이상 고려할 규칙이 없으면 커널은 무엇 을 할 것인가를 결정하기 위하여 그 체인의 정책을 확인한다. 보안을 생각하 는 시스템에서 이러한 정책은 보통 커널에게 그 패킷을 DROP 하도록 한다.
- 패킷이 커널에 도탁하면 그 패킷의 목적지를 확인한다. 이것은 '라우팅' 이라고 한다.
- 이것의 목적지가 이곳이면, 패킷은 위 그림에서 아래쪽 방향으로 전달 되어 입력 체인에 도달한다. 이것이 이 체인을 통과하면 패킷을 기다리 고있던 어떤 프로세서도 그것을 받게 된다.
- 그렇지 않으면, 커널이 포워딩 불능으로 되어있던가, 패킷을 어떻게 포 워딩해야 하는가를 알지 못하면, 그 패킷은 DROP 된다. 포워딩이 가능하 게 되어있고 다른 곳이 목적지이면 패킷은 그림의 오른쪽 방향으로 전달 되어 포워딩 체인으로 간다. 이 체인이 ACCEPT 하게 되면 이것은 포워딩 할 네트워크로 보내진다.
- 마지막으로, 이곳에서 돌아가던 프로그램은 네트워크 패킷을 전송할 수 있 게 된다. 이 패킷은 즉시 출력 체인에 보내진다. 이 체인이 ACCEPT 하게 되면 이 패킷은 그 목적지가 어디든지 보내진다.
iptables는 상당히 자세한 메뉴얼 페이지(man iptables)를 가지고 있다. ipchains 에 익숙하다면 <@@ref>Appendix-Aipchains와 iptables의 다른점을 보아라. 이 둘은 매우 비슷하다.
iptables로 할수 있는 일에는 몇가지 다른것이 있다. 첫번째 작동은 전체 체인을 조절한다. 처음 시작은 세개의 미리 만들어진 체인으로 시작하는 데 이것은 제거될 수 없다.
- 새로운 체인 만들기 (-N).
- 비어있는 체인을 제거하기 (-X).
- 미리 만들어진 체인의 정책을 바꾸기 (-P)
- 어떤 체인의 규칙들을 나열하기 (-L)
- 체인으로부터 규칙들을 지우기 (-F)
- 체인내의 모든 규칙들의 패킷과 바이트의 카운드를 0 으로 만들기 (-Z)
체인 내부의 규칙을 조작하는 몇가지 방법이 있다.
- 체인에 새로운 규칙을 추가하기 (-A)
- 체인의 어떤 지점에 규칙을 삽입하기 (-I)
- 체인의 어떤 지점의 규칙을 교환하기 (-R)
- 체인의 어떤 지점의 규칙을 제거하기 (-D)
- 체인에서 일치하는 첫번째 규칙을 제거하기 (-D)
iptables는 모듈로 되어있을 것이다. 이것은 iptable_filter.o 이다. 이것은 처음으로 iptables를 실행할때 자동으로 로드될 것이다. 이것느 커널에 영구히 포함될 수도 있다.
iptables 명령이 실행되기 전에는 기본적으로 만들어져있는 체인(입력, 포워딩, 출력)에는 아무른 규칙도 없다. (주의 : 어떤 배포판에는 초기화 스크깁트에 iptables를 실행하는 것이 들어있을 수 있다.) 입력과 출력 체인의 정책은 ACCEPT이고 포워딩 체인의 정책은 DROP이다. (iptable_filter 모듈에 'forward=1' 옵션을 선택하여 이것을 고칠 수 있다.)
이것은 패킷 필터링의 약방의 감초이다. 일반적으로 추가와 제거 명령을 사용할 것이다. 다른것은 이런 개념의 단순한 확장이다.
각 규칙은 패킷이 일치되어야할 상태를 설정하고, 일치되었을때 무었을 할 것인가 ('target')를 나타낸다. 예를들어, 여러분은 127.0.0.1로부터의 모든 ICMP 패킷을 DROP하려고 할 것이다. 그렇다면, 이경우 일치되어야할 상태는 'ICMP이면서 그 출처 가 127.0.0.1' 이다. 이 경우 'target' 은 DROP 이다.
127.0.0.1 은 'loopback' 인터페이서 이고 실제적인 네트워크 접속이 전혀 없더라도 이것은 가지고 있을 것이다. 이러한 패킷은 'ping' 프로그램을 이용하여 생성할 수 있다. (이것은 단순히 ICMP type 8 (반응요구)을 보내고 모든 협조적인 호스트는 친절하게 ICMP type 0 (반응요구에 대한 응답)을 대답한다. 이것은 테스트하는데 유용 하다.
# ping -c 1 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.2 ms
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.2/0.2/0.2 ms
# iptables -A INPUT -s 127.0.0.1 -p icmp -j DROP
# ping -c 1 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 0 packets received, 100% packet loss
#
여기서 첫번째 ping 이 성공한 결과를 볼 수 있다. ('-c 1'은 하나의 패킷만 보내도록 ping에게 말하는 것이다.)
그리고, '입력' 체인에 127.0.0.1에서 오는 패킷('-s 127.0.0.1')으로 ICMP 프로토콜인것 ('-p icmp')은 DROP ('-j DROP')하라는 규칙을 추가(-A)하였다.
그리고는 다시 ping으로 규칙을 테스트하였다. ping이 오지않은 응답을 기다 리지 못하고 응답받기를 포기하기까지 약간의 시간이 걸릴것이다.
규칙을 제거하는데는 두가지 방법이 있다. 첫째, 입력체인에는 단 하나의 규칙 만이 있다는 것을 앎으로, 몇번을 지워라는 방식으로 할 수 있다.
# iptables -D INPUT 1
#
입력 체인으로부터 1번 규칙을 제거한다.두번째 방법은 -A 명령을 이용한 이전의 명령에서 -A를 -D로 다꿔주면 된다. 이것은 복잡한 규칙을 가지고 있고 각 규칙이 몇번째 규칙인지를 외우고 다니기를 싫어 한다면, 아주 유용한 방법이다.
# iptables -D INPUT -s 127.0.0.1 -p icmp -j DROP
#
-D 명령은 -A 명령과 똑 같은 문법이다. (-I 나 -R 도 마찬가지이다.) 만약, 여러개의 똑 같은 규칙들이 같은 체인에 있다면, 첫번째 것만 제거 될 것이다.앞에서 프로토콜을 지정하기위하여 '-p'를 이용하였고, 출처를 지정하기 위하여 '-s'를 이용하였다. 그 외에도 패킷의 특징을 지정하는데 사용되 는 다른 옵션들이 있다. 아래는 이것들에 대한 완벽한 개요이다.
출처와 목적지 지정
출처('-s', '--source', '--src')와 목적지('-d', '--destination', '--dst') IP 주소를 지정하는데 4가지 방법이 있다. 가장 보편적인 방법은 'www.linuxhq.com', 'localhost' 처럼 이름을 이용하는 것이다. 두번째 방법은 '127.0.0.1' 처럼 IP 주소를 이용하는 것이다.
세번째와 네번째 방법은 IP 주소의 그룹을 지정하는 것으로 '199.95.207.0/24' 또는 '199.95.207.0/255.255.255.0' 같은 형태이다. 이 둘은 모두 199.95.207.0 부터 199.95.207.255 사이의 모든 IP 주소를 지정한다. '/' 다음의 숫자는 IP 주소의 어떤 부분이 의미있는가를 나타낸다. '/32' 나 '/255.255.255.255' 가 기본값이다.(IP 주소의 모든부분이 일치해야 한다.) 모든 IP 주소를 지정하는데 '/0' 가 사용된다.
# iptables -A INPUT -s 0/0 -j DROP
#
이것은 '-s' 옵션을 이용하지 않은것과 같은 효과를 나타내므로 잘 사용되지 않는다.
'역'의 경우 지정
많은 지시자들('-s'나 '-d' 같은)은 일치하지 않는 주소를 나타내기 위하여 '!'('not'을 의미한다)로 시작하는 설정을 할 수 있다. 예로, '-s ! localhost' 는 localhost로부터오는 패킷이 아닌경우를 나타낸다.
프로토콜 지정
프로토콜은 '-p' 지시자로 지정할 수 있다. 프로토콜을 숫자가 될수 있고 (IP의 프로토콜 번호를 알고 있다면) 'TCP', 'UDP', 'ICMP' 같은 이름이 될 수도 있다. 그리고 'tcp'는 'TCP'와 같은 역할을 한다.
프로토콜 이름 지정에도 '!'을 이용할 수 있다. '-p ! TCP'
인터페이서 지정
'-i'('--in-interface')와 '-o'('--out-interface')가 인터페이서를 저정 하는데 사용된다. 인터페이서는 패킷이 들어오고 나가는 물리적인 도구이다. ifconfig 명령을 사용하여 현재 활성화 되어있는 인터페이서를 알아볼수 있다.
입력 체인을 지나는 패킷은 출력 인터페이서를 가지고 있지 않으므로 '-o' 설정에 일치하는 패킷이 없을 것이고 출력 체인을 지나는 패킷은 입력 인터 페이서를 가지고 있지 않으므로 '-i' 설정에 일치하는 패킷이 없을 것이다.
포워딩 체인을 지나는 패킷만이 입력과 출력 인터페이서를 모두 가질것이다.
현재 존재하지 않는 인터페이서를 지정하는 것도 아무런 문제없이 될 수 있 다. 이것은 인터페이서가 활성화 되기 전까지는 규칙에 일치하는 패킷이 있을수 없을 것이다. 이것은 dial-up PPP를 사용하는 경우 특히 유용하다.
특별한 경우로, 인터페이서 이름이 '+'로 끝날수 있는데 이것은 그 이름으로 시작하는 모든 인터페이서를 모두 지정한다(그것이 현재 존재하든 존재하지 않든). 예를들어, 모든 PPP 인터페이서와 일치하는 규칙을 지정하려면 -i ppp+와같이 하면 된다.
인터페이서 이름앞에 '!'도 이용할 수 있다.
분절 (Fragments) 지정
가끔 패킷은 한번에 다 전달되기에는 너무 큰 경우가 있다. 이런경우 패킷은 여러 분절로 나뉘어지고 다중패킷의 형태로 전달된다. 목적지에서 이 분절들 은 재 구성되어 전체 패킷이 된다.
분절에서 문제점은 내부 패킷의 부분으로 IP 헤더 다음의 위치에서 프로토콜 헤더를 찾는데, 이것은 첫번째 분절에만 있기 때문에 찾을수가 없다.
만약 여러분이 접속추적이나 NAT를 한다면 모든 분절은 필터링 코드에 도달하 기 전에 뭉쳐지므로 분절에 대한 걱정은 할 필요가 없다.
그렇지 않다면, 분절들이 필터링 규칙에서 어떻게 처리되는가를 이해하는 것 은 중요하다. 우리가 가지고있지 않은 정보를 요구하는 필터링 규칙에 부합될 수가 없다. 이것은 첫번째 패킷은 다른 패킷과 같이 처리되고 두번째 이후의 분절은 전달될 수 없음을 의미한다. 그러므로 -p TCP --sport www ('www' 를 출신 포트로 지정하는 경우)와 같은 규칙에 맞는 분절은 있을 수 없다( 첫번째 분절을 제외하고). 그 반대의 규칙인 -p TCP --sport ! www도 분 절들을 처리할 수 없다.
그러나, 두번째 이상의 분절에 대하여 규칙을 지정하기위하여 '-f' ('--fragment')라는 지시자를 사용할 수 있다. 두번째 이상의 분절에는 적용 되지않는 규칙을 지정하기 위하여 '-f' 앞에 '!' 를 붙이는 것도 가능하다.
일반적으로 , 첫번째 분절에 필터링이 적용되어 DROP 되면 목적지 에서 다른 분절들의 재합성이 되지 않으므로, 두번째 이상의 분절이 그냥 지나가도록하는 것도 안전한 것으로 간주 된다. 그러나 단순히 분절들을 전달하는 것만으로 호스트를 크래쉬가 생기는 버그가 알려져 있다. 여러분이 결정할 일이다.
네트워크 헤더에 대한 주의 : 잘못 구성된 패킷들은 이러한 시험을 할때 DROP 되었다. (TCP, UDP, ICMP 패킷중 길이가 너무 짧아 파이어월 코드가 포트나 ICMP 코드와 형태를 읽을 수 없는 경우). 왜냐하면 TCP 분절은 8번째 위치부터 시작되기 때문이다.
예로, 다음과 같은 규칙은 192.168.1.1 로 향하는 분절을 DROP 시킨다.
# iptables -A OUTPUT -f -d 192.168.1.1 -j DROP
#
iptables 의 확장 : 새로운 대상(Matches)
iptables는 확장 가능하다. 즉 새로운 형태를 제공하기 위하여 iptables와 커널 모두가 확장 가능하다는 의미이다.
이중 일부는 표준적이고 다른 것은 이색적이다. 다른사람에 의해서도 확장 은 만들어질 수도 있으며 독립적으로 배포될 수 있다.
정상적으로 커널 확장은 커널 모듈 하부 디렉토리에 존재한다. (/lib/modules/2.3.15/net). 이것은 요구에 의하여 적재된다. 그러므로 직 접 이들 모듈을 적재할 필요는 없다.
iptables의 확장들은 공유라이버러리 형태로 보통 /usr/local/lib/iptables 에 위치한다. 배포판은 이것을 /lib/iptables나 /usr/lib/iptables에 넣으 려 할 것이다.
확장은 두가지 형태이다. : 새로운 타겟(target), 새로운 적용(match) 아래에 새로운 타겟에 대하여 이야기 할 것이다. 어떤 프로토콜은 자동으로 새로운 테스트를 제공하는데 현재로는 TCP, UDP, ICMP 에 대해서 아래에 보여 줄 것이다.
이것을 위해서 '-p' 옵션 뒤에 지정하는데 그러면 확장을 적제할 것이다. 명백히 할려면 '-m' 옵션으로 확장을 적재하고 확장 옵션을 사용가능하게 할 수 있다.
확장에 대한 도움을 얻으려면, 적제하는 옵션('-p', '-j', '-m')을 '-h'나 '--help' 다음에 지정하면 된다.
TCP 확장
TCP 확장은 '--protocol tcp' 가 지정되고 다른 적용이 지정되지 않으면 자동으로 적제된다. 이것은 다음과 같은 옵션을 제공한다.
- --tcp-flags
'!' 옵션을 사용한다면 이것 뒤에 두개의 단어를 사용한다. 첫번째 것은 검사하고자 하는 지시자 리스트의 마스크이다. 두번째 단어는 지시자에게 어떤것이 설정 될 것인지를 말해준다. 예를들어,
# iptables -A INPUT --protocol tcp --tcp-flags ALL SYN,ACK -j DENY
이것은 모든것이 검사되어야 함을 말한다.('ALL'은 `SYN,ACK,FIN,RST,URG,PSH' 와 같다.) 그러나 SYN 과 ACK 만 설정된다. 'NONE'는 지시자가 없음 을 말한다.
- --syn
'!' 옵션이 선행될 수 있다. 이것은 '--tcp-flags SYN,RST,ACK,SYN'의 약어이다.
- --source-port
'!' 옵션이 선행될 수 있다. 이후에 하나의 TCP 포트나 포트의 범위를 지정한다. /etc/services 에 기록된 것과 같은 포트 이름이 사용될 수 도 있고 숫자로 나타낼 수도 있다. 범위는 두개르 포트 이름을 '-' 으 로 연결해서 사용하거나 (커거나 같은경우를 위해서) 하나의 포트 뒤에 '-'를 사용하거나 (작거나 같은 경우를 위해서) 하나의 포트 앞에 '-' 를 덧붙일 수 있다.
- --sport
이것은 '--source-port'와 동의어이다.
- --destination-port
와
- --dport
는 위의 내용과 같으나 목적 지를 지정한다.
- --tcp-option
'!' 나 숫자가 옵션에 선행될 수 있는데 숫자가 앞에 올경우 그 숫자 와 TCP 옵션이 같은 경우의 패킷을 검사한다. TCP 옵션을 검사하려 할 때 완전한 TCP 헤더를 갖지않는 것은 자동으로 DROP 된다.
TCP 지시자에대한 설명
가끔 한쪽 방향에서의 TCP 접속만 허랑하고 다른 방향에서의 접속을 불허하 는 것이 유용하다. 예로, 여러분은 외부 WWW 서버로의 접속은 허락하며 그 서버로 부터의 접속은 불허하기를 원할 것이다.
단순하게 그 서버로부터 오는 TCP 패킷을 막으면 된다고 생각할 것이다. 그러 나, 불행히도 작동하기 위해서 TCP 접속은 양방향의 패킷을 요구한다.
해법은 접속을 요구하는 패킷만 막는 것이다. 이러한 패킷을 SYN 패킷이라한다. (물론, 기술적으로 SYN 지시자 셋을 갖는 패킷이 있다. 그리고 FIN 과 ACK 지시 자는 지워진다. 그러나 간단히 그것을 SYN 패킷이라고 한다.) 이러한 패킷만 불가능으로 만듬으로서 외부로 부터의 접속 시도를 막을 수 있다.
이러한 것을 위해서 '--syn' 지시자가 사용된다. : 이것은 프로토콜을 TCP 로 지정했을 때만 효과가 있다. 예를 들면, 192.168.1.1 로부터의 TCP 접속을 지 정하기 위하여 다음과 같이 하면 된다.
-p TCP -s 192.168.1.1 --syn
접속을 시작한 것 외의 모든 패킷을 지정하기 위하여 '!' 옵션이 선행될 수 있다.
UDP 확장
이 확장은 '--protocol udp'가 지정되고 적용이 저정되지 않으면 자동으로 적재된다. 이것은 '--source-port', '--sport', '--destination-port', '-dport'를 지원하고 내용은 TCP 설명에서 자세히 나왔다.
ICMP 확장
이 확장은 '--protocol icmp'가 지정되고 그 적용이 지정되지 않으면 자동으로 적재된다. 이것은 단 하나의 새로운 옵션만 지원한다.:
- --icmp-type
'!' 옵션이 선행될 수 있다. 이후에 ICMP 타입의 이름('host-unreachable') 이나 숫자형태 ('3'), 또는 숫자형태와 코드('/'로 분리 예. '3/3') 의 형 태가 사용된다. 사용할 수 있는 ICMP 형태의 이름의 리스트는 '-p icmp --help' 하면 나타난다.
그외의 적용 확장
Netfilter 패키지의 다른 확장은 시험적인 확장이다. 이것은 (설치 되어있다면) '-m' 옵션으로 활성화 된다.
- mac
이 모듈은 '-m mac' 또는 '--match mac' 이라고 함으로 지정할 수 있다. 이것은 들어오는 패킷의 이더넷 주소를 검사한다. 그러므로 입력 체인에 서만 유용하다. 이것은 하나의 옵션만 제공한다.
- --mac-source
'!' 옵션이 선행 될 수 있다. 이후에 콜론으로 분리된 16진수 숫자의 이더넷 주소가 온다. 예 '--mac-source 00:60:08:91:CC:B7'
- limit
이 모듈은 '-m limit' 또는 '--match limit'이라고 함으로 지정할 수 있 다. 이것은 로그 메세지를 억제할때 처럼 적용검사의 속도를 제한하는데 사용한다. 1초에 주어진 숫자만큼의 적용만 검사한다. (기본값은 한 시간 에 3번, 최고 5번이다.) 이것은 두개의 옵션을 제공한다.
- --limit
숫자가 따라온다 : 초당 평균 최대 적용 검사 수를 지정한다. 숫자뒤 에 시간단위를 지어할 수 도 있다. ('/second', '/minute', '/hour', '/day'형태이다. 예로, '5/second' 또는 '5/s'가 가능하다)
- --limit-burst
숫자가 따라온다. 위의 제한이 적용되기전의 최대 Burst(?) 를 제한 한다.
이 적용은 종종 로그의 속도를 제한하기위하여 LOG 타겟과 함께 사용된 다. 이것을 이해하기위하여 아래에 기본 제한설정을 하는 로그 패킷제한 을 보자.
# iptables -A FORWARD -m limit -j LOG
이 규칙에 도달될때까지 패킷은 로그될 것이다. 사실 Burst의 기본값은 5 이므로 처므ㅇ 5개의 패킷은 로그될것이다. 그 이후 얼마나 많은 패킷이 도달하든 간에 하나의 패킷이 로그되기전에 20분이 걸릴 것이다. 그리고 20분 동안 패킷 적용이 없으면 Burst 하나가 다시 생길 것이다. 패킷없이 100분 이 지나면 Burst는 완전이 원상 복구 될것이다. 처음 시작할때로 돌아가는 것 이다.
재복구 시간을 59시간 이상으로는 설정하지 못한다. 그러므로 평균속도를 하 루에 1개로 설정하였다면 Burst 속도는 3 이하가 되어야 한다.
- owner
이 모듈은 지역에서 생성된 패킷의 생성자의 여러 특징을 적용하려고 한다. 이것은 출력 체인에만 사용되며 어떤 패킷들(ICMP ping 응답같은)은 소유자 가 없으므로 적용되지 않는다.
- --uid-owner userid
유효한 사용자 id (숫자)의 프로세서가 생성한 패킷에 적용한다.
- --uid-owner groupid
유효한 그룹 id (숫자)의 프로세서가 생성한 패킷에 적용한다.
- --pid-owner processid
주어진 프로세서 id 의 프로세서가 생성한 패킷에 적용한다.
- --sid-owner processid
세션 그룹내의 프로세서가 생성한 패킷에 적용한다.
- unclean
이 시험적인 모듈은 정확히 '-m unclean' 또는 '--match unclean'으로 지정해 주어야 한다. 이것은 무작위의 여러 건전성 검사를 한다. 이것은 제대로 검사되지 않았고 안전성 도구로도 사용되지 못한다.(아마도 이것 은 무제를 더욱 힘들게 하고 버그 그 자체일 것이다.) 이것은 옵션이 없다.
상태 적용
가장 유용한 적용 기준은 'ip_conntrack' 모듈의 접속 추적 분석을 해석하는 'state' 확장이다. 이것을 강력히 추천한다.
'-m state'를 지정함으로 '--state' 옵션을 사용할 수 있는데 이후에 콤마로 분리되는 적용할 상태들의 리스트가 온다.('!' 지시자는 사용되어지지 않는 다.) 이 상태들은 ;
- NEW
새로운 접속을 만드는 패킷
- ESTABLISHED
존재하는 접속에 속하는 패킷 (즉, 응답 패킷을 가졌던 것)
- RELATED
기존의 접속의 부분은 아니지만 연관성을 가진 패킷으로 . ICMP 에러 나 (FTP 모듈이 삽입 되어있으면) ftp 데이터 접속을 형성하는 패킷.
- INVALID
어떤 이유로 확인할 수 없는 패킷: 알려진 접속과 부합하지 않는 ICMP 에러와 'out of memory' 등을 포함한다. 보통 이런 패킷은 DROP 된다.
이제 패킷에서 어떤 검사를 할 수 있는지를 알았다. 이제 우리의 검사에 일치 하는 패킷을 어떻게 할 것인지를 말하는 것을 알아야 한다. 이것을 규칙 타겟 이라고 한다.
두개의 이미 만들어진 단순한 타겟이 있다. : DROP 과 ACCEPT. 이미 이것에 대해서는 이야기를 한 적이 있다. 적용이 되는 패킷과 그것의 타겟이 위의 두 개중 하나라면 더이상의 참고할 규칙은 없다. : 패킷의 운명은 결정 되는 것 이다.
이미 만들어진 두개의 타겟외에 두가지 형태의 타겟이 있다.: 확장과 사용자 지정의 체인들 이다.
사용자 지정의 체인들
ipchains로 부터 상속되는 iptables의 강력한 기능중의 하나는 능력되는 사용 자가 기존의 세개의 체인(입력, 출력, 포워드)외에 새로운 체인을 생성할 수 있다는 것이다. 모임의 결과 사용자 지정의 체인은 그것을 구분하기 위하여 소문 자로 나타낸다. (아래 전체 체인에 대한 작용 부분에서 어떻게 사용자 지정의 새로운 체인을 만드는지 기술할 것이다.)
타겟이 사용자 지정의 체인인 규칙에 패킷이 맞으면 패킷은 사용자 지정의 체인을 따라 움직이게 된다. 그 체인이 패킷의 운명을 결정하지 못하면 그리고 그 체인에 따른 이송이 끝나면, 패킷은 현제 체인의 다음 규칙으로 돌아온다.
그림을 보자. 두개의 체인이 있고 그것이 입력과 테스트라는 사용자 지정의 체인이 라고 가정하자.
`INPUT' `test'
---------------------------- ----------------------------
| Rule1: -p ICMP -j DROP | | Rule1: -s 192.168.1.1 |
|--------------------------| |--------------------------|
| Rule2: -p TCP -j test | | Rule2: -d 192.168.1.1 |
|--------------------------| ----------------------------
| Rule3: -p UDP -j DROP |
----------------------------
192.168.1.1 로부터 와서 1.2.3.4 로 향하는 TCP 패킷이 있다고 가정한다. 이것은 입력 체인으로 들어온다. Rule1 을 검사한다. 맞지 않음. Rule2 맞음. 그것의 타겟 은 테스트, 고로 다음 검사할 규칙은 테스트의 시작이다. 테스트의 Rule1 이 맞다. 그러나 이것이 타겟을 지정하지 않는다. 그러므로 다음 규칙이 검사된다. Rule 2. 맞지 않다. 그 체인의 끝에 도달했다. 다시 입력 체인으로 돌아가서 Rule3 을 검사 한다. 그것도 맞지 않다.
여기서 패킷의 이동경로를 그림으로 나타냈다.
v __________________________
`INPUT' | / `test' v
------------------------|--/ -----------------------|----
| Rule1 | /| | Rule1 | |
|-----------------------|/-| |----------------------|---|
| Rule2 / | | Rule2 | |
|--------------------------| -----------------------v----
| Rule3 /--+___________________________/
------------------------|---
v
사용자 지정의 체인에서 대를 사용자 지정의 체인으로 갈수 있다. (그러나 루프 를 돌수는 없다. 루프를 발견하게 되면 패킷은 DROP 된다.)
iptables로의 확장 : 새로운 타겟
타겟의 다른 형태는 확장이다. 타겟 확장은 커널 모듈로 구성된다. 그리고 iptables 에 대한 선택적 확장은 새로운 명령행의 옵션을 제공한다. 기본적으로 넷필터 배포에 포함된 몇몇의 확장은 다음과 같다.
- LOG
일치하는 패킷의 커널 로그를 제공한다. 이것은 부가의 옵션을 제공한다.
- --log-level
레벨 숫자나 이름이 따라온다. 유효한 이름은 (상황에 따라 다르다) 'debug' 'info', 'notice', 'warning', 'err', 'crit', 'alert', 'emerg' 이고 이것 은 각각 숫자 7 에서 0 에 대응한다. 이런 레벨에 대한 설명은 syslog.conf 의 man 페이지를 보라.
- --log-prefix
14자 까지의 문장이 따라온다. 이 메세지는 로그 메세지의 시작부분으로 보내져서 확인에 사용될 수 있다.
이 모듈은 'limit' 타겟 다음에 사용하면 가장 효과적이다. 그래서 로그가 넘 지나지 않도록 할 수 있다.
- REJECT
이 모듈은 'DROP'과 같은 효과를 나타낸다. 다만, 'port unreachable' 이라는 에러 메세지를 ICMP 로 보낸다. 주의할 것은 ICMP 에러 메세지는 다음의 경우 보내 지지 않는다 ( RFC 1122 를 보라) :
- 검사된 패킷이 ICMP 에러메세지이거나나 알수 없는 ICMP 형태인 경우
- 검사된 패킷이 헤더가 없는 분절인 경우
- 너무 많은 ICMP 에러 메세지를 그 목적지로 보낸 경우.
REJECT 는 '--reject-with'라는 옵션을 가지는데 이것은 사용할 응답 패킷을 변경한다. 자세한 것은 메뉴얼 페이지를 보라.
특별한 미리 만들어진 타겟
두개의 미리 만들어진 타겟이 있다 : RETURN, QUEUE
RETURN은 한 체인의 끝으로 보내지는 것과 같은 효과가 있다. : 미리 만들어진 체 인의 경우 그 체인의 정책은 실행이다. 사용자 정의 체인의 경우 이 체인으로 점프 하는 규칙의 바로 다음인 이전 체인으로 이동한다.
QUEUE은 특별한 타겟으로, 사용자공간의 작업을 위해 패킷을 대기하도록 한다. 패킷 을 위해서 대기하고있는 것이 없다면(즉, 이 패킷을 다룰 프로그램이 아직 씌어져 있지 않다면) 패킷은 DROP 될 것이다.
iptables의 유용한 기능주 하나는 여러 관계가 있는 규칙을 하나의 체인속으로 그룹화 하는 것이다. 체인의 이름은 어떤 것을 사용할 수도 있으나 미리 만들어 진 체인과의 혼동을 막기 위하여 소문자를 사용하기를 권한다. 체인의 이름은 16 자 까지 가능하다.
새오룬 체인 생성
새로운 체인을 만들어 보자. 나는 매우 상상력이 좋은 사람이므로 이것을 테스트 라고 부르기로 하겠다. '-N' 또는 '--new-chain' 옵션을 사용한다.
# iptables -N test
#
단순하다. 이제 이 체인에 상세한 규칙을 적용할 수 있다.
체인 제거
체인을 제거하는 것도 단순하ㄷ. '-X' 나 '--delete-chain' 을 사용한다.
# iptables -X test
#
체인을 제거 하는데는 몇가지 제한이 있다. 이것은 비어있어야 한다. (아래의 체인 비우기를 보라) 그리고 그것은 다른 어떤 규칙의 타겟도 아니어야 한다. 미리 만들어진 세개의 체인은 제거할 수 없다.
체인의 이름을 지정하지 않으면 모든 사용자 정의의 체인은 제거된다.
체인 비우기
하나의 체인의 모든 규칙을 비우는 간단한 방법이 있으니, '-F' ('--flush') 명령이다.
# iptables -F forward
#
체인을 지정하지 않으면 모든 체인의 규칙이 지워진다.
체인 규칙 나열하기
한 체인의 모든 규칙은 '-L' 명령으로 나열할 수 있다.
각 사용자 정의의 체인을 나열했던 'refcnt' 는 그 체인을 그들의 타겟으로하 는 규칙들의 번호이다. 체인이 제거되기 위해서는 이것이 '0' 으로 되어야 한다. (그리고 그 체인은 비어야 한다)
체인의 이름이 생략되면 비어있는 것을 포함한 모든 체인이 나열된다.
'-L' 명령에 따르는 옵션은 세개가 있다. '-n' (numeric) 옵션은 iptables가 여러분이 DNS 요구를 필터링 아웃한 경우나 DNS가 적절이 설정되어 있지 않다면 오랜 시간이 걸리는, IP 주소를 찾는 것을 예방하는 아주 유용한 옵션이다. 이것 은 TCP와 UDP 포트가 이름이 아닌 숫자로 출력되도록 하기도 한다.
'-v' 옵션은 규칙의 자세한 정보(패킷과 바이트 카운터, TOS 비교, 인터페이서와 같은)를 나타낸다.
패킷과 바이트 카운트는 'K'(1000), 'M'(1,000,000), 'G'(1,000,000,000) 와 같은 접미어와 함께 나타난다. '-x' (확장 수) 지시자를 사용하면 얼마나 큰 숫자든 전 체 숫자가 나타난다.
카운트 리셋트 ('0'으로 만들기)
이것은 카운트를 리셋하는데 유용하다. 이것은 '-Z' ('--zero') 옵션으로 가능하다.
이것의 문제점은 리셋하기 직전의 카운트 값을 알필요가 있을 때가 가끔 있다는 것 이다. 이러한 경우의 예로, 어떤 패킷이 '-L' 과 '-Z' 명령 사이에 지나갈 수 있다. 이런이유로 카운트를 읽는 것과 동시에 리셋하기위해서 '-L' 과 '-Z' 명령을 같이 사용할 수 있다.
정책 설정
우리가 이전 체인을 패킷이 어떻게 지나가는가를 의논할 때, 미리 만들어진 체인의 끝에 패킷이 다다렀을때 무슨 일이 일어날 것인가를 설명하였다. 이 경우 체인의 정책이 그 패킷의 운명을 결정한다. 미리 만들어진 체인(입력, 출력, 포워드)만이 정책을 가지는데, 이것은 사용자 정의의 체인의 끝에 다다른 패킷의 이동은 이전 체인에서 요약되어지기 때문이다.
정책은 ACCEPT 또는 DROP 이 될수 있다.
ipchains와 ipfwadm을 사용하기
배포되는 넷필터에는 ipchains.o 와 ipfwadm.o 라는 모듈이 있다. 이것을 여러 분의 커널에 포함시키면 이전과 똑 같이 ipchains 나 ipfwadm을 사용할 수 있 다. ( 주의 : 이들은 iptables.o, ip_conntrack.o, ip_nat.o와 호환성이 없다)
이것은 아직 한동안은 지원될 것이다. 이들을 완전히 대치하는 안정판이 나오 는데 까지는 2 * [대치할 것이라는 발표 - 첫번째 안정판] 이라는 공식이 적 용된다고 생각한다.
즉, ipfwadm의 경위 이것의 지원이 종료될 때는 :
2 * [October 1997 (2.1.102 release) - March 1995 (ipfwadm 1.0)]
+ January 1999 (2.2.0 release)
= November 2003.
그리고 ipchains의 경우 이것의 지원이 종료될 때는 :
2 * [August 1999 (2.3.15 release) - October 1997 (2.2.0 release)]
+ January 2000 (2.3.0 release?)
= September 2003.
그러므로, 2004년 까지는 걱정할 필요가 없을 것이다.
- 첫째로, 미리 만들어진 체인의 이름들이 소문자에서 대문자로 바뀌었는데 이것은 입력과 출력 체인은 이게 지역 넷으로 향하는 그리고 지역에서 생성된 패킷만을 적용하기 때문이다. 이것은 모든 들어오는것과 나가는 패킷을 다룬다.
- '-i' 지시자는 들어오는 인터페이스만 의미하고 입력 과 포워드 체인 에서만 작동한다. 포워드 나 출력 체인에 사용되었던 '-i' 는 '-o'로 바꿔야 한다.
- 이제 TCP 와 UDP 포트는 --source-port 또는 --spotr (또는 --destination-port / --dport) 옵션과 함께 사용되어져야 할 필요가 있고 '-p tcp' 또는 '-p udp' 옵션과 함께 사용되어져야 한다. 그러면 이것은 TCP 또는 UDP 확장을 각각 적재 할 것이다. (ipt_tcp 와 ipt_udp 모듈을 수동으로 적제 하기위해서 포함 시킬 수도 있다.)
- TCP -y 지시자는 --syn으로 바뀌었고 `-p tcp'다음에 와야 한다.
- DENY target 는 DROP 으로 바뀌었다.
- Zeroing single chains while listing them works.
- 만들어진 체인을 '0'으로하면 정책 카운터도 지워진다.
- 체인을 나열하는 것은 카운트의 스넵샷을 제공한다.
- REJECT 와 LOG 는 확장된 target이다. 즉, 이것들은 독립된 커널 모듈이다는 의미이다.
- 체인 이름은 16자 까지 가능하다.
- MASQ 와 REDIRECT 는 더이상 target 이 아니다. iptables은 패킷을 변화 시키지 않는다. 이것을 위해서 NAT라는 하부구조가 있다. 이것은 ipnatctl 하우두를 읽어보아라.
- 그 외의 것들은 잊어먹었다.
출처 - http://wiki.kldp.org/wiki.php/LinuxdocSgml/Packet_Filtering-TRANS#ss7.3
1) 방화벽 기본 정책
iptables 방화벽의 시작은 기본 정책을 수립하는 것이다. iptables를 이용하여 방화벽을 구성할 경우 두 가지 정책 중 한가지를 선택하면 된다. 일반적으로 모든 패킷에 대해서 무시하는 것이 방화벽의 기본 정책이다.
방화벽의 기본 정책 |
* 모든 것을 허용한 후 제한할 것을 거부한다. * 모든 것을 거부한 후 필요한 것만 허용한다. |
두 개중 일반적으로 모든 것을 막아버리는 것을 기본 정책으로 한다.
대부분의 리눅스 배포판은 모든 것을 거부하는 것을 기본 정책으로 채택하고 있으나, 페도라코어 리눅스의 경우는 모든 것을 허용하는 정책을 기본으로 하고 있다. 그러면 기본 정책으로 모든 것에 대해서 거부하는 정책을 택하여 다음과 같이 실행하여 기본 보안 정책을 수립한다.
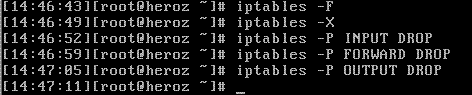
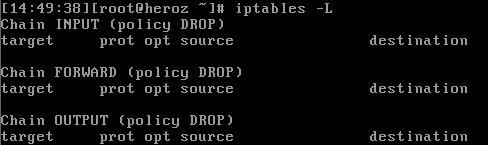
iptables -L 명령으로 iptables의 테이블 상태를 점검할 수 있다. iptables -L 명령을 실행해 보면 INPUT과 FORWARD, OUTPUT 체인의 정책 모두 DROP으로 설정되 있음을 확인할 수 있다.
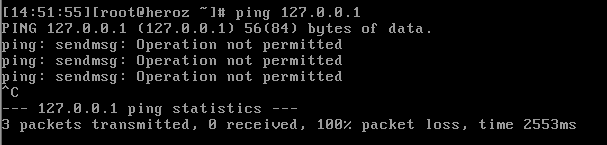
이것은 리눅스 서버로 어떠한 패킷이든 들어오고 나갈 수 없는 상태임을 의미하여, 로컬이든 외부에서 로컬 컴퓨터로는 네트워크가 차단된 것처럼 연결할 수 없게 된다. 그러면 ping 127.0.0.1 명령으로 루프백에 핑을 테스트해 봅시다. 루프백으로 핑이 나가질 않음을 알수 있다.
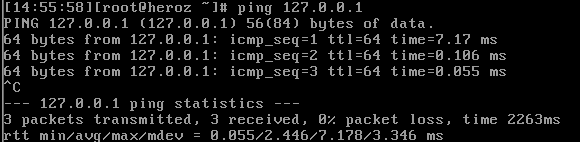
루프백으로 모든 패킷이 자유롭게 들어오고 나갈 수 있도록 다음과 같이 명령을 실행해 보자.

루프백 주소로 핑을 날리면 핑이 나감을 확인 할 수 있다. 핑 뿐만 아니라 로컬에서 제공하는 모든 네트워크 서비스에 접근할 수 있게 된다.
▶ iptables 사용법
iptables [-t table] command [match] [target\jump]
-A(--append) : 규칙을 추가한다.
-N(--new-chain) : 새로운 체인 생성
-X(--delete-chain) : 체인 제거
-P(--policy) : 체인 기본정책 변경
-L(--list) : 체인의 규칙상태 보기
-F(--flush) : 체인내의 모든 규칙 제거(방화벽 초기화)
-Z(--zero) : 체인내의 모든 규칙의 패킷과 바이트의 카운트를 0으로 초기화
-D(--delete) : 규칙을 삭제
-R(--replace) : 새로운 규칙으로 대체
-I(--insert) : 체인의 가장 처음에 규칙을 추가한다.
-E(--rename-chain) : 체인의 이름을 변경한다.
2) iptables 체인 종류
INPUT : 로컬로 들어오는 패킷(입력 패킷)
FORWARD : INPUT와 OUTPUT 역할, 라우터에 방화벽을 적용할 때 쓰임
OUTPUT : 외부로 나가는 패킷(출력 패킷)
INPUT 체인에 사용자 정의로 체인을 추가하여 INPUT 체인 대신에 사용할 수 있는데, 페도라 코어의 경우는 RH-Firewall-1-INPUT라는 사용자 정의 체인을 사용한다. 3개의 기본 체인(INPUT, OUTPUT, FORWARD)은 수정이나 삭제가 불가능하며, 사용자 정의 체인은 다음과 같은 방법으로 생성해 줄 수 있다.
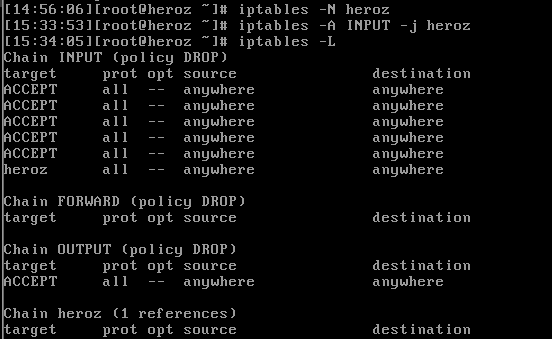
3) iptables 다루기
▶ 방화벽 정책 초기화
| # iptables -F # iptables -X # iptables -Z |
▶ 기본 정책 설정
| # iptables -P INPUT DROP # iptables -P OUTPUT DROP # iptables -P FORWARD DROP |
▶ 사용자 정의 체인 생성 및 INPUT 체인에 추가
# iptables -N 사용자정의체인명 # iptables -A INPUT -j 사용자정의체인명 |
▶ 허용 정책 설정
루프백 접속 허용
다른 곳과 네트워크가 연결되어 있지 않더라도 시스템의 기본 네트워크이며 로컬 호스트의 인터페이스인 루프백에 대해서는 접속이 이뤄질 수 있도록 해야 하므로, 다음과 같이 설정한다.
iptables -A INPUT -i lo -j ACCEPT iptables -A OUTPUT -o lo -j ACCEPT |
내부 네트워크 접속
iptables -A FORWARD -s 192.168.0.0/24 -d 192.168.0.0/24 -j ACCEPT iptables -A OUTPUT -s 192.168.0.0/24 -d 192.168.0.0/24 -j ACCEPT |
내부 -> 외부 접속
iptables -A FORWARD -s 외부주소 -p tcp -m tcp --sport 포트번호 -j ACCEPT iptables -A OUTPUT -d 외부주소 -p tcp -m tcp --dport 포트 -j ACCEPT |
① DNS 포트 허용
iptables -A FORWARD -p udp -m udp --sport 53 -j ACCEPT iptables -A OUTPUT -p udp -m udp --dport 53 -j ACCEPT |
② ICMP 핑 허용
iptables -A OUTPUT -o eth0 -p icmp --icmp-type echo-request -j ACCEPT iptables -A FORWARD -i eth0 -p icmp --icmp-type echo-reply -j ACCEPT iptables -A OUTPUT -o eth0 -p icmp --icmp-type echo-reply -j ACCEPT |
③ SSH 포트 허용 ( 192.168.0.1 -> 172.16.1.20)
iptables -A fedora -s 172.16.1.20 -p tcp -m tcp --sport 22 -j ACCEPT iptables -A OUTPUT -d 172.16.1.20 -p tcp -m tcp --dport 22 -j ACCEPT |
④ HTTP 포트 허용
iptables -A FORWARD -i eth0 -p tcp -m tcp --sport 80 --dport 1024:65535 -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m tcp --sport 1024:65535 --dport 80 -j ACCEPT |
⑤ FTP 포트 허용
* 명령(제어) 포트(tcp 21) 접속
iptables -A FORWARD -i eth0 -p tcp -m tcp --sport 21 --dport 1024:65535 -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m tcp --sport 1024:65535 --dport 21 -j ACCEPT |
*데이터 포트(tcp20) 접속(능동 모드 접속)
iptables -A FORWARD -i eth0 -p tcp -m tcp --sport 21 --dport 1024:65535 -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m tcp --sport 1024:65535 --dport 21 -j ACCEPT |
*데이터 포트(tcp 1024이상의 포트) (Passive 모드 접속)
iptables -A FORWARD -i eth0 -p tcp -m tcp --sport 1024:65535 --dport 1024:65535 -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m tcp --sport 1024:65535 --dport 1024:65535 -j ACCEPT |
외부 -> 내부 접속
① SSH 포트 허용
iptables -A FORWARD -i eth0 -p tcp -m tcp --dport 22 -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m tcp --sport 22 -j ACCEPT |
② http 포트 허용
iptables -A FORWARD -i eth0 -p tcp -m tcp --dport 80 -j ACCEPT iptables -A OUTPUT -o eth0 0p tcp -m tcp --sport 80 -j ACCEPT |
③ ftp 포트 허용 ( passive mode)
iptables -A FORWARD -i eth0 -p tcp -m tcp --dport 21 -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m tcp --sport 21 -j ACCEPT iptables -A FORWARD -i eth0 -p tcp -m tcp --dport 1024:65535 -j ACCEPT iptables -A OUTPUT -o eth0 -p tcp -m tcp --sport 1024:65535 -j ACCEPT |
출처 - http://blog.naver.com/bestheroz?Redirect=Log&logNo=67705029
명령어순례
iptables 명령은 리눅스 IPv4 방화벽을 설정하는 명령어이다. 1.1 시리즈 부터 리눅스 커널은 패킷 필터링을 포함하기 시작했다. 제 1세대는 BSD의 ipfw를 기본으로 했고 1994년 후반기에 알란 콕스(Alan Cox) 에 의해서 포트 됐다.
이것은 리눅스 2.0에서 Jos Vos와 다른이들에 의해서 개선됐고 커널의 필터링 규칙을 제어하는 사용자 툴로는 'ipfwadm'이 사용됐다.
1998년 중반에 리눅스 2.2를 위해 사용자 툴로 'ipchains'를 내놓았다. 마지막으로, 제 4세대 툴이 'iptables'이고 리눅스 2.4를 위해 1999년 중반에 커널을 재작성했다.
<리눅스매거진 편집부>
패킷 필터란? 네트워크를 통하는 모든 것은 패킷의 형태를 가지며, 패킷의 앞부분에는 패킷이 어디서 왔는지 어디로 향하는지, 어떤 프로토콜을 이용하는지 등과 같은 정보를 가지고 있다. 패킷 필터는 이렇게 지나가는 패킷의 헤더를 보고 패킷을 ‘DROP'(마치 전혀 전달되지 않는 것처럼 패킷을 거부) 하거나 ’ACCEPT‘(패킷이 지나가도록 내버려 둠)하는 등의 작업을 하는 프로그램을 말한다. iptables은 이런 패킷 필터링 기능을 설정하는데 사용할 수 있는 프로그램이다. 자신의 시스템에 설치돼 있는 iptables의 버전을 확인하는 방법은 아래명령을 통해 가능하다.
# iptables --version
iptables 1.2.4
커널은 3가지의 방화벽 체인(chain)을 기본적으로 가지고 패킷 필터링을 시작한다. 파이어월 체인 혹은 체인이라 부르는 이 3가지는 입력(Input), 출력(Output), 전달(Forward)이다. 입력체인은 들어오는 패킷을 조사하고 전달체인은 외부의 다른 시스템으로 전달될 패킷을 조사한다. 마지막으로 출력체인은 외부로 나가는 패킷을 조사한다.
■ 패킷검사방법
1. 패킷이 커널에 도착하면 그 패킷의 목적지를 확인한다. 이것을 '라우팅' 이라고 한다.
2. 패킷의 목적지가 이곳이면, 패킷은 전달돼 입력체인에 도달한다. 패킷이 입력체인을 통과하면 패킷을 기다리고 있던 프로세서가 받게 된다.
3. 그렇지 않고 커널이 포워딩 불능이나, 패킷을 어떻게 포워딩해야 하는가를 알지못하면, 그 패킷은 ‘DROP‘ 된다. 포워딩이 가능하게 돼있고 다른 곳이 목적지이면 패킷은 그림의 오른쪽 방향으로 전달돼 포워딩 체인으로 간다. 이 체인이 ’ ACCEPT‘ 하게 되면 이것은 포워딩 할 네트워크로 보내진다.
4. 마지막으로, 로컬에서 수행하던 프로그램은 네트워크 패킷을 전송할 수 있다.
이 패킷은 즉시 출력 체인에 보내지며 이 체인이 ‘ACCEPT’되면 이 패킷은 그 목적지가 어디든지 보내진다.
:::: 사 용 법 ::::
iptables -[ADC] chain rule-specification [options]
iptables -[RI] chain rulenum rule-specification [options]
iptables -D chain rulenum [options]
iptables -[LFZ] [chain] [options]
iptables -[NX] chain
iptables -P chain target [options]
iptables -h (print help information)
# Commands
-A : 새로운 규칙을 추가한다.(--append)
-D : 규칙을 삭제한다.(--delete)
-C : 패킷을 테스트한다.(--check)
-R : 새로운 규칙으로 교체한다.(--replace)
-I : 새로운 규칙을 삽입한다.(--insert)
-L : chain에 설정된 규칙을 출력한다.(--list)
-F : chain으로부터 규칙을 모두 방출(삭제)한다.(--flush)
-Z : 모든 chain의 패킷과 바이트 카운터 값을 0으로 만든다.(--zero)
-N : 새로운 chain을 만든다.(--new)
-X : chain을 삭제한다.(--delete-chain)
-P : 기본정책을 변경한다.(--policy)
# chain
INPUT : 입력에 대한 사용
OUTPUT : 출력에 대한 사용
FORWARD : 전달(forwarding)에 대한 사용
# Options
-s : 패킷의 발신지를 명시한다.(--source)
-p : 패킷의 프로토콜을 명시한다.(--protocol)
-d : 패킷의 도착지를 명시한다.(--destination)
-i : 규칙을 적용할 인터페이스 이름을 명시한다.(--interface)
-j : 규칙에 맛는 패킷을 어떻게 처리할 것인가를 명시한다.(-jump)
-y : 접속 요청 패킷인 SYN패킷을 허용하지 않는다.(--syn)
-f : 두 번째 이후의 조각에 대해서 규칙을 명시한다.(--fragment)
# 사용예
127.0.0.1 IP 주소로부터 오는 모든 ICMP 패킷을 무시하는 경우 사용되는 프로토콜은 ICMP이고 발신 주소는 127.0.0.1 이어야 한다. 그리고 패킷 필터의 목표는 드롭(DROP)이다. 테스트하는 프로그램은 ping이며 ping은 단순히 ICMP type 8로 반응요구를 보내며 이에 협조하는 대상 호스트는 ICMP 타입 0 (echo reply)를 보내어 응답하도록 돼 있다. 이제 iptables의 패킷필터를 통해 로컬호스트가 ping 명령에 반응하지 않도록 하겠다.
# ping -c 1 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.2 ms
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.2/0.2/0.2 ms
# iptables -A INPUT -s 127.0.0.1 -p icmp -j DROP
; `INPUT' 체인에 127.0.0.1로부터 오고(`-s 127.0.0.1') ICMP(`-p
ICMP') 패킷에 대해 DROP로 점프하라는 (`-j DROP') 규칙을 추가(-A).
# ping -c 1 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 0 packets received, 100% packet loss
■ 설정된 iptables 규칙의 삭제
지금 현재 입력돼 있는 chain이 하나밖에 없으므로 숫자를 지정하는 명령으로 삭제가 가능하며, 앞의 명령과 똑같이 하되 -A를 -D로 바꾸어 지우는 방법이 있다.
#iptables -D INPUT 1
#iptables -D INPUT -s 127.0.0.1 -p icmp -j DROP
■ 체인 규칙 나열하기
설정돼 있는 체인의 규칙을 모두 볼 수 있다. 명령으로 -L을 사용해 가능하며 -v 옵
션과 같이 사용해 각 체인에 대한 패킷과 바이트 카운터 등의 자세한 정보를 함께
볼 수 있다.
# iptables -A INPUT -s 127.0.0.1 -p icmp -j DROP
# iptables -L -v
Chain INPUT (policy ACCEPT 709 packets, 35362 bytes)
pkts bytes target prot opt in out source
destination
0 0 DROP icmp -- any any localhost.localdomain
anywhere
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source
destination
Chain OUTPUT (policy ACCEPT 423 packets, 39549 bytes)
pkts bytes target prot opt in out source
destination
■ 체인 비우기
하나의 체인 안의 모든 규칙을 비우는 것은 ‘-F’ 명령을 사용해 간단하게 할 수
있다. 체인을 지정하지 않으면 모든 체인의 규칙을 지울 수 있다.
# iptables -F INPUT
■ 출처와 목적지 지정
출처('-s', '--source', '--src')와 목적지('-d', '--destination', '--dst') IP 주소를 지정하는데 4가지 방법이 있다. 가장 보편적인 방법은 'www.linuzine.com', 'localhost'처럼 도메인 네임을 이용하는 것이다. 두번째 방법은 '127.0.0.1'과 같은 IP 주소를 이용하는 것이다.
세번째와 네번째 방법은 IP 주소의 그룹을 지정하는 것으로 '199.95.207.0/24' 또는 '199.95.207.0/255.255.255.0' 같은 형태이다. 이 둘은 모두 199.95.207.0
부터 199.95.207.255 사이의 모든 IP 주소를 지정한다. '/' 다음의 숫자는 IP 주
소의 어떤 부분이 의미 있는가를 나타낸다. '/32' 나 '/255.255.255.255' 가 기
본 값이다.(IP 주소의 모든 부분이 일치해야 한다.) 모든 IP 주소를 지정하는
데 '/0' 가 사용된다.
# iptables -A INPUT -s 0/0 -j DROP
많은 지시자들('-s'나 '-d' 같은)은 일치하지 않는 주소를 나타내기 위해 '!'('not'을 의미한다)로 시작하는 설정을 할 수 있다. 예로, '-s ! localhost' 는 localhost로부터 오는 패킷이 아닌 경우를 나타낸다.
■ 프로토콜 지정
프로토콜은 '-p' 지시자로 지정할 수 있다. 프로토콜을 숫자가 될 수 있고(IP의 프로토콜 번호를 알고 있다면) 'TCP', 'UDP', 'ICMP' 같은 이름이 될 수도 있다.
그리고 'tcp'는 'TCP'와 같은 역할을 한다. 프로토콜 이름 지정에도 '!'을 이용
할 수 있다. '-p ! TCP'
■ TCP 확장
TCP 확장은 '--protocol tcp' 가 지정되고 다른 적용이 지정되지 않으면 자동으로 적재된다. 이것은 다음과 같은 옵션을 제공한다.
--tcp-flags
뒤에 두개의 단어를 사용한다. 첫번째 것은 검사하고자 하는 지시자 리스트의 마스크이다. 두번째 단어는 지시자에게 어떤 것이 설정 될 것인지를 말해준다.
# iptables -A INPUT --protocol tcp --tcp-flags ALL SYN,ACK -j DROP
이것은 모든것이 검사돼야 함을 말한다. 그러나 SYN과 ACK만 설정된다.
--syn
'!' 옵션이 선행될 수 있다. 이것은 '--tcp-flags SYN,RST,ACK,SYN'의 약어이다.
--source-port,
'!' 옵션이 선행될 수 있다. 이후에 하나의 TCP 포트나 포트의 범위를 지정한다.
--sport
/etc/services 에 기록된 것과 같은 포트 이름이 사용될 수 도 있고 숫자로 나타낼 수도 있다. 범위는 두 개의 포트 이름을 '-'으로 연결해서 사용하거나 하나의 포트 뒤에 '-'를 사용하거나 하나의 포트 앞에 '-' 를 덧붙일 수 있다.
--destination-port, --dport
위의 내용과 같으나 목적지를 지정한다.
--tcp-option
'!' 나 숫자가 옵션에 선행될 수 있는데 숫자가 앞에 올 경우 그 숫자 와 TCP 옵션이 같은 경우의 패킷을 검사한다. TCP 옵션을 검사하려 할 때 완전한 TCP 헤더를 갖지 않는 것은 자동으로 드롭 된다.
■ iptables를 통한 포트관리
iptables는 테이블 형식으로 관리를 한다. 그리고 먼저 등록된 것이 효력을 발생하기 때문에 등록을 하는 순서가 중요하다. 모든 것을 거부하는 설정이 먼저 오게 되면 그 이후에 포트를 열어주는 설정이 와도 효과가 없다. 그러므로 허용하는 정책이 먼저 오고 나서 거부하는 정책이 와야 한다.
iptables -A INPUT -p tcp --dport 25 -j ACCEPT
iptables -A INPUT -p tcp --dport 22:30 -j DROP
이렇게 하면 먼저 25번 포트로 들어오는 것을 허용하고 난 후에 다른 것을 막아내기 때문에 제대로 된 설정이 된다.
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
등록된 라인은 ssh를 사용하는 것을 허용하는 것이다. 출처(source)와 목적지 (destination)는 명시하지 않았기 때문에 전체포트와 IP가 대상이 된다. -dport 는 패킷이 대상으로 삼는 포트를 명시한 것이다 여기에서 22라고 표기한 것은 ssh서비스 포트이다. 그리고 마지막에 -j ACCEPT는 허용하도록 정책을 정하는 것이다.
따라서 여기로의 ssh서비스를 요청하는 패킷은 허용되도록 설정을 한 것이다.
■ 전체적인 설정
#!/bin/sh
# iptables 모듈 등록하기
modprobe iptable_filter
# ssh 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 22 -j ACCEPT
# httpd 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 80 -j ACCEPT
# pop3 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 109 -j ACCEPT
# pop2 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 110 -j ACCEPT
# imap 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 143 -j ACCEPT
# mysqld 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
# ftpd 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 21 -j ACCEPT
# ftp-data 열기
/usr/local/bin/iptables -A INPUT -p tcp --dport 20 -j ACCEPT
# ircd 열어주기
/usr/local/bin/iptables -A INPUT -p tcp --dport 6667 -j ACCEPT
/usr/local/bin/iptables -A INPUT -p udp --dport 6667 -j ACCEPT
# 전부 거절하기
/usr/local/bin/iptables -A INPUT -p tcp --dport 1:30000 -j DROP
/usr/local/bin/iptables -A INPUT -p icmp --icmp-type echo-request -j
DROP
이처럼 허용하는 서비스가 한정적이다. 우선 ssh, http, pop3, pop2, imap,
mysql, ftp, ircd를 위해서 서비스를 요청하는 패킷은 허용하고 나머지는 전부 거부하는 설정이다. 이 설정을 자세히 보면 tcp와 icmp를 대상으로 했다. 거절하는 줄인
/usr/local/bin/iptables -A INPUT -p tcp --dport 1:30000 -j DROP
이 라인에서 --dport 다음에 1:30000 으로 지정돼 있다. 이 부분은 서버를 경유해서 다른 곳으로 가고자하는 경우에 클라이언트 프로그램이 사용할 포트를 남겨주기 위함이다. 1번포트에서 30000번 포트까지는 완전히 tcp에 대해서 막는 것이다.
만약에 서버에서 나갈 이유가 없으면 전부 막으면 된다. 1:65535 로 설정하면 전체포트가 막힌다. iptables 설정은 조금만 공부를 하면 쉽게 습득이 가능하다. 그러므로 문서를 보는 것이 중요하다. 이 설정은 기본이므로 좀더 많은 것은 관련 문서를 이용하기를 바란다.
출처 - http://achess.egloos.com/728112
kldp를 돌아다니다 보니 어떤분이
iptables -A INPUT -p tcp --dport 22 -s xxx.xxx.xxx -m state --state NEW,ESTABLISHED -j ACCEPT
이런 식으로 iptables를 구성했다고 하는데 state가 무엇인지 알고 싶습니다. 그리고 괜찮으시다면 NEW와 ESTABLISHED가 무엇인지도 알려주세요.
말 그대로 tcp/udp/icmp 등의 전송 프로토콜의 연결 "상태"를 가지고 맞춰보기를 하는 겁니다.
NEW는 세션을 만들 때의 첫 번째 패킷, ESTABLISHED는 이미 세션이 연결된 후에 오가는 패킷, INVALID는 대략 정체를 알 수 없는(열리지 않는 세션에 대한 데이터 전송 패킷 등) 패킷, RELATED는 기존의 연결 세션을 바탕으로 새로 만들어지는 세션의 패킷입니다.
인용하신 규칙은 대략 "들어오는 SSH 패킷 중 별 이상없는 패킷들을 받아들이셈"으로 해석 가능합니다.
리눅스 2.4 패킷 필터링 하우투 7.3절의 끝부분에 각 상태에 대한 간단한 설명이 있습니다. 혹은 "iptables state"로 구글링 하면 나오는 첫 번째 문서인 Iptables Tutorial 1.1.19 - Firewall의 관련 내용을 참고하실 수도 있습니다.
출처 - http://kldp.org/node/64875
IPTables
1. Introduction
CentOS has an extremely powerful firewall built in, commonly referred to as iptables, but more accurately is iptables/netfilter. Iptables is the userspace module, the bit that you, the user, interact with at the command line to enter firewall rules into predefined tables. Netfilter is a kernel module, built into the kernel, that actually does the filtering. There are many GUI front ends for iptables that allow users to add or define rules based on a point and click user interface, but these often lack the flexibility of using the command line interface and limit the users understanding of what's really happening. We're going to learn the command line interface of iptables.
Before we can really get to grips with iptables, we need to have at least a basic understanding of the way it works. Iptables uses the concept of IP addresses, protocols (tcp, udp, icmp) and ports. We don't need to be experts in these to get started (as we can look up any of the information we need), but it helps to have a general understanding.
Iptables places rules into predefined chains (INPUT, OUTPUT and FORWARD) that are checked against any network traffic (IP packets) relevant to those chains and a decision is made about what to do with each packet based upon the outcome of those rules, i.e. accepting or dropping the packet. These actions are referred to as targets, of which the two most common predefined targets are DROP to drop a packet or ACCEPT to accept a packet.
Chains
These are 3 predefined chains in the filter table to which we can add rules for processing IP packets passing through those chains. These chains are:
- INPUT - All packets destined for the host computer.
- OUTPUT - All packets originating from the host computer.
- FORWARD - All packets neither destined for nor originating from the host computer, but passing through (routed by) the host computer. This chain is used if you are using your computer as a router.
For the most part, we are going to be dealing with the INPUT chain to filter packets entering our machine - that is, keeping the bad guys out.
Rules are added in a list to each chain. A packet is checked against each rule in turn, starting at the top, and if it matches that rule, then an action is taken such as accepting (ACCEPT) or dropping (DROP) the packet. Once a rule has been matched and an action taken, then the packet is processed according to the outcome of that rule and isn't processed by further rules in the chain. If a packet passes down through all the rules in the chain and reaches the bottom without being matched against any rule, then the default action for that chain is taken. This is referred to as the default policy and may be set to either ACCEPT or DROP the packet.
The concept of default policies within chains raises two fundamental possibilities that we must first consider before we decide how we are going to organize our firewall.
1. We can set a default policy to DROP all packets and then add rules to specifically allow (ACCEPT) packets that may be from trusted IP addresses, or for certain ports on which we have services running such as bittorrent, FTP server, Web Server, Samba file server etc.
or alternatively,
2. We can set a default policy to ACCEPT all packets and then add rules to specifically block (DROP) packets that may be from specific nuisance IP addresses or ranges, or for certain ports on which we have private services or no services running.
Generally, option 1 above is used for the INPUT chain where we want to control what is allowed to access our machine and option 2 would be used for the OUTPUT chain where we generally trust the traffic that is leaving (originating from) our machine.
2. Getting Started
Working with iptables from the command line requires root privileges, so you will need to become root for most things we will be doing.

| IMPORTANT: We will be turning off iptables and resetting your firewall rules, so if you are reliant on your Linux firewall as your primary line of defense you should be aware of this. |
Iptables should be installed by default on all CentOS 5.x and 6.x installations. You can check to see if iptables is installed on your system by:
$ rpm -q iptables
iptables-1.4.7-5.1.el6_2.x86_64
And to see if iptables is actually running, we can check that the iptables modules are loaded and use the -L switch to inspect the currently loaded rules:
# lsmod | grep ip_tables
ip_tables 29288 1 iptable_filter
x_tables 29192 6 ip6t_REJECT,ip6_tables,ipt_REJECT,xt_state,xt_tcpudp,ip_tables
# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
Chain FORWARD (policy ACCEPT)
target prot opt source destination
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Above we see the default set of rules on a CentOS 6 system. Note that SSH service is permitted by default.
If iptables is not running, you can enable it by running:
# system-config-securitylevel
3. Writing a Simple Rule Set
| IMPORTANT: At this point we are going to clear the default rule set. If you are connecting remotely to a server via SSH for this tutorial then there is a very real possibility that you could lock yourself out of your machine. You must set the default input policy to accept before flushing the current rules, and then add a rule at the start to explicitly allow yourself access to prevent against locking yourself out. |
We will use an example based approach to examine the various iptables commands. In this first example, we will create a very simple set of rules to set up a Stateful Packet Inspection (SPI) firewall that will allow all outgoing connections but block all unwanted incoming connections:
# iptables -P INPUT ACCEPT
# iptables -F
# iptables -A INPUT -i lo -j ACCEPT
# iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
# iptables -A INPUT -p tcp --dport 22 -j ACCEPT
# iptables -P INPUT DROP
# iptables -P FORWARD DROP
# iptables -P OUTPUT ACCEPT
# iptables -L -v
which should give the following output:
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- lo any anywhere anywhere
0 0 ACCEPT all -- any any anywhere anywhere state RELATED,ESTABLISHED
0 0 ACCEPT tcp -- any any anywhere anywhere tcp dpt:ssh
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destinationNow lets look at each of the 8 commands above in turn and understand exactly what we've just done:
iptables -P INPUT ACCEPT If connecting remotely we must first temporarily set the default policy on the INPUT chain to ACCEPT otherwise once we flush the current rules we will be locked out of our server.
iptables -F We used the -F switch to flush all existing rules so we start with a clean state from which to add new rules.
iptables -A INPUT -i lo -j ACCEPT Now it's time to start adding some rules. We use the -A switch to append (or add) a rule to a specific chain, the INPUT chain in this instance. Then we use the -i switch (for interface) to specify packets matching or destined for the lo (localhost, 127.0.0.1) interface and finally -j (jump) to the target action for packets matching the rule - in this case ACCEPT. So this rule will allow all incoming packets destined for the localhost interface to be accepted. This is generally required as many software applications expect to be able to communicate with the localhost adaptor.
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT This is the rule that does most of the work, and again we are adding (-A) it to the INPUT chain. Here we're using the -m switch to load a module (state). The state module is able to examine the state of a packet and determine if it is NEW, ESTABLISHED or RELATED. NEW refers to incoming packets that are new incoming connections that weren't initiated by the host system. ESTABLISHED and RELATED refers to incoming packets that are part of an already established connection or related to and already established connection.
iptables -A INPUT -p tcp --dport 22 -j ACCEPT Here we add a rule allowing SSH connections over tcp port 22. This is to prevent accidental lockouts when working on remote systems over an SSH connection. We will explain this rule in more detail later.
iptables -P INPUT DROP The -P switch sets the default policy on the specified chain. So now we can set the default policy on the INPUT chain to DROP. This means that if an incoming packet does not match one of the following rules it will be dropped. If we were connecting remotely via SSH and had not added the rule above, we would have just locked ourself out of the system at this point.
iptables -P FORWARD DROP Similarly, here we've set the default policy on the FORWARD chain to DROP as we're not using our computer as a router so there should not be any packets passing through our computer.
iptables -P OUTPUT ACCEPT and finally, we've set the default policy on the OUTPUT chain to ACCEPT as we want to allow all outgoing traffic (as we trust our users).
iptables -L -v Finally, we can list (-L) the rules we've just added to check they've been loaded correctly.
Finally, the last thing we need to do is save our rules so that next time we reboot our computer our rules are automatically reloaded:
# /sbin/service iptables save
This executes the iptables init script, which runs /sbin/iptables-save and writes the current iptables configuration to /etc/sysconfig/iptables. Upon reboot, the iptables init script reapplies the rules saved in /etc/sysconfig/iptables by using the /sbin/iptables-restore command.
Obviously typing all these commands at the shell can become tedious, so by far the easiest way to work with iptables is to create a simple script to do it all for you. The above commands may be entered into your favourite text editor and saved as myfirewall, for example:
#!/bin/bash
#
# iptables example configuration script
#
# Flush all current rules from iptables
#
iptables -F
#
# Allow SSH connections on tcp port 22
# This is essential when working on remote servers via SSH to prevent locking yourself out of the system
#
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
#
# Set default policies for INPUT, FORWARD and OUTPUT chains
#
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT ACCEPT
#
# Set access for localhost
#
iptables -A INPUT -i lo -j ACCEPT
#
# Accept packets belonging to established and related connections
#
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
#
# Save settings
#
/sbin/service iptables save
#
# List rules
#
iptables -L -v
Note: We can also comment our script to remind us what were doing.
now make the script executable:
# chmod +x myfirewall
We can now simply edit our script and run it from the shell with the following command:
# ./myfirewall
4. Interfaces
In our previous example, we saw how we could accept all packets incoming on a particular interface, in this case the localhost interface:
iptables -A INPUT -i lo -j ACCEPT
Suppose we have 2 separate interfaces, eth0 which is our internal LAN connection and ppp0 dialup modem (or maybe eth1 for a nic) which is our external internet connection. We may want to allow all incoming packets on our internal LAN but still filter incoming packets on our external internet connection. We could do this as follows:
iptables -A INPUT -i lo -j ACCEPT
iptables -A INPUT -i eth0 -j ACCEPT
But be very careful - if we were to allow all packets for our external internet interface (for example, ppp0 dialup modem):
iptables -A INPUT -i ppp0 -j ACCEPT
we would have effectively just disabled our firewall!
5. IP Addresses
Opening up a whole interface to incoming packets may not be restrictive enough and you may want more control as to what to allow and what to reject. Lets suppose we have a small network of computers that use the 192.168.0.x private subnet. We can open up our firewall to incoming packets from a single trusted IP address (for example, 192.168.0.4):
# Accept packets from trusted IP addresses
iptables -A INPUT -s 192.168.0.4 -j ACCEPT # change the IP address as appropriate
Breaking this command down, we first append (-A) a rule to the INPUT chain for the source (-s) IP address 192.168.0.4 to ACCEPT all packets (also note how we can use the # symbol to add comments inline to document our script with anything after the # being ignored and treated as a comment).
Obviously if we want to allow incoming packets from a range of IP addresses, we could simply add a rule for each trusted IP address and that would work fine. But if we have a lot of them, it may be easier to add a range of IP addresses in one go. To do this, we can use a netmask or standard slash notation to specify a range of IP address. For example, if we wanted to open our firewall to all incoming packets from the complete 192.168.0.x (where x=1 to 254) range, we could use either of the following methods:
# Accept packets from trusted IP addresses
iptables -A INPUT -s 192.168.0.0/24 -j ACCEPT # using standard slash notation
iptables -A INPUT -s 192.168.0.0/255.255.255.0 -j ACCEPT # using a subnet mask
Finally, as well as filtering against a single IP address, we can also match against the MAC address for the given device. To do this, we need to load a module (the mac module) that allows filtering against mac addresses. Earlier we saw another example of using modules to extend the functionality of iptables when we used the state module to match for ESTABLISHED and RELATED packets. Here we use the mac module to check the mac address of the source of the packet in addition to it's IP address:
# Accept packets from trusted IP addresses
iptables -A INPUT -s 192.168.0.4 -m mac --mac-source 00:50:8D:FD:E6:32 -j ACCEPT
First we use -m mac to load the mac module and then we use --mac-source to specify the mac address of the source IP address (192.168.0.4). You will need to find out the mac address of each ethernet device you wish to filter against. Running ifconfig (or iwconfig for wireless devices) as root will provide you with the mac address.
This may be useful for preventing spoofing of the source IP address as it will allow any packets that genuinely originate from 192.168.0.4 (having the mac address 00:50:8D:FD:E6:32) but will block any packets that are spoofed to have come from that address. Note, mac address filtering won't work across the internet but it certainly works fine on a LAN.
6. Ports and Protocols
Above we have seen how we can add rules to our firewall to filter against packets matching a particular interface or a source IP address. This allows full access through our firewall to certain trusted sources (host PCs). Now we'll look at how we can filter against protocols and ports to further refine what incoming packets we allow and what we block.
Before we can begin, we need to know what protocol and port number a given service uses. For a simple example, lets look at bittorrent. Bittorrent uses the tcp protocol on port 6881, so we would need to allow all tcp packets on destination port (the port on which they arrive at our machine) 6881:
# Accept tcp packets on destination port 6881 (bittorrent)
iptables -A INPUT -p tcp --dport 6881 -j ACCEPT
Here we append (-A) a rule to the INPUT chain for packets matching the tcp protocol (-p tcp) and entering our machine on destination port 6881 (--dport 6881).
Note: In order to use matches such as destination or source ports (--dport or --sport), you must first specify the protocol (tcp, udp, icmp, all).
We can also extend the above to include a port range, for example, allowing all tcp packets on the range 6881 to 6890:
# Accept tcp packets on destination ports 6881-6890
iptables -A INPUT -p tcp --dport 6881:6890 -j ACCEPT
7. Putting It All Together
Now we've seen the basics, we can start combining these rules.
A popular UNIX/Linux service is the secure shell (SSH) service allowing remote logins. By default SSH uses port 22 and again uses the tcp protocol. So if we want to allow remote logins, we would need to allow tcp connections on port 22:
# Accept tcp packets on destination port 22 (SSH)
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
This will open up port 22 (SSH) to all incoming tcp connections which poses a potential security threat as hackers could try brute force cracking on accounts with weak passwords. However, if we know the IP addresses of trusted remote machines that will be used to log on using SSH, we can limit access to only these source IP addresses. For example, if we just wanted to open up SSH access on our private lan (192.168.0.x), we can limit access to just this source IP address range:
# Accept tcp packets on destination port 22 (SSH) from private LAN
iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 22 -j ACCEPT
Using source IP filtering allows us to securely open up SSH access on port 22 to only trusted IP addresses. For example, we could use this method to allow remote logins between work and home machines. To all other IP addresses, the port (and service) would appear closed as if the service were disabled so hackers using port scanning methods are likely to pass us by.
8. Summary
We've barely scratched the surface of what can be achieved with iptables, but hopefully this HOWTO has provided a good grounding in the basics from which one may build more complicated rule sets.
9. Links
http://www.centos.org/docs/5/html/Deployment_Guide-en-US/ch-fw.html
http://www.centos.org/docs/5/html/Deployment_Guide-en-US/ch-iptables.html
출처 - http://wiki.centos.org/HowTos/Network/IPTables
How to edit iptables rules
In this how-to, we will illustrate three ways to edit iptables Rules :
- CLI : iptables command line interface and system configuration file /etc/sysconfig/iptables.
- TUI (text-based) interface : setup or system-config-firewall-tui
- GUI : system-config-firewall
NOTE: This how-to illustrates editing existing iptables Rules, not the initial creation of Rules chains.
CLI (command line interface)
Hot changes to iptables Rules
The following procedures allow changes in the behaviour of the firewall while it is running.
Caution
You can break the network connection to the Fedora system with mistakes in Rules.
Read the man pages for iptables (man iptables) for further explanations and more sophisticated Rules examples.
Superuser rights required
You must have superuser rights to execute these commands, please use sudo or su to obtain superuser rights.
Listing Rules
Current running iptables Rules can be viewed with the command
iptables -L
.
Numeric port valueThe list of Rules with the -L command option shows ports by their service name rather than port number. To see the port number instead, include the -n argument.iptables -L -n
Viewing countersRules listed with the -L command option do not include matching counters. To include matching counters, include -v argument.iptables -L -v
Example of iptables Rules allowing any connections already established or related, icmp requests, all local traffic, and ssh communication:
[root@server ~]# iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Note that Rules are applied in order of appearance, and the inspection ends immediately when there is a match. Therefore, for example, if a Rule rejecting ssh connections is created, and afterward another Rule is specified allowing ssh, the Rule to reject is applied and the later Rule to accept the ssh connection is not.
Appending Rules
The following adds a Rule at the end of the specified chain of iptables:
[root@server ~]# iptables -A INPUT -p tcp --dport 80 -j ACCEPT
[root@server ~]# iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
ACCEPT tcp -- anywhere anywhere tcp dpt:http
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Notice the last line in chain INPUT. There are now five Rules in that chain.
Deleting Rules
To delete a Rule, you must know its position in the chain. The following example deletes an existing Rule created earlier that is currently in the fifth position:
[root@server ~]# iptables -D INPUT 5
[root@server ~]# iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Inserting Rules
Create a Rule at the top (first) position:
[root@server ~]# iptables -I INPUT 1 -p tcp --dport 80 -j ACCEPT
[root@server ~]# iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- anywhere anywhere tcp dpt:http
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
The number given after the chain name indicates the position before an existing Rule. So, for example, if you want to insert a Rule before the third rule you specify the number 3. Afterward, the existing Rule will then be in the fourth position in the chain.
Replacing Rules
Rules may be specified to replace existing Rules in the chain.
In the example shown previously, the first Rule given allows connections to the http port (port 80) from anywhere. The following replaces this Rule, restricting connections to the standard http port (port 80) only from the network address range 192.168.0.0/24:
[root@server ~]# iptables -R INPUT 1 -p tcp -s 192.168.0.0/24 --dport 80 -j ACCEPT
[root@server ~]# iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 192.168.0.0/24 anywhere tcp dpt:http
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Flushing Rules
To flush or clear iptables Rules, use the --flush, -F option :
iptables -F <chain>
Specifying a <chain> is optional; without a chain specification, all chains are flushed.
Example to flush Rules in the OUTPUT chain :
[root@server ~]# iptables -F OUTPUT
Default chain policys care
Be aware of the default chain policy. For example, if the INPUT policy is DROP or REJECT and the Rules are flushed, all incoming traffic will be dropped or rejected and network communication broken.
Making changes persistent
The iptables Rules changes using CLI commands will be lost upon system reboot. However, iptables comes with two useful utilities: iptables-save and iptables-restore.
- iptables-save prints a dump of current iptables rules to stdout. These may be redirected to a file:
[root@server ~]# iptables-save > iptables.dump
[root@server ~]# cat iptables.dump
# Generated by iptables-save v1.4.12 on Wed Dec 7 20:10:49 2011
*filter
:INPUT DROP [45:2307]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [1571:4260654]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
COMMIT
# Completed on Wed Dec 7 20:10:49 2011
- iptables-restore : restore a dump of rules made by iptables-save.
[root@server ~]# iptables-restore < iptables.dump
[root@server ~]# iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Upon stopping the service, the current iptables Rules are saved in a file, and upon starting the service, this file is restored. The affected files are:
/etc/sysconfig/iptables
for IPv4/etc/sysconfig/ip6tables
for IPv6
If preferred, these files may be editted directly, and iptables service restarted to commit the changes. The format is similar to that of the iptables CLI commands:
# Generated by iptables-save v1.4.12 on Wed Dec 7 20:22:39 2011
*filter <--------------------------------------------------------- Specify the table of the next rules
:INPUT DROP [157:36334] <----------------------------------------- This is the three chain belong to filter table, then the policy of the chain
:FORWARD ACCEPT [0:0] <------------------------------------------- and between brackets [<packet-counter>:<byte-counter>] numbers is for
:OUTPUT ACCEPT [48876:76493439] <--------------------------------- debug/informations purpose only. Leave them at their current value.
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT <--------- A rule.
-A INPUT -p icmp -j ACCEPT <-------------------------------------- You just have to take all arguments
-A INPUT -i lo -j ACCEPT <---------------------------------------- of an iptables command.
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
COMMIT <---------------------------------------------------------- Needed at each end of table definition. Commit rules in that table.
# Completed on Wed Dec 7 20:22:39 2011
If needed, to reset packet and byte counters, use -Z, --zero :
iptables -Z <chain> <rule_number>
It is possible to reset only reset a single rule counter. It can be useful, if you want to know how many packets were captured for a specific rule.
source - https://fedoraproject.org/wiki/How_to_edit_iptables_rules












