* 8859_1 로 한글 파일명 처리
String filename = new String(file.getFilename().getBytes(), "8859_1");
response.setHeader("Content-Disposition", "attachment;filename=" + filename);
인코딩 - 8859_1의 비밀(?)
[출처] 인코딩 - 8859_1의 비밀(?)|작성자 우가가
Open source로 구해지는 java source code를 들여다 보면
하고 많은 문자셋들 중에 유독 '8859_1'을 많이 보게 된다.
'아니 저런 특정 문자셋을, 그것도 8비트밖에 지원하지 않는 문자셋을 코드에다 박아 버리면
쓰는 사람들은 어쩌란 거지?'
이런 생각이 들 때가 있을 것이다.
한때 나도 그랬었고..
그러나 정말 잘못 쓴 경우도 있겠지만, 많은 경우 '8859_1'의 사용은 나름 합리성을 띄고 있다.
이를 이해하려면 '8859_1'이 다른 문자셋들과 어떻게 다른가를 알아야 한다.
이전 글에서 언급했 듯이, '8859_1'은 1바이트에 해당하는 256개의 코드에 대해, 즉 0x00 ~ 0xff 까지의 모든 코드에 대해 대응되는 문자를 갖고 있다.
반면 8859_1보다 많은 문자를 거느리고 있는 'EUC-KR',
이것의 확장형인 'MS949' 나 심지어 모든 글자를 다 포함한다고 여겨도 될 만한 'UTF-8' 조차
가진 문자는 확실히 많지만 모든 바이트 열에 대해 대응되는 문자를 갖고 있는 것은 아니다.
이를 확인하기 위해 다음을 실행해 보자.
public static void main(String[] args) throws Exception {for (int i = 0; i < 256; i++) {for (int j = 0; j < 256; j++) {byte[] bytes = new byte[] {(byte) i, (byte)j };String str = new String(bytes, "MS949");if (str.charAt(0) == 0xfffd) {System.out.println("for byte sequence{0x" + hex(i) + ", 0x" + hex(j)+ "} no character exists... getBytes()[0]=" + str.getBytes("MS949")[0]);} else if (str.length() > 1) {// 첫 바이트를 하나의 글자로 인식. i만 취하고 j 루프는 중지.System.out.println("For character{" + hex(i) + "} char = "+ str.charAt(0));break;} else {System.out.println("for character{" + hex(i) + ", " + hex(j)+ "} char = " + str);}}}}/** byte 출력용.*/public static String hex(int i ){String hex = Integer.toHexString(i);return (hex.length() > 2) ? hex.substring(hex.length() - 2) : hex;}
주루룩 많은 행을 출력하지만 보면 대응되지 않는 글자가 존재함을 알 수 있다.
대략 그림으로 나타내면 다음과 같다.
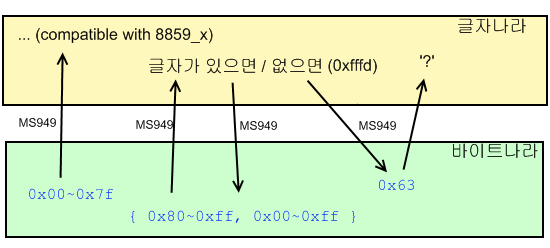
인식하는 바이트 값이 0x~0x7f 일 경우에는 8859_x 에서 사용되는 글자를 그대로 쓰며 이 때는 한 바이트가 하나의 글자와 매핑된다.
바이트 값이 0x81 이상일 경우에는 그 다음 바이트가 필요하며, 두 바이트를 가지고 하나의 글자를 구성한다. 그리고 이 때 '없는 글자'가 생긴다.
당장 {0x81, 0x00} ~ {0x81, 0x40} 에 해당하는 값에 대해 대응되는 글자가 없다.
없는 글자는 java char로 0xfffd (아마도 UTF-16BE로 {0xff 0xfd} 에 매핑되는 글자) 로 저장되었다가, 다시 MS949로 인코드하면 0x63 글자로 매핑된다. 이 글자가 물음표 '?' 이다
모르는 글자를 인코드 할 때 0x63 코드를 매핑하는 것은 Sun JDK에서의 대응 방식이다.
모르는 글자에 대한 대응에는 표준이 없는지 다른 vendor - 이를테면 IBM - 의 JDK에서는 좀 다르게 구현하는 것 같다.
(한편 바이트 값이 0x80이나 0xff 같을 때 이를 디코드하면 그 한 바이트가 '모르는 글자 0xfffd'로 매핑된다. 일반화할 수 있는 규칙은 아닌 것 같다..)
다음과 같이 인코드 - 디코드를 많이 거치게 되면 인코드 할 때도, 디코드 할 때도 매핑이 불가한 경우를 만나게 되어 글자들이 깨진다. 이 때의 깨진 글자들은 복구가 절대 안 된다.
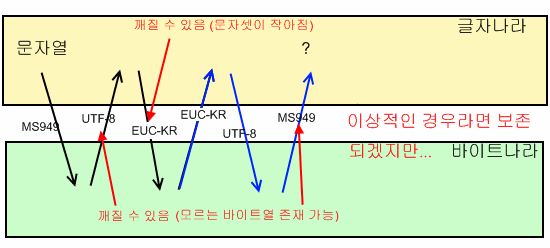
그래서 저런 식으로 부주의하게 인코드-디코드를 해 버리면 원래 호환되는 0x00~0x7f 이외의 한글 같은 글자들은 여지없이 깨져 버리고.. 되돌릴 수도 없게 된다.
그러나 8859_x 는 모든 바이트 코드에 대한 글자들을 구비하고 있으므로, 이해가 안 되는 이상한 글자로 매핑할 망정 코드를 보존하면서 디코드가 가능하다.
그래서 디코드만 하고, 이를 다시 인코드 할 경우에는 글자 깨짐이 발생하지 않는다.
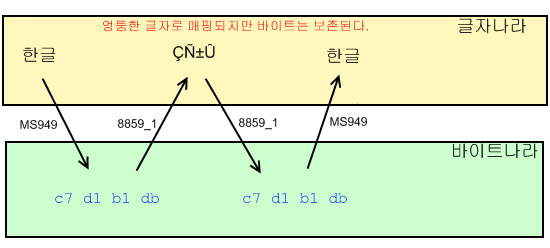
8859_1 뿐만 아니라 8859_2 도 "보관"할 때 가지는 문자가 틀리지만 역시 깨짐 없이 바이트를 보존할 수 있다.
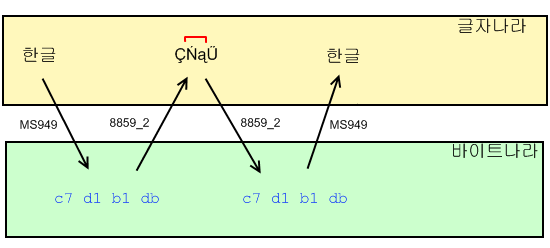
물론 그렇게 "보관"한 문자나 인코드가 원활히 되지, 아무 문자열이나 인코드를 하려 한다면
'자기 문자셋에 존재하지 않는 문자를 인코드'하는 경우가 발생해 글자가 깨질 것이다.
이를테면 아래와 같은 경우 당연히 문자셋에 없는 글자를 인코드하려 하므로 글자가 깨진다.
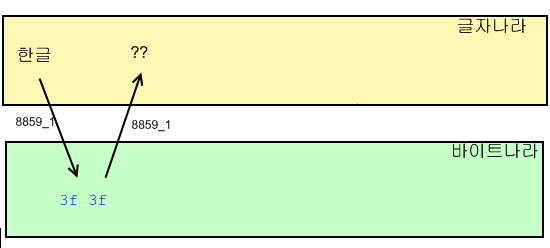
이렇게 되면 '원래 문자열이 2글자였다' 정도 외엔 아무 정보도 남지 않게 된다. (JDK vendor에 따라서는 이마저도 알 수 없게 될 것이다)
-----------------------------
실제 네트워크를 오가는 데이터는 바이트열의 형태이지만
이를 프로그래밍 언어에서 다룰 때는 문자열로 간주하고 작업할 때가 많다.
그게 편하기 때문이기도 하고,
문자열로서 의미를 가지는 경우가 많기 때문이기도 할 것이다.
가장 많이 쓰이는 경우가 웹 어플리케이션에서의 파일 다운로드, 아마도 그 다음이 소켓통신 (헤더를 읽어들이거나 생성할 때) 같은 경우일 것이다.
<< 다운로드 시 설정>>response.addHeader("Content-disposition", "attachment;filename=" + ... + "" );
이 때 인코딩/디코딩 작업이 필요한데, 디코드 시 바이트들을 깨뜨리지 않고 문자열로 얻고 싶다면 '8859_x'을 쓰는 것이 현명한 방책이라 하겠다.
물론 그 중에서도 많은 서버들이 위의 filename 을 ISO-Latin1(혹은 Latin1, 8859_1) 로 인코딩 해 보내기 때문에 같은 Latin 계열이라도 '8859_1' 즉 'Latin1'을 택하는 것이 좋다.
이는 표준이라고 하는데 문서 확인은 안 해 봤다. (어디 있는지 찾기 정말 힘들던데..)
[출처] 인코딩 - 8859_1의 비밀(?)|작성자 우가가
출처 - http://blog.naver.com/PostView.nhn?blogId=anabaral&logNo=130043451093
'Development > JSP & Servlet' 카테고리의 다른 글
| servlet - 3.0 비동기 기능 (0) | 2013.07.27 |
|---|---|
| servlet - 필터(filter) (0) | 2013.07.27 |
| jsp - 스마트폰 인식(모바일 기기 os 검출) (0) | 2013.06.01 |
| jsp - response.sendRedirect와 request.getRequestDispatcher (0) | 2012.12.24 |
| jsp - 접속 URL 출력 (0) | 2012.12.06 |





