| 개발자 | 엔비디아 |
|---|---|
| 최근 버전 | 5.0 / 2012년 10월 15일 |
| 운영 체제 | 윈도 XP 이상 맥 OS X 리눅스 |
| 플랫폼 | 아래의 지원 GPU 참고 |
| 종류 | GPGPU |
| 라이선스 | 프리웨어 |
| 웹사이트 | www.nvidia.com/object/cuda_home_new.html |
CUDA ("Compute Unified Device Architecture", 쿠다)는 그래픽 처리 장치(GPU)에서 수행하는 (병렬 처리) 알고리즘을 C 프로그래밍 언어를 비롯한 산업 표준 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술이다. CUDA는 엔비디아가 개발해오고 있으며 이 아키텍처를 사용하려면 엔비디아 GPU와 특별한 스트림 처리 드라이버가 필요하다. CUDA는 G8X GPU로 구성된 지포스 8 시리즈급 이상에서 동작한다. CUDA는 CUDA GPU 안의 명령셋과 대용량 병렬 처리 메모리를 접근할 수 있도록 해 준다.
개발자는 패스스케일 오픈64 C 컴파일러로 컴파일 된 '쿠다를 위한 C' (C언어를 엔비디아가 확장한 것) 를 사용하여 GPU 상에서 실행시킬 알고리듬을 작성할 수 있다. 쿠다 구조는 일련의 계산 인터페이스를 지원하며 이에는 OpenCL, DirectX Compute가 포함된다. C 언어가 아닌 다른 프로그래밍언어에서의 개발을 위한 래퍼(Wrapper)도 있는데, 현재 파이썬, 포트란, 자바와 매트랩 등을 위한 것들이 있다.
최신 드라이버는 모두 필요한 쿠다 콤포넌트를 담고 있다. 쿠다는 모든 엔비디아 GPU (G8X 시리즈 이후) 를 지원하며 이 대상에는 지포스,쿼드로, 테슬라 제품군이 포함된다. 엔비디아는 지포스 8 시리즈를 위해 개발된 프로그램들은 수정 없이 모든 미래의 엔비디아 비디오 카드에서 실행될 것이라고 선언하였다.
쿠다를 통해 개발자들은 쿠다 GPU 안 병렬 계산 요소 고유의 명령어 집합과 메모리에 접근할 수 있다. 쿠다를 사용하여 최신 엔비디아 GPU를 효과적으로 개방적으로 사용할 수 있다. 그러나 CPU와는 달리 GPU는 병렬 다수 코어 구조를 가지고 있고, 각 코어는 수천 스레드를 동시에 실행시킬 수 있다. 응용 프로그램이 수행하는 작업(계산)이 이러한 병렬처리연산에 적합할 경우, GPU를 이용함으로써 커다란 성능 향상을 기대할 수 있다.
컴퓨터 게임 업계에서는 그래픽 랜더링에 덧붙여, 그래픽 카드를 게임 물리 계산 (파편, 연기, 불, 유체 등 물리 효과)에 사용되며, 예로는 피직스와 불렛이 있다. 쿠다는 그래픽이 아닌 응용 프로그램, 즉, 계산 생물학, 암호학, 그리고 다른 분야에서 10배 또는 그 이상의 속도 혜택을 가져왔다. 이 한 예는 BOINC 분산 계산 클라이언트 이다.
쿠다는 저수준 API와 고수준 API 모두를 제공한다. 최초의 CUDA SDK는 2007년 2월 15일에 공개되었으며 마이크로소프트 윈도와 리눅스를 지원했다. 맥 OS X지원은 2.0 버전에 추가되었다.
목차[숨기기] |
[편집]이점
쿠다가 그래픽 API를 사용하는 전통적인 범용 GPU에 비해 가지는 몇가지 장점은 다음과 같다.
- 흩뿌린 읽기 - 코드가 메모리의 임의 위치에서 데이터를 읽을 수 있다.
- 공유 메모리 - 쿠다는 고속 공유 메모리 지역 (16 또는 48KB 크기) 을 드러내어 스레드 간에 나눌 수 있게 해 준다. 이는 사용자 관리 캐시로 사용될 수 있는데, 텍스처 룩업을 이용하는 경우 보다 더 빠른 대역폭이 가능해진다.
- 디바이스 상의 읽기, 쓰기가 호스트보다 더 빠르다.
- 정수와 비트 단위 연산을 충분히 지원한다. 정수 텍스처 룩업이 포함된다.
[편집]제한
- 재귀호출, 함수 포인터가 없는 C 언어의 하부 집합을 확장하여 사용한다. 그러나 한개의 처리 장치가 여러개의 쪼개진 메모리 공간에 대하여 작업하여야 하는 점이 다른 C 언어 실행 환경과 다른 점이다.
- 텍스처 랜더링은 지원 되지 않는다.
- 배정도에 관해서는 IEEE 754 표준과 다르지 않다. 단정도에서는 비정상값과 신호 NaN이 지원되지 않고, IEEE 반올림 모드 가운데서는 두가지만 지원하며, 이도 명령어에 따라서 지원되는 것으로 제어 단어(Control word)에서 지원 되는 것은 아니다.(이것이 제한점인지는 논란의 대상이 될 수 있다) 그리고 나눗셈과 제곱근의 정밀도가 단정도에 비해 조금 낮다.
- CPU와 GPU 사이의 버스 대역폭과 시간 지연에서 병목이 발생할 수 있다.
- 스레드가 최소한 32개씩 모여서 실행되어야 최선의 성능 향상을 얻을 수 있으며, 스레드 수의 합이 수천개가 되어야 한다. 프로그램 코드에서의 분기는, 각각의 32 스레드가 같은 실행 경로를 따른다면, 성능에 큰 지장을 주지 않는다. SIMD 실행 모델은 어떠한 내재적으로 분기하는 임무에게는 심각한 제한이 된다. (예를 들어, 광선 추적 가속 자료 구조)
- 쿠다 기반 GPU는 엔비디아에서만 나온다.
[편집]지원 GPU[1]
아래 링크는 공식적으로 CUDA를 지원하는 장치들을 나열한다.
CUDA를 사용할 수 있는 GPU 제품.
[편집]예제
이 예제는 C++로 작성되었으며 텍스처 하나를 어떤 이미지로부터 GPU상의 행렬로 읽어들인다.:
cudaArray* cu_array; texture<float, 2> tex; // 행렬 할당 cudaMallocArray(&cu_array, cudaCreateChannelDesc<float>(), width, height); // 이미지 데이터를 행렬로 복사 cudaMemcpy(cu_array, image, width*height, cudaMemcpyHostToDevice); // 행렬을 텍스처에 연결한다. cudaBindTexture(tex, cu_array); // 커널을 실행한다 dim3 blockDim(16, 16, 1); dim3 gridDim(width / blockDim.x, height / blockDim.y, 1); kernel<<< gridDim, blockDim, 0 >>>(d_odata, width, height); cudaUnbindTexture(tex); __global__ void kernel(float* odata, int height, int width) { unsigned int x = blockIdx.x*blockDim.x + threadIdx.x; unsigned int y = blockIdx.y*blockDim.y + threadIdx.y; float c = texfetch(tex, x, y); odata[y*width+x] = c; }
아래 예제는 파이선이며 두 배열의 곱을 GPU 상에서 계산한다. 파이선 언어의 바인딩은 PyCUDA 에서 구할 수 있다.
import pycuda.driver as drv import numpy import pycuda.autoinit mod = drv.SourceModule(""" __global__ void multiply_them(float *dest, float *a, float *b) { const int i = threadIdx.x; dest[i] = a[i] * b[i]; } """) multiply_them = mod.get_function("multiply_them") a = numpy.random.randn(400).astype(numpy.float32) b = numpy.random.randn(400).astype(numpy.float32) dest = numpy.zeros_like(a) multiply_them( drv.Out(dest), drv.In(a), drv.In(b), block=(400,1,1)) print dest-a*b
행렬 곱셈을 단순화하는 추가 파이선 바인딩은여기 있다.
import numpy from pycublas import CUBLASMatrix A = CUBLASMatrix( numpy.mat([[1,2,3],[4,5,6]],numpy.float32) ) B = CUBLASMatrix( numpy.mat([[2,3],[4,5],[6,7]],numpy.float32) ) C = A*B print C.np_mat()
[편집]같이 보기
[편집]주석
[편집]참고 문헌
- 제이슨 샌더스, 에드워드 캔드롯 저, 박춘언 역, 예제로 배우는 CUDA 프로그래밍(입문자를 위한 GPGPU 프로그래밍의 기초), ISBN 9788994774060.
- Farber, Rob 저, CUDA Application Design and Development, ISBN 9780123884268.
- Hwu, Wen-Mei 저, GPU Computing GEMs - Jade Edition, ISBN 9780123859631.
[편집]바깥 고리
- Nvidia CUDA 홈페이지
- Nvidia CUDA GPU 개발자 포럼
- Nvidia CUDA 개발자등록 페이지
- Beyond3D - Introducing CUDA Nvidia's Vision for GPU Computing (16th February 2007)
- Introduction to CUDA for Computer Scientists
| [숨기기] 엔비디아 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 게이밍 GPU |
| ||||||||
| 메인보드 | 엔포스 칩셋 · 아이온 · 엔포스 220/415/420 · 엔포스2 · 사운드스톰 · 엔포스3 · 엔포스4 · 엔포스 500 · 엔포스 600 · 엔포스 700 | ||||||||
| 엔포스 칩셋 기술 | EPP 2.0 | ||||||||
| 워크스테이션 및 HPC | 쿼드로 · 쿼드로 플렉스 · 테슬라 | ||||||||
| 게임기 | 엑스박스: (NV2A) · 플레이스테이션 3: (RSX) | ||||||||
| MID | 고포스 · 테그라 · 오픈KODE: (오픈GL ES 2.0) | ||||||||
| 드라이버 | 포스웨어 · 시스템 도구: (nTune) · CUDA · PhysX | ||||||||
| 개발 및 기타 | ESA 플랫폼 · 소프트웨어 가속: (Gelato · 퓨어비디오) · Cg | ||||||||
| 합병 / 인수 | 3dfx · 에이지아 | ||||||||
CUDA (Compute Unified Device Architecture : 쿠다) 는 NVIDIA 가 제공하는 GPU 를위한 C 언어 의 통합 개발 환경 이며, 컴파일러 와라이브러리 등으로 구성되어있다.
목차[ 숨기기 ] |
개요 [ 편집 ]

GPU를위한 프로그래밍 환경으로 Cg 를 이용한 것도 있지만, 이쪽은 CG 그리기 전용 프로그래밍 환경이되고, 변수 의 형 에 GPU 특유의 형 밖에 사용할 수없는 등 범용적인 프로그램의 작성은 곤란하다. CUDA는 C 언어와 같은 언어를 사용하고 있기 때문에, 범용 컴퓨팅에 적합하다.
GPU는 간단한 연산 유닛을 다수 탑재하고있다. 따라서 동시성 높은 연산 처리를 할 경우 약간 복잡한 구성을 가진 같은 규모의 CPU 보다 높은 성능을 낼 수있다.
언어 [ 편집 ]
CUDA C는 C 언어 와 C + + 의 일부 구문 만 지원. C 언어를 확장하고있다. BLAS 인터페이스 를 통해 벡터 · 행렬 연산이 가능. FFT 라이브러리도 함께 제공한다.
CUDA 포트란 은 The Prortland Group에서 제공되고있다. Fortran 2003 을 확장하고있다.
언어 바인딩 [ 편집 ]
C 언어 이외에서 CUDA를 부를 수에 바인딩이있다.
- Python - PyCUDA
- Java - Hoopoe jCUDA , JCuda.org , JCublas , JCufft
- . NET - Hoopoe CUDA.NET
그 밖에도, Fortran, Perl, Ruby, Lua, MATLAB, IDL, Mathematica 등도있다.
해당 환경 [ 편집 ]
하드웨어 [ 편집 ]
전용 드라이버 를 필요로하기 때문에 GeForce 8 시리즈 이상 (넷북 / 톱의 NVIDIA ION 포함) 또는 NVIDIA Tesla 및 NVIDIA Quadro . Tesla는 고성능 컴퓨팅 용 Quadro는 워크 스테이션 용. 자세한 내용은 CUDA를 사용 가능한 GPU 제품 을 참조.
OS [ 편집 ]
현재의 대응 OS 는 32bit 버전과 64bit 버전 Windows XP 이후 Fedora 7 이상, Red Hat Enterprise Linux 3 이상 SUSE 리눅스 Enterprise Desktop 10-SP1, OpenSUSE 10.1, Ubuntu7.04 이후 Mac OS X 10.5.2 이상 있다.
해당 소프트웨어 [ 편집 ]
CUDA 연산 처리 기술을 이용하려면 위의 하드웨어 OS 지원 외에도 응용 프로그램이 지원하는 것이 필요. 일부 응용 프로그램 공급 업체에서 해당 소프트웨어가 나오고있다.
- MediaCoder ( MediaCoder ) (프리 소프트웨어)
- LoiLoTouch ( LoiLo )
- Super LoiLoScope ( LoiLo )
- PowerDirector ( CyberLink )
- PowerDVD ( CyberLink )
- VideoStudio Pro X3 ( COREL )
- VideoStudio Ultimate X3 ( COREL )
- TMPGEnc (페가시스)
- Adobe Photoshop CS4 ( Adobe )
- Adobe After Effects CS4 ( Adobe )
- Adobe Premiere Pro CS4 ( Adobe )
- Vegas Pro 10 ( Sony Creative Software )
- 경로 게터 ( 내부 )
분산 컴퓨팅 [ 편집 ]
이들은 BOINC 클라이언트에서 CUDA를 이용한다.
- SETI @ Home
- Milkyway @ home
- GPUGRID (PS3GRID)
- AQUA @ home
- Folding @ Home (이 프로젝트에만 원래 클라이언트에서 동작)
MATLAB [ 편집 ]
MATLAB 과의 협업을 지원하고있다. 무거운 프로그램 스크립트 실행 속도에 기여한다. 공개 된 플러그인과 함께 제공되는 데모 스크립트 의 FFT 는 CUDA없이 비해 4 분의 1의 실행 시간이되었다.
출처 [ 편집 ]
- ^ 닛케이 일렉트로닉스 2007/10/8 "프로세서는 멀티 × 멀티에"
관련 항목 [ 편집 ]
- NVIDIA
- NVIDIA Tesla
- 고성능 컴퓨팅
- 컴파일러
- GPU
- GPGPU
- OpenCL
- ATI Stream 현 ATI Technologies - AMD (구 ATI社)의 ATI FirePro , RADEON 을 사용하여 경합 규격
관련 서적 [ 편집 ]
- 처음 CUDA 프로그래밍 (글 : 아오키尊之,額田아키라 간 : 공학사) ISBN 978-4777514779
- CUDA 고속 GPU 프로그래밍 입문 (감수 : 오 야마다耕두 글 : 오카다 켄지 간 : 히데카즈 시스템) ISBN 978-4798025780
- CUDA by Example : An Introduction to General-Purpose GPU Programming ISBN 0131387685
외부 링크 [ 편집 ]
범용 GPU(General-Purpose computing on Graphics Processing Units, GPGPU)는 GPGP 또는 GP2 라고도 불리며, 컴퓨터 그래픽스를 위한 계산만 다루는 GPU를 사용하여 CPU가 전통적으로 취급했던 응용 프로그램들의 계산을 수행하는 기술이다. 이를 가능하게 한 것은 프로그램 가능한 층과 고정도 연산을 그래픽 파이프라인에 연결하는 것으로, 이를 통하여 소프트웨어 개발자들이 그래픽이 아닌 데이터에 스트림 프로세싱을 사용할 수 있게 된다.
목차[숨기기] |
[편집]GPU 개선
GPU 기능은 전통적으로 매우 제한적이었다. 사실 여러 해 동안 GPU는 단지 그래픽스 파이프라인의 특정 부분을 가속시키기 위해서만 사용되었다. GPGPU가 가능하려면 몇 가지 개선이 필요했다.
[편집]가프로그램성
프로그램 가능한 꼭지점 및 프래그먼트 셰이더가 그래픽스 파이프라인에 추가되어 게임 프로그래머가 더 실감나는 효과를 생성시킬 수 있게 되었다. 꼭지점 셰이더로 프로그래머는 꼭지점 각각의 특징, 즉, 위치, 색상, 패턴 좌표, 그리고 수직 벡터를 다르게 할 수 있게 되었다. 프래그먼트 셰이더는 프래그먼트, 또는 각 픽셀의 색상을 계산하는데 사용된다. 프로그램 가능한 프래그먼트 셰이더로 프로그래머는, 예를 들어, 그래픽 카드가 기본으로 제공하지 않는 조명 모델을 사용할 수 있게 된다. 전형적인 예는 간단한 가우드 셰이딩이다. 셰이더로 그래픽스 프로그래머는 렌즈 효과, 변위 매핑, 그리고 필드 깊이를 창조할 수 있게 되었다.
| DirectX 버전 | 발표연도 | 셰이더 모델 |
|---|---|---|
| 8 | 2000 | 셰이더 모델 1.1 |
| 8.1 | 2001 | 픽셀 셰이더 모델 1.2, 1.3, 1.4 |
| 9 | 2002 | 셰이더 모델 2.x, 3.0 |
| 10 | 2006 | 셰이더 모델 4.0, 기하형상 셰이더 |
셰이더 모델의 가프로그램성과 역량은 버전에 따라 점차로 증대되어 DirectX 표준을 따르는 하드웨어가 계속 따라오게끔 하였다. DirectX 10 규격의 셰이더 모델 4.0은 꼭지점, 기하적 형상, 그리고 프래그먼트 처리의 프로그래밍 규격을 통일하여 프로그램을 실행시킬 수 있는 단일한 계산 자원을 제공한다.
[편집]자료형
DirectX 9 이전의 그래픽 카드는 팔레트 또는 정수 색만 지원하였다. RGB 요소를 담은 다양한 형태가 가능하다. 때로 알파 값이 추가되어 투명도에 사용되었다. 흔히 사용된 형태는 다음과 같다:
| 픽셀 당 비트수 | R | G | B | 알파 |
|---|---|---|---|---|
| 8 | 2 | 3 | 3 | |
| 16 | 5 | 6 | 5 | |
| 24 | 8 | 8 | 8 | |
| 32 | 8 | 8 | 8 | 8 |
초기에 확정된 기능 또는 가프로그램성이 제한적이었던 그래픽스(DirectX 8.1 호환 GPU 까지)에서는 이로써 충분하였다. 이는 또한 화면에 사용된 표현 방식이기도 했기 때문이다. 이 표현 방식은 그러나 어떤 제한 조건을 가지고 있다. 그래픽 프로세서 성능이 충분하다면 그래픽 프로그래머도 더 나은 형식을 사용하고 싶어할 것이다. 예를 들어 부동 소수점 자료형식으로 고 동적 범위 이미지효과를 얻을 수 있기 때문이다. 수많은 GPGPU 응용 프로그램은 부동소수점 정밀도를 요구하며 이는 DirectX 9 규격을 따르는 그래픽 카드부터 적용되었다.
DirextX 9의 셰이더 모델 2.x은 전 정밀도와 부분 정밀도의 두가지 정밀 변수형 지원을 제안하였다. 완전 정도는 FP32 아니면 FP24(요소당 24비트의 부동소수점) 또는 그 이상을 지원하는 것이고, 부분 정밀도는 FP 16이었다. ATI의 R300 시리즈 GPU는 FP24 정도를 프로그램 가능한 프래그먼트 파이프라인에서만 지원하였다. 꼭지점 프로세서에서는 FP32를 지원하였다. 반면 엔비디아의 NV30 시리즈는 FP16과 FP32를 지원하였다. 다른 공급 업체, 즉, S3와 XGI는 혼합 형식을 FP24까지 지원하였다.
셰이더 모델 3.0은 규격을 변경하여 전 정밀도 요구 조건을 상향조정하여 최소한 FP32 를 프래그먼트 파이프라인에서 지원하게 하였다. ATI의 셰이더 모델 3.0 준수 R5xx 세대 (라데온 X1000 시리즈) 는 FP32를 파이프라인에 걸쳐 지원하지만 엔비디아의 NV4x와 G7x 시리즈는 FP32 전 정밀도와 FP16 부분 정밀도 모두를 계속 지원하였다. 셰이더 모델 3.0에서 요구되지는 않았지만 ATI와 엔비디아의 셰이더 모델 3.0 GPU는 혼합 FP16 렌더 타겟 지원을 소개하여 보다 쉽게 고 동적 범위 렌더링을 지원할 수 있게 하였다.
엔비디아 GPU 상의 부동 소수점 구현은 거의 IEEE 표준을 따른다. 그러나 모든 공급업체가 그런 것은 아니다.[1] 이로 말미암아 어떤 과학적 응용 분야에 중요한 정확도 문제가 생긴다. 64비트 부동 소수점 (배정도 부동 소수점) 값은 CPU에서는 일반적이지만 GPU 중에는 지원하지 않는 경우도 있다. 어떤 GPU 구조는 IEEE 표준을 벗어나고 어떤 경우는 아예 배정도 자체를 지원하지 않는다. GPU에서 배정도 부동 소수점 값을 모사하려는 노력이 있어왔지만 속도 손실로 말미암아 애초에 계산을 GPU상으로 옮겨서 얻어지는 이득이 사라진다. [2]
GPU 상에서 이루어지는 연산 대부분은 벡터화된 형태로 이루어진다. 한가지 연산이 최대 4개 값에 대해 이루어진다. 예를 들어 한가지 색  가 다른 색상
가 다른 색상 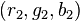 로 모듈레이트된다면 GPU는 결과 색상인
로 모듈레이트된다면 GPU는 결과 색상인  를 한 연산으로 계산할 수 있다. 이 기능은 그래픽스에서 유용한데 그 까닭은 거의 모든 기본 자료형이 (2, 3, 4차원) 벡터이기 때문이다. (예: 꼭지점, 색상, 수직 벡터, 표면 패턴 좌표 등) 많은 다른 응용 프로그램에서 이를 유용하게 사용될 수 있고, 벡터 명령 (SIMD)이 그 우수한 성능으로 CPU상에서 지원되었다.
를 한 연산으로 계산할 수 있다. 이 기능은 그래픽스에서 유용한데 그 까닭은 거의 모든 기본 자료형이 (2, 3, 4차원) 벡터이기 때문이다. (예: 꼭지점, 색상, 수직 벡터, 표면 패턴 좌표 등) 많은 다른 응용 프로그램에서 이를 유용하게 사용될 수 있고, 벡터 명령 (SIMD)이 그 우수한 성능으로 CPU상에서 지원되었다.
2006년 11월 엔비디아는 쿠다를 발표하였는데, 이는 SDK와 API로 프로그래머가 C언어로 알고리즘을 기술하여 지포스 8 시리즈 GPU 상에서 실행시킬 수 있게 해 주는 것이다. AMD는 유사한 SDK를 ATI 기반 GPU와 스트림 SDK(전에는 CTM 클로우즈 투 메탈)라고 부르는 SDK와 기술을 제공한다. 이는 엔비디아의 쿠다와 직접 경쟁을 위해 설계되었다. CTM은 얇은 하드웨어 인터페이스를 제공한다. AMD는 또한 AMD 파이어스트림 제품군도 발표하였다. 이는 CPU와 GPU 기술을 한 칩에 모은 것이다. 전통적인 부동 소수점 가속기, 예를 들어 64비트 클리어 스피드사 CSX700 보드는 오늘날의 수퍼컴퓨터에서 사용되는데, 현재 엔비디아와 AMD에서 나오는 최고급 GPU는 단정도 (32비트)를 강조하고 있다; 배정도 (64비트)는 훨씬 느리게 작동한다.
[편집]GPGPU 프로그래밍 개념
GPU는 그래픽에 특화되어 설계되었으며 따라서 연산과 프로그래밍에 있어서 매우 제한적이다. 그 본성에 따라, GPU는 흐름 처리를 이용하여 풀 수 있는 문제에서만 효과적이며 그 하드웨어를 사용하는 방식은 정해져 있다.
[편집]흐름 처리
GPU는 독립적인 꼭지점들과 프래그먼트만 처리할 수 있지만 다수를 병렬로 처리할 수 있다. 이것은 특히 프로그래머가 같은 방식으로 많은 수의 꼭지점 또는 프래그먼트를 처리하고자 할 때 유용하다. 이런 의미에서, GPU는 흐름 프로세서이다. 즉, 병렬로 한번에 하나의 커널을 흐름 속의 많은 레코드에 실행시키는 것이다. 흐름이란 단순히 유사한 계산을 필요로 하는 레코드의 모음이다. 흐름으로 데이터 병렬성을 구할 수 있다. 커널이란 함수로써 흐름 속의 각 요소에 적용되는 것이다. GPU에서는 꼭지점과 프래그먼트가 흐름 속의 요소이고, 셰이더가 그 위에서 작동하는 커널이다. GPU가 요소들을 독립적으로 처리하므로 공유되는 또는 정적인 데이터는 없다. 단지 각 요소를 입력으로부터 읽고, 연산을 수행하고, 출력으로 쓸 뿐이다. 다양한 입력과 다양한 출력을 갖는 것은 허용되는 편이나 읽고 쓰기에 모두 사용되는 메모리는 없다. 산술 치열도는 전송되는 메모리 워드 당 연산으로 정의된다. 중요한 것은 GPGPU 응용 프로그램이 높은 산술치열도를 가지는 것으로 그렇지 않다면 메모리 접근 불확실성이 계산 속도를 제한할 것이다. 이상적인 GPGPU 응용 프로그램의 데이터 집합은 크고, 병렬도는 높고, 데이터 요소간 의존성은 최소이다.
[편집]GPU 프로그래밍 개념
[편집]계산 자원
GPU가 사용 가능한 계산 자원은 다양하다:
- 프로그램 가능한 프로세서 – 꼭지점, 프리미티브, 프래그먼트 파이프라인으로 프로그래머는 데이터의 흐름에 커널을 배풀 수 있다.
- 비트맵 변환기 – 프래그먼트를 만들고 꼭지점 당 상수-예를 들어 텍스처 좌표와 색상-를 내삽한다
- 텍스처유닛 – 읽기 전용 메모리 계면
- 프레임 버퍼 – 쓰기 전용 메모리 계면
사실, 프로그래머는 프레임 버퍼 대신 쓰기 전용 텍스처로 바꿔치기할 수도 있다. 이는 텍스처로 그리기 Render-To-Texture (RTT) 또는 백버퍼로 그린 후 텍스처로 베께기 Render-To-Backbuffer-Copy-To-Texture(RTBCTT) 아니면 더 최근의 흐름 출력으로 이루어진다.
[편집]흐름으로서의 텍스처
GPGPU에서 흐름이 취하는 가장 일반적인 형태는 2차원 격자이다. GPU안에 만들어져 있는 랜더링 모델에 알맞기 때문이다. 다수의 계산이 격자 형태로 변환될 수 있다: 행렬 계산, 이미지 처리, 물리 기반 시뮬레이션 등. 텍스처가 메모리로 사용되므로 텍스처 룩업은 메모리 읽기로 사용된다. 이 덕분으로 어떤 연산은 GPU에 의해 자동으로 이루어진다.
[편집]커널
커널은 반복문의 본체라고 생각할 수 있다. 예를 들어 만일 프로그래머가 CPU로 격자행렬을 다룬다면 그 코드는 다음과 비슷할 것이다:
// 입출력 격자는 각각 10000 x 10000를 가지고 있다. void transform_10k_by_10k_grid(float in[10000][10000], float out[10000][10000]) { for(int x = 0; x < 10000; x++) { for(int y = 0; y < 10000; y++) { // 다음 행이 100만 번 실행된다. out[x][y] = do_some_hard_work( in[x][y] ); } } }
GPU상에서 프로그래머가 지정하는 것은 반복문의 본체 부분 (커널이 된다) 과 반복문이 기하 처리할 데이터 뿐이다.
[편집]흐름 제어 (flow control)
순차 코드에서는 if-then-else문과 다양한 반복문으로 흐름을 제어하는 것이 가능하다. 최근에야 비로소 이러한 흐름 제어 구조가 GPU에 추가되었다.[3] 조건부 쓰기는 일련의 더 간단한 명령을 쓰는 것으로 이루어질 수 있었지만, 반복문이나 조건부 분기는 불가능했다. 최근의 GPU는 분기를 허용하지만, 보통 성능상 손실을 감수해야 한다. 분기를 일반적으로 안쪽 반복문에서는 피해야 하는 것은 CPU나 GPU나 마찬가지이고, 다양한 기술, 즉, 정적 분기 해소, 선계산, Z-cull[4]로 하드웨어 지원이 없을 때 분기할 수 있다.
[편집]GPU 기법
[편집]변환 (map)
변환 연산은 주어진 함수 (커널)을 스트림의 모든 요소에 적용한다. 간단한 예로 스트림의 모든 값에 어떤 상수를 곱하는 것이다. (밝기 조절) 변환 연산은 GPU상에서 간단히 구현된다. 프로그래머는 화면의 각 픽셀의 프래그먼트를 생성하고 각각에 프래그먼트 프로그램을 적용한다. 결과로 얻어지는 같은 크기의 스트림이 출력 버퍼에 저장된다.
[편집]감축
어떤 계산은 큰 흐름으로부터 작은 흐름(단 한개의 요소만 남을 수도 있다)을 계산해야 한다. 이를 흐름의 감축이라 부른다. 일반적으로 감축은 여러 단계로 이루어질 수 있다. 이전 단계의 결과가 이번 단계의 입력으로 사용되고, 연산이 적용되는 범위가 흐름 요소 하나만 남을 때 까지 반복된다.
[편집]흐름 필터링
흐름 필터링은 본질적으로 불균일 감축이다. 필터링은 어떤 기준에 따라 흐름에서 일부 요소를 제거하는 것이다.
[편집]흩뿌리기
흩뿌리기 연산은 꼭지점 처리에서 가장 자연스럽게 정의된다. 꼭지점 처리는 꼭지점의 위치를 조정할 수 있어서 프로그래머가 정보를 격자의 어디에 예치하는지 제어할 수 있게 해 준다. 다른 확장도 가능한데, 예를 들어 꼭지점이 영향을 미치는 영역의 크기를 제어하는 것이다. 프래그먼트 처리기는 직접 뿌리기 연산을 수행할 수 없는데, 그 까닭은 격자상에서 각 프래그먼트의 위치는 프래그먼트가 생성될 때 고정되어 프로그래머가 변경할 수 없기 때문이다. 그러나 논리적 흩뿌리기 연산은 추가적인 수집 단계로 때때로 재투사 또는 구현될 수 있다. 흩뿌리기를 구현하려면 먼저 출력값과 출력 주소 모두를 송출해야 한다. 그 직후의 수집 연산은 주소 비교를 통해 출력 값이 현재의 출력칸에 맞아떨어지는지 확인한다.
[편집]수집
프래그먼트 처리기는 텍스처를 임의 방식으로 읽을 수도 있어서 단수/복수의 어떤 격자 칸으로부터도 원하는 대로 정보를 모을 수 있다.
[편집]정렬
정렬 연산은 순서 없이 뒤섞인 요소 집합을 순서에 따라 정렬된 요소의 집합으로 변환한다. 가장 일반적인 GPU 구현은 정렬망을 이용하는 것이다.
[편집]탐색
탐색 연산으로 프로그래머는 흐름 안의 특정 요소 또는 특정 요소의 이웃 요소를 찾을 수 있다. GPU는 한 요소를 찾는 속도를 올리기 위해 사용되지는 않지만 대신 여러 탐색을 병렬로 실행하는 데 사용된다.
[편집]자료 구조
다양한 자료 구조가 GPU상에서 표현될 수 있다:
- 고밀도 배열
- 저밀도 배열 - 정적, 또는 동적
- 적응 구조
[편집]기타
GPGPU로 CPU 한 개에 비해 100배~250배의 속도 향상을 이룰 수 있지만, 병렬도가 지극히 높은 응용 프로그램에서만 이 정도의 혜택을 볼 수 있을 것이다. 한 개의 GPU 처리 코어는 데스크톱 CPU의 코어 한개와 대등하지 않다.
[편집]같이 보기
[편집]바깥 고리
[편집]참고 문헌
- ↑ Mapping computational concepts to GPUs: Mark Harris. Mapping computational concepts to GPUs. In ACM SIGGRAPH 2005 Courses (Los Angeles, California, July 31 – August 4, 2005). J. Fujii, Ed. SIGGRAPH '05. ACM Press, New York, NY, 50.
- ↑ Double precision on GPUs (Proceedings of ASIM 2005): Dominik Goddeke, Robert Strzodka, and Stefan Turek. Accelerating Double Precision (FEM) Simulations with (GPUs). Proceedings of ASIM 2005 – 18th Symposium on Simulation Technique, 2005.
- ↑ GPU Gems - Chapter 34, GPU Flow-Control Idioms
- ↑ GPGPU survey paper: John D. Owens, David Luebke, Naga Govindaraju, Mark Harris, Jens Krüger, Aaron E. Lefohn, and Tim Purcell. "A Survey of General-Purpose Computation on Graphics Hardware". Computer Graphics Forum, volume 26, number 1, 2007, pp. 80-113.
GPGPU (General-purpose computing on graphics processing units; GPU에 의한 범 목적 계산)은 GPU 의 연산 자원을 이미지 처리 이외의 목적으로 응용하는 기술이다.
목차[ 숨기기 ] |
개요 [ 편집 ]
GPU는 일반적으로 화상 처리 를 전문으로하는 연산 장치이며, 많은 경우 CPU라는 주로 처리 장치의 제어 아래에서 사용되는 비디오 신호 생성 전용 보조 연산 용 IC 이다. 동영상의 순간에서의 발생은 고부하 연산 능력이 요구되지만, 그 대부분이 공식화 된 단순한 연산의 반복이기 때문에 하드웨어 화 향하고있어 GPU를 제조하고있다 반도체 메이커 몇 회사로부터는 고속 메모리 인터페이스 기능과 높은 이미지 연산 능력을 갖춘 IC 제품 시리즈가 여러 제조 · 판매되고있다.
특히 90 년대 중반 이후는 3D 성능이 극적으로 향상하고 그에 따라 행렬 연산을 중심으로 한 SIMD 연산 기의 색채가 강하게되었다. 2000 년대에 들어서면서, 표현력의 향상을 요구하고 고정 기능 쉐이더에서 프로그래머블 쉐이더 로의 이행이 진행 연산의 자유도가 비약적으로 증가했다. 그래서 이것을 그래픽 렌더링뿐만 아니라, 다른 수학에도 이용하는 것이 GPGPU의 개념이다.
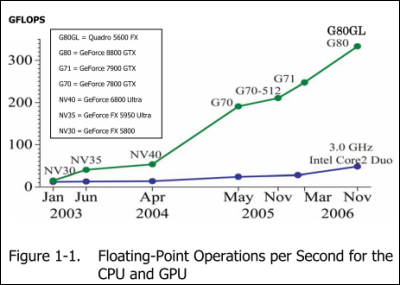
GPU의 부동 소수점 연산 능력은 2010 년경에 2000 G FLOPS 를 초과하는 한편, CPU의 부동 소수점 연산 능력은 한계점 도달 상태이며, 2011 년 시점에서 수십 GFLOPS 대에 머물고있다. GPU는 구성이 간단하기 때문에 부동 소수점 연산의 효율이 좋고, GPU 전용으로 로컬 연결된 메모리 IC와 메모리 대역폭을 넓게 대비하기 위해 CPU에 비해 성능 대비 저렴하고 성장의 성장 비율이 높은 ( 참고 : GPU와 CPU의 성능 향상 비교 ). 또한 주요 용도가 PC 게임 과 동영상 재생, 게임을하지 않는 사용자에게여 기색 자원이기도 주목되고있다.
DirectX 9.0의 등장 이후, NVIDIA 에 따르면 GPGPU 전용의 통합 개발 환경 " CUDA "이나 AMD 의 " ATI Stream "이 나타나고 GPGPU 활용의 폭이 넓어지고있다. AMD는 자사 GPU 제품 " AMD FireStream " [1] 을 NVIDIA 앞서서 배정도 부동 소수점 연산 HPC 용으로 출시 한 또한 NVIDIA는 자사의 GPU " G80 "을 기반으로 한 HPC 전용 GPGPU " Tesla " 을 투입하는 등 기존의 벡터 계산기 에서 대체를 염두에 둔 시장 전개를하고있다.
특징과 과제 [ 편집 ]
조건 분기 [ 편집 ]
GPU는 쉐이더 프로세서 라는 다수의 연산 유닛을 가지고 여러 쉐이더 프로세서를 정리해 클러스터 하고있다. 이러한 연산기에 명령을주는 지침 장치는 클러스터 당 하나 밖에없고, 클러스터 구성 쉐이더 프로세서는 각각 다른 데이터를주고 그 데이터에 대해서 같은 명령 내용을 한 번에 수행한다. 이 같은 SIMD 형 데이터 처리 3 차원 연산 및 멀티미디어 처리에 효과를 발휘하는 한편, 명령 중에 조건 분기의 분기 가 들어가면 부담이 늘어나, 바로 그때 효율을 떨어 뜨린다. 오늘의 CPU 는 이러한 패널티를 최소화하기 위해 프리 페치 / 프리 디코드 및 투기 실행 / 레지스터 리 네이밍 등의 기능을 갖추고 있지만, GPU는 갖추지 않았다. 또한 쉐이더 프로세서간에 데이터를 교환하는 경우, 먼 데이터 버스 를 경유하게되고, 그것이 병목 현상이되어 버린다.
일반 응용 프로그램에서 조건 분기가 존재하지 않는 것은 드물고, 이러한 제약에 의해 GPU는 오피스 스위트와 같은 응용 프로그램 의 실행에는 적합하지 않다. GPGPU의 발전에 어떻게 효율성을 떨어 뜨리지 않고 조건 분기를하는가하는 것이 하나의 과제가되고있다. 원리 적으로는 간단한 알고리즘 구조를 가진 프로그램은 병렬 데이터 처리에 최적화 할 수 GPGPU의 장점을 최대한 끌어내는 것에 연결된다고 할 수있다.
부동 소수점 연산과 로컬 메모리 [ 편집 ]
AMD 는 2006 년 에 R5xx 코어를 사용하여 단 정밀도 부동 소수점 연산을위한 첫 세대 AMD FireStream 을 발매, 이어 2007 년 에 R6xx 코어를 사용한 배정도 부동 소수점 연산을위한 두 번째 세대 AMD FireStream 을 발매, 또한 2008 년 에 발매 된 RADEON HD 4850은 1 칩으로는 세계 최초의 1TFLOPS 달성이 RADEON HD 4850에 사용 된 R7xx 코어를 사용하여 저렴하고 고성능을 팔러 배정도 부동 소수점 연산 HPC 분야 용으로 셋째 세대 AMD FireStream 을 출시하게됐다. 2010 년 에는 더욱 고성능화 한 제 4 세대 AMD FireStream 을 발매하고있다. NVIDIA 도 2010 년 에 발매 된 NVIDIA Tesla 20 시리즈에서 배정 밀도도 단정의 절반 속도로 실행할 수있게되었지만, GPU는 배정 밀도의 부동 소수점 연산이 서툼이다. GPU가 처리 많은 이미지 연산은 정수 연산 및 단 정밀도 부동 소수점 연산에서 부족 버리기 때문에 부동 소수점 연산기는 가수 부 24 비트 정도로 그다지 넓지 않고, 배정도 부동 소수점 연산을 할 분할하여 몇번이고 연산기를 사용할 필요가있다.
메모리 환경에 대해서도 연산 입력 약간의 격자 점 데이터에 약간 큰 텍스처 데이터 것이고, 연산 출력 이미지 1 장 정도의 크기의 픽셀 당 3 색의 데이터를 유지하면서 순차적 그들을 발송 데만하여 적절히 큰 외부 반도체 메모리와 상당히 넓은 메모리 대역폭의 연결에서 충분히 대응하고, 연산 대상 데이터의 국소성이 높기 때문에 로컬 메모리와 내부 캐시를 통해 데이터를 읽고 쓰는 성능이 향상하면 동시에 연산도 끊기지 않고 순차적 실시 경향이 강하다.
기본적으로 GPU는 배열 구조의 간단한 데이터를 단정 정도의 부동 소수점 연산을 통해 순차적으로 처리함으로써 2 차원의 동영상 데이터를 실시간에 생성하는 것에 특화되어 있기 때문에, 그 이외 용도로는 그다지 높은 성능은 기대할 수 없다. 화상 처리 전용 IC의 유용은 과학 기술 계산에서 배정 밀도 이상의 부동 소수점 연산을 필요로하고, 연산의 국소성이 낮은 것은 그만큼 높은 성능을 얻을 수 없다. 화상 처리 전용이 아닌 GPU에서 파생 새롭게 개발 된 GPGPU 용 IC는 배정도 부동 소수점 연산과보다 넓은 메모리 공간을 지원하는 것이 있는데, 이들은 광범위한 과학 기술 계산에 이용이 기대된다. 다른 한편으로는, 이미지 처리 분야에서는 거의 필요로하지 않는 메모리의 중복기구 인 ECC 가 HPC 분야에서는 필수되므로 IC를 공유 할 때 제약이 될 [2] .
적합 분야 [ 편집 ]
GPGPU에서 성능이 향상 프로그램으로는
연산으로는
등이 기대되고있다 [3] .
실제 소프트웨어의 등장 [ 편집 ]
GPGPU 기술의 화제는, PC의 진화에서 최근의 트렌드이며 과제였다. 그러나 논증 만이 선행하고 실제로 활용할 수있는 소프트웨어가 발매 될 수 없었다. 2008 년 가을부터, S3가 GPU를 이용한 GPGPU 용 사진 수정 소프트웨어 "S3FotoPro"을 발표 [2] , 또한 동영상 편집 가공 소프트웨어는 동영상 인코딩 소프트웨어의 대표격인 TMPGEnc 가 CUDA에 대응 한 [3] 을 시작으로 Cyberlink 의 PowerDirector 7 CUDA 및 ATI Stream을 지원하는 [4] . 또한 2009 년 에는 Super LoiLoScope (PixelShader 2.0을 활용)이 발매 [5] , Cyberlink 가MediaShow Espresso (CUDA 및 ATI Stream을 지원)을 발매하고있다. GPGPU를 이용한 무료로 이용 가능한 동영상 인코딩 소프트웨어로, AMD의 ATI AVIVO (완전 무료)와 Nvidia의 Badaboom (30 일 무료 평가판), Mediacoder의 CUDA 인코더를들 수있다. 이렇게 GPGPU 기술을 탑재 한 소프트웨어가 속속 등장하고있어, 간신히 GPGPU를 본격적으로 활용할 수있는 환경이 정비되었다고 할 수있다.
미 Adobe社는 2010 년 5 월 28 일 발매 [4] 한 Creative Suite5 (CS 5)에서 GPGPU를 공식적으로 지원했다. CS5는 OpenCL 기반으로 개발되었으며, 거의 모든 기능에서 GPGPU의 연산을 수행 할 수있다. 본래 GPU는 이미지 처리를 자랑하기 때문에 이미지 처리를 주체로하는 회사의 응용 프로그램에 적당은 높다.
각주 [ 편집 ]
- ^ FireStream - 제품 정보
- ^ 하이브리드 아키텍처에서 슈퍼 컴퓨터 시장에 도전 NVIDIA - 고토 히로시 시게루의 Weekly 해외 뉴스 (PC Watch, Impress社, 2012 년 4 월 16 일 전달, 2012 년 4 월 16 일 검색)
- ^ 바뀐 예는 카스퍼 스키 랩 이 현재 Radeon HD 2900으로 가고있는 실증 시험으로, GPU의 파워를 사용하여 보안 소프트웨어 의 대략적인 보안 검사 기능을 개발하고있다. 이를 통해 CPU의 부담을 줄일 수 있다고하고있다 [1] .
- ^ ZDNet Japan Staff ( 2010 년 4 월 12 일 ). " 어도비 크리에이티브 제품의 최신 버전 "CS5"를 5 월 28 일에 일제히 발매 " . CNET Japan. 2010 년 8 월 18 일 보기.
관련 항목 [ 편집 ]
- CUDA
- ATI Stream
- S3 Chrome
- Cg
- OpenCL
- GLSL
- Microsoft DirectX11 DirectX Compute
- 하마다 츠요시
- Folding @ Home - GPGPU를 이용한 분산 컴퓨팅 프로젝트
- BOINC - 외계 지적 생명체 탐사 ( SETI @ home )과 GPUGRID 등의 프로젝트가 GPU (CUDA)에 대응
출처 - http://ko.wikipedia.org/wiki/CUDA
 GPU-intro.pptx
GPU-intro.pptx출처 - caeagle.yonsei.ac.kr/jhkim/pp/GPU-intro.pptx
'Computer Science > Parallel Computing' 카테고리의 다른 글
| OpenMP (0) | 2013.03.25 |
|---|---|
| CUDA - Host Memory와 Device Memory의 사이의 데이터 전송 (0) | 2013.03.25 |
| 병렬 컴퓨팅 (0) | 2012.11.03 |
| 메시지 전달 인터페이스(Message Passing Interface, MPI) (0) | 2012.11.03 |






{kind=link}