VO
개념
Value Object는 DTO와 동일한 개념이나 차이 점은 read only 속성을 갖습니다.
Value Object는 관계데이터베이스의 레코드에 대응되는 자바클래스입니다. 형태는 db레코드를 구성하는 필드들을 Value Object의 Attribute로 하고 해당 변수에 접근 할 수 있는 Getter Setter 메소드의 조합으로 클래스를 형성되어진 클래스입니다. 특성은 대체로 불변성이고 equals()로 비교할 때 객체의 모든 값을 비교해야 합니다.
필요성
Network traffic을 줄임으로 인해서 효과적입니다.
기대효과
Network traffic이 줄어듭니다.
장 단점
장점으로는 비 서버 측 클라이언트도 네트워크 오버헤드 없이 영속성 데이터에 액세스 할 수 있다는 점입니다. 데이터 전달을 위해 가장 효율적인 방법이지만, 클래스의 선언을 위해 많은 코드가 필요합니다. 즉 파일수가 많아지게 되고 관리도 힘들어지게 됩니다.
예제 소스코드
DTO
개념
데이터가 포함된 객체를 한 시스템에서 다른 시스템으로 전달하는 작업을 처리하는 객체입니다. Vo와 dto의 차이점은 vo는 특정한 비즈니스 값을 담는 객체를 vo라 하고 dto는 레이어간의 통신용도로 오가는 객체를 dto라고 합니다.
Vo와 DTO의 비교
DTO의 나머지 속성은 vo와 똑같다고 생각하여서 차라리 차이점을 비교하려고 합니다.
Core J2EE Patterns 라는 책에서는... Value Object랑 Transfer Object를 동일한 뜻으로 사용합니다만 반대로 Martin Fowler는 저서 Patterns of Enterprise Application Architecture에서 약간 다른 의미로 이야기 합니다. DTO는 메소드 호출 횟수를 줄이기 위해 데이터를 담고 있는 녀석으로, VO는 값이 같으면 동일 오브젝트라고 볼 수 있는 녀석으로 표현을 하고 있습니다.
쉽게
DTO a = new DTO(1);
DTO b = new DTO(1);
이라고 했을 때 a != b 이지만,
VO a = VO(1);
VO b = VO(1); 이라고 했을때는 a == b라고 정의하는 형태입니다.
사실 이러한 내용도 헷갈리는 부분이 있는게 대부분의 검색에서 사람들은 vo와 dto를 같은 개념으로 이야기 하고 있어서 아직도 vo와 dto가 “이런거다”라기 보다 거의 똑 같은 개념으로 생각하고 있습니다.
DAO
개념
데이터 접근을 목적하는 객체입니다. 커넥션 같은 것을 하나만 두고 여러 사용자가 DAO의 인터페이스를 사용하여 필요한 자료에 접근 하도록 하는 것이 DAO의 개념입니다.
필요성
모든 데이터베이스에 공통적으로 접속 할 수 있는 ODBC가 나왔지만 완벽하진 못했습니다. 여전히 로우 레벨의 API를 포함하고 있었기 때문에 개발 장벽이 여전히 높았습니다. 이런 이유 때문에 개발자들은 정작 데이터베이스에 들어 있는 데이터를 어떻게 이용할지에 초점을 맞추기 보다, 어떻게 데이터베이스에 접속해서 데이터베이스와 교류하는지에 더 초점을 기울였습니다. 즉 데이터를 활용하는 논리적 고민보다 기술적 고민에 더 많은 신경을 썻었습니다. 이런 이유로 DAO란 대안이 나왔습니다.
기대효과
사용자는 자신이 필요한 Interface를 DAO에게 던지고 DAO는 이 인터페이스를 구현한 객체를 사용자에게 편리하게 사용 할수 있도록 반환해줍니다.
장 단점
DB에 대한 접근을 DAO가 담당하도록 하여 데이터베이스 엑세스를 DAO에서만 하게 되면 다수의 원격호출을 통한 오버헤드를 VO나 DTO를 통해 줄일수 있고 다수의 DB 호출문제를 해결할 수 있습니다. 또한 단순히 읽기만 하는 연산이므로 트랜잭션 간의 오버헤드를 감소할 수 있습니다.
그러나 Persistent Storage를 너무 밀접하게 결합해서 작성을 하게 되면 Persistent Stroage를 다시 작성할 경우가 생기는데 이러한 경우 유지 보수의 문제가 생길수도 있습니다.
예제 소스코드
출처 - http://choijaehyuk.com/128
JavaBeans
A JavaBean is a class that follows the JavaBeans conventions as defined by Sun. Wikipedia has a pretty good summary of what JavaBeans are:
JavaBeans are reusable software components for Java that can be manipulated visually in a builder tool. Practically, they are classes written in the Java programming language conforming to a particular convention. They are used to encapsulate many objects into a single object (the bean), so that they can be passed around as a single bean object instead of as multiple individual objects. A JavaBean is a Java Object that is serializable, has a nullary constructor, and allows access to properties using getter and setter methods.
In order to function as a JavaBean class, an object class must obey certain conventions about method naming, construction, and behavior. These conventions make it possible to have tools that can use, reuse, replace, and connect JavaBeans.
The required conventions are:
- The class must have a public default constructor. This allows easy instantiation within editing and activation frameworks.
- The class properties must be accessible using get, set, and other methods (so-called accessor methods and mutator methods), following a standard naming convention. This allows easy automated inspection and updating of bean state within frameworks, many of which include custom editors for various types of properties.
- The class should be serializable. This allows applications and frameworks to reliably save, store, and restore the bean's state in a fashion that is independent of the VM and platform.
Because these requirements are largely expressed as conventions rather than by implementing interfaces, some developers view JavaBeans as Plain Old Java Objects that follow specific naming conventions.
POJO
A Plain Old Java Object or POJO is a term initially introduced to designate a simple lightweight Java object, not implementing any javax.ejb interface, as opposed to heavyweight EJB 2.x (especially Entity Beans, Stateless Session Beans are not that bad IMO). Today, the term is used for any simple object with no extra stuff. Again, Wikipedia does a good job at defining POJO:
POJO is an acronym for Plain Old Java Object. The name is used to emphasize that the object in question is an ordinary Java Object, not a special object, and in particular not an Enterprise JavaBean (especially before EJB 3). The term was coined by Martin Fowler, Rebecca Parsons and Josh MacKenzie in September 2000:
"We wondered why people were so against using regular objects in their systems and concluded that it was because simple objects lacked a fancy name. So we gave them one, and it's caught on very nicely."
The term continues the pattern of older terms for technologies that do not use fancy new features, such as POTS (Plain Old Telephone Service) in telephony, and PODS (Plain Old Data Structures) that are defined in C++ but use only C language features, and POD (Plain Old Documentation) in Perl.
The term has most likely gained widespread acceptance because of the need for a common and easily understood term that contrasts with complicated object frameworks. A JavaBean is a POJO that is serializable, has a no-argument constructor, and allows access to properties using getter and setter methods. An Enterprise JavaBean is not a single class but an entire component model (again, EJB 3 reduces the complexity of Enterprise JavaBeans).
As designs using POJOs have become more commonly-used, systems have arisen that give POJOs some of the functionality used in frameworks and more choice about which areas of functionality are actually needed. Hibernate and Spring are examples.
Value Object
A Value Object or VO is an object such as java.lang.Integer that hold values (hence value objects). For a more formal definition, I often refer to Martin Fowler's description of Value Object:
In Patterns of Enterprise Application Architecture I described Value Object as a small object such as a Money or date range object. Their key property is that they follow value semantics rather than reference semantics.
You can usually tell them because their notion of equality isn't based on identity, instead two value objects are equal if all their fields are equal. Although all fields are equal, you don't need to compare all fields if a subset is unique - for example currency codes for currency objects are enough to test equality.
A general heuristic is that value objects should be entirely immutable. If you want to change a value object you should replace the object with a new one and not be allowed to update the values of the value object itself - updatable value objects lead to aliasing problems.
Early J2EE literature used the term value object to describe a different notion, what I call a Data Transfer Object. They have since changed their usage and use the term Transfer Object instead.
You can find some more good material on value objects on the wiki and by Dirk Riehle.
Data Transfer Object
Data Transfer Object or DTO is a (anti) pattern introduced with EJB. Instead of performing many remote calls on EJBs, the idea was to encapsulate data in a value object that could be transfered over the network: a Data Transfer Object. Wikipedia has a decent definition of Data Transfer Object:
Data transfer object (DTO), formerly known as value objects or VO, is a design pattern used to transfer data between software application subsystems. DTOs are often used in conjunction with data access objects to retrieve data from a database.
The difference between data transfer objects and business objects or data access objects is that a DTO does not have any behaviour except for storage and retrieval of its own data (accessors and mutators).
In a traditional EJB architecture, DTOs serve dual purposes: first, they work around the problem that entity beans are not serializable; second, they implicitly define an assembly phase where all data to be used by the view is fetched and marshalled into the DTOs before returning control to the presentation tier.
So, for many people, DTOs and VOs are the same thing (but Fowler uses VOs to mean something else as we saw). Most of time, they follow the JavaBeans conventions and are thus JavaBeans too. And all are POJOs.
출처 - http://stackoverflow.com/questions/1612334/difference-between-dto-vo-pojo-javabeans
등록일 : 2008년 08월 25일 조회수 : 2,305

저자 : Tony Hillerson
역자 : 이대엽
원문 : Anatomy of an Enterprise Flex RIA Part 10: DTOs or Vos
지난 기사에서는 애플리케이션에서 엔티티를 영속화하기 위한 액션 스크립트 코드와 자바 코드를 살펴보았다. 이번에는 그러한 엔티티들을 생성, 갱신, 삭제하는 코드가 들어 있는 서비스 계층을 살펴볼 것이다.
DTO냐 VO냐?
데이터가 포함된 객체를 한 시스템에서 다른 시스템으로 전달하는 작업을 처리하는 전통적인 엔터프라이즈 패턴은 데이터 전송 객체(DTO; Data Transfer Object, 종종 Value Object나 VO라 불리기도 한다)이다. 간혹 우리가 필요로 하는 것 보다 더 많은 양의 코드가 객체에 필요한 데이터를 데이터베이스에서 가져와 보다 경량 객체인 DTO로 들어간 다음 해당 객체가 필요할 때 전송되는데 사용되기도 한다. 이 경우 EJB 3.0이 데이터베이스에서 데이터를 가져오고 집어넣는 것에 관한 모든 일을 대신 해준다. 엔티티(entity)는 데이터베이스 테이블과의 매핑을 정의하고 전송과 조작을 위해 데이터를 유지할 책임을 이행한다.
한 가지 알아둘 것은 대부분의 엔터프라이즈 자바 진영에서는 DTO를 표준으로 삼고 있지만 Cairngorm 프로젝트에서는 DTO 대신 대부분 VO를 사용할 것이라는 점이다. 사실 DTO와 VO 모두 같은 것을 의미한다.
세션 빈
엔티티 빈(entity bean)과 더불어 세션 빈(session bean)은 서비스를 제공하고 비즈니스 프로세스를 관리하기 위해 EJB 3.0에서 구체화한 클래스의 한 타입이다. 물론 이러한 프로세스의 중심에는 비즈니스 로직에 중요한 엔티티가 자리잡고 있다. 세션 빈은 두 가지 종류로 나뉘는데 상태 유지 세션 빈(stateful session bean)과 상태가 없는 세션 빈(stateless session bean)이 있다. 상태 유지 세션 빈에는 여러 요청(request)에 걸쳐 한 요청에서 다른 요청까지 "대화상태(conversational state)"를 유지하는 세션의 개념이 포함되어 있다. 간단히 말해서 대화상태는 빈의 수명 동안 빈과 상호작용하는 클라이언트에 관한 모든 중요한 정보를 말한다. JBOSS와 같은 EJB 컨테이너는 빈의 이전 클라이언트에서 발생하는 다음 호출에 대해 빈이 대비할 수 있게 한다.
예제 애플리케이션에서는 대개 다는 아니더라도 RIA에서는 빈이 사용자의 상태를 추적할 필요는 없다. 일반적으로 상태는 RIA를 통해 클라이언트에 유지되는데, 이것은 클라이언트가 메모리상에 머무르면서 단순 웹 페이지처럼 요청-응답 주기에 제약을 받지 않기 때문이다. 그러므로 세션은 상태 유지 세션 빈과 동일하지만 어떠한 상태도 유지하는 않는 상태가 없는 빈을 통해 한 번에 하나의 요청으로 처리될 것이다. 상태 유지 빈은 엔티티에 대해 데이터 접근 객체(DAO, Data Access Object)와 같은 역할을 수행할 것이다. 이는 상태 유지 빈에서 객체를 데이터베이스에 넣고 가져 온다는 것을 의미하며 그런 점에서 상태 유지 빈은 비즈니스 로직을 책임지게 될 것이다.
아래는 상태가 없는 세션 빈을 생성하는 문법이다:
@Stateless
@Local(value={BookDAO.class})
public class BookDAOBean implements BookDAO {
}
엔티티 빈에 @Entity을 지정하는 것처럼 @Stateless와 대응되는 @Stateful은 클래스를 세션 빈으로 표시한다. 그렇지만 한 가지 또 다른 요구사항은 해당 빈에서 서로 다른 요청에 대해 어느 메소드가 노출되어야 하는지를 컨테이너에 알려주는 인터페이스를 구현하는 것이다. 이러한 요청은 빈은 여러 서버에 걸쳐 배포될 수 있기 때문에 로컬이나 원격에서 수행될 수 있다. 빈은 각기 서로 다른 요청 타입에 어느 메소드를 사용할 수 있는지를 표시하는 하나 이상의 인터페이스를 포함할 수 있다. 우리는 로컬 접근에 대해서만 노출할 필요가 있으므로 어느 클래스의 로컬 인터페이스에 @Local 어노테이션이 지정되어 있는지를 컨테이너에 알려줄 것이다. 아래는 그러한 인터페이스를 보여준다:package lcds.examples.bookie.dao;
...
public interface BookDAO {
public void persist(Book transientInstance);
public void remove(Book persistentInstance);
public Book merge(Book detachedInstance);
public Book findById(int id);
public List getAll();
public List findByAuthor(Person author);
public List findBySubject(Subject subject);
public Collection findByName(String title);
public void removeDetached(Book detachedInstance);
}
위 코드는 모두 하나의 책이나 책 모음에 대해 수행할 수 있는 것을 나열한 것이다. 아래는 책에 대한 세션 빈을 코드로 작성한 것이다:package lcds.examples.bookie.dao.beans;
@Stateless
@Local(value={BookDAO.class})
public class BookDAOBean implements BookDAO {
@PersistenceContext
private EntityManager entityManager;
public void persist(Book transientInstance) {
try {
entityManager.persist(transientInstance);
} catch (RuntimeException re) {
throw re;
}
}
public void remove(Book persistentInstance) {
try {
entityManager.remove(persistentInstance);
} catch (RuntimeException re) {
throw re;
}
}
위의 두 persist와 remove 메소드는 책 클래스의 인스턴스를 인자로 받아들인다. persist 메소드는 아직 데이터베이스에 존재하지 않는 엔티티에 대해 호출되어야 하며, remove 메소드는 데이터베이스에서 엔티티를 삭제할 것이다. 이 두 메소드는 같은 이름을 가진 EntityManager 타입의 객체에 들어있는 메소드를 호출한다. 그렇지만 주의할 점은 그 객체는 결코 인스턴스화되지 않는다는 것이다. 그 대신 EntityManager에는 @PersistenceContext 어노테이션이 지정되어 있다. 이것은 세션 빈이 EJB 3.0에서 어떻게 처리되는지를 일부 보여준다. EntityManager는 런타임에 인스턴스화되며 컨테이너는 현재 빈이 실행되고 있는 영속화 컨텍스트(persistence context)와 일치하는 EntityManager 인스턴스를 해당 세션 빈에 넘겨준다. 만약 하나 이상의 인스턴스가 존재하면 어노테이션에 원하는 것을 지정할 수도 있지만, 예제에서는 영속화 컨텍스트가 단순히 하나의 영속화 단위이므로 예제의 영속화 단위에 들어있는 빈은 모두 동일한 엔티티 관리자를 획득하게 된다. 이렇게 컨테이너가 객체에서 필요로 하는 객체의 알맞은 인스턴스를 부여하는 과정을 의존성 주입(dependency injection)이라 한다. 엔티티 관리자는 런타임에 세션 빈에 주입된다. 컨테이너가 적절한 방법으로 엔티티 관리자를 인스턴스화기 때문에 우리는 코드에서 그것을 어떻게 이루어지는 알 필요가 없는데, 이것은 우리가 코드를 작성하는 동안에는 알고 싶지 않은 일들이 있을 수도 있기 때문이다. 이제 몇 가지 메소드를 더 살펴 봄으로써 각 엔티티에 대해 다른 빈에서 수행할 연산의 유형을 확인해 보자:
public Book merge(Book detachedInstance) {
try {
Book result =
entityManager.merge(detachedInstance);
return result;
} catch (RuntimeException re) {
throw re;
}
}
public void removeDetached(Book detachedInstance) {
remove(merge(detachedInstance));
}
persist와 remove 메소드는 기본적으로 SQL의 insert와 delete 문에 매핑된다. merge는 두 가지 경우에 사용될 수 있다. 첫 번째 경우는 직접적으로 SQL의 update문에 해당되는 것인데, merge는 엔티티로부터 변경 내역을 받아들여 데이터베이스를 갱신하기 위해 대기열(queue)에 해당 변경 내역을 추가한다. 그런데 EJB에는 EntityManager에 의해 관리되는 엔티티의 개념이 포함되어 있다. 엔티티 관리자의 remove 메소드가 호출되었을 때 실제로 일어나는 일은 엔티티가 해당 엔티티를 데이터베이스에서 제거하기 위해 대기열에 추가한 관리자에서 제거되는 것이다. 그러나 그 객체는 여전히 존재할 수도 있는데, 코드에서 그 객체를 참조하고 있을 수도 있기 때문이다. 또한 그 객체에 merge를 수행하여 엔티티 관리자로 되돌려 보내는 것도 가능하다. 이 경우는 준영속(detached) 상태에 있는 엔티티와 엔티티 관리자에 의해 관리되는 엔티티의 차이점을 보여준다. 그럼 준영속 상태에 있는 엔티티에 대해 persist와 merge 메소드를 호출하는 것에는 어떤 차이가 있을까? 사실 아무런 차이가 없다. 두 경우 모두 객체가 존재하지 않는다면 삽입될 것이다. persist 메소드는 엔티티가 이미 데이터베이스 형태로 존재한다면 문제를 겪을 것이나, merge는 그렇지 않을 것이다.
우리는 종종 데이터베이스에서 개체 관리자로 보내지 않았을 지도 모를 객체를 클라이언트 측에서 보낼 것이므로 만일의 경우에 대비해서 새로운 객체와 기존 객체를 갱신하기 위해 merge 메소드를 상당히 자주 호출할 것이다. 이는 내가 removeDetached 메소드를 작성한 이유를 설명해 주기도 한다. 즉 가끔씩 우리는 미처 엔티티 관리자로 로딩되지 않은 객체를 삭제하고 싶을 수도 있으며, 우리가 그러한 과정을 더 복잡하게 만들지 않는 한 그것을 알지 못할 것이다. 만약 준영속 상태에 있는 엔티티를 제거하려 한다면 엔티티 관리자는 이 객체를 알지 못하므로 오류가 발생될 것이다. 이러한 경우에는 먼저 객체를 merge하여 엔티티 관리자에서 관리하게 한 다음 제거하는 것이 더 쉽다.
public Book findById(int id) {
try {
Book instance = entityManager.find(Book.class, id);
return instance;
} catch (RuntimeException re) {
throw re;
}
}
public List getAll() {
Query q = entityManager.createQuery(
"from Book b" +
" order by b.title"
);
List results = q.getResultList();
return results;
}
public List findByAuthor(Person author) {
Query q = entityManager.createQuery(
"from Book b" +
" where b.author.id = :author_id"
);
q.setParameter("author_id", author.getId());
List results = q.getResultList();
return results;
}
필자는 위 코드에 세션 빈을 어떻게 다룰 지에 대한 예제에서 했던 것과 같이 메소드를 몇 개 더 추가하였다. findById 메소드는 개체 관리자의 find(Class, int) 메소드를 호출한다. 이 메소드는 주어진 클래스가 어디에 매핑되는지를 확인한 다음 ID와 일치하는 행을 찾아온다. 간단하다. getAll 메소드에서는 질의를 사용하고 있다. 질의는 개체 관리자에서 생성되며, EJB에서는 표준 질의로 SQL 대신 EJBQL을 사용한다. EJBQL은 SQL과 거의 흡사하지만, 여러분은 EJBQL을 이용하여 테이블 대신 클래스를, 컬럼 대신 프로퍼티를 참조할 수 있다. 질의의 결과는 손쉽게 리스트로 변환된다.
findByAuthor 메소드는 EJB 3.0의 또 다른 질의 기능을 보여준다. SQL와 마찬가지로 EJBQL에도 where 절이 있다. 알아둘 점은 where절의 문법에서 :<매개변수명>의 형식으로 네임드 파라미터(named parameters)를 지정할 수 있다는 것이다. 위 라인에서 우리는 질의를 생성한 다음 setParameter 메소드를 호출하여 저자의 ID를 매개변수로 지정했으므로 질의는 특정한 저자 ID를 가진 책을 모두 찾을 것이다.
[그림 13]은 데이터 프로젝트의 나머지 세션 빈을 보여준다.
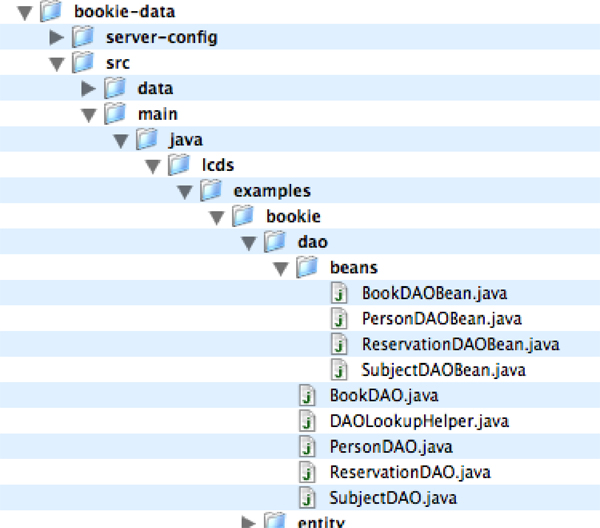
[그림 13] 데이터 프로젝트의 나머지 세션 빈
다음 연재에서는 TestNG를 이용하여 애플리케이션에서 자바로 작성되어 있는 부분을 테스트하는 것에 관해 살펴볼 것이다. 여기를 클릭하면 전체 시리즈(영문)를 볼 수 있다.
출처 - http://www.hanb.co.kr/network/view.html?bi_id=1554
보내는 식의 처리를 해주는것이고 이러한 사용 패턴을 세분화해서 말하는것 같습니다.
출처 - 네이버지식
'Development > Java' 카테고리의 다른 글
| 패키지 이름 정의 (0) | 2012.03.18 |
|---|---|
| 인터페이스(interface) (0) | 2012.03.18 |
| Thread pool (0) | 2012.03.16 |
| java 어노테이션(Annotation) (0) | 2012.03.14 |
| JVM 인코딩 설정(Dfile.encoding 옵션) (0) | 2012.03.13 |





